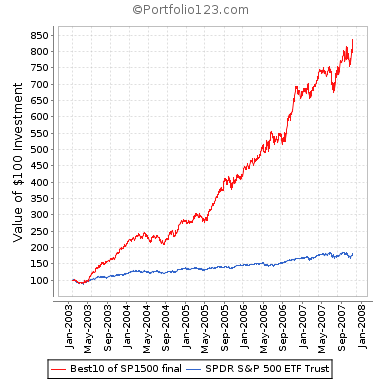
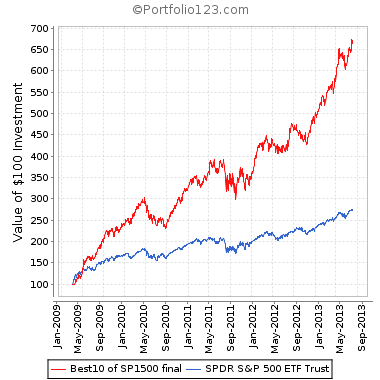
This is one of the best threads I’ve seen in P123 in a long time. It is sure to have the greatest impact to a number of subscriber’s out-of-sample (ie real) profitability. Thanks for your analysis and kickoff Tom!
In light of this thread, I want to push forward (again - sorry) a key feature that we all desperately need, especially with the introduction of R2G and in light of Tom’s eloquent presentation of data mining risks:
https://www.portfolio123.com/vote.jsp?poll=888
Feature N: Convert Ports to ETFs.
Imagine if you could track ports like etfs/stocks. Imagine if you can rank these ETF-ized ports based on # buy/sell rules, #elements ranked (without exposing rules/ranking elements), port volatility, port trendiness, port correlation to a benchmark/each other, the valuation of the ports (Hi vs low PE, PB, PS), across each other, and to themselves over time (remember the Goldman Sachs study called Quantcentration -search in prior posts if you want to download - BTW they took this study off the internet).
I have to do my ETF-ized analysis of P123 ports off line using Amibroker and the downloaded P123 port equity curves as “ETFs”, and quite frankly have not kept it up due to time constraints. Also, without valuation information (PB, PS, PE, other) it is fairly equivalent to actual ETF equity curve trading. So, consequently, I have found trading ETFs based on simple momentum, volatility and correlation rules (See CXO Advisor for various approaches) to yield low but dependable profits.
I stay plugged into P123 because of the great community discussions, and because I know this product is going in the right direction (hats off to Marco and team).
But I feel that we (I) need to stop looking for holy grail, George Soros/Paul Tutor Jones beating, data mined solutions. I haven’t achieved their fame nor fortune nor track record no matter how good a port(s) I built and traded. And as Tom points out - these fantastic (fantasy?) ports can flame out quickly and flame badly.
True, it appears that some micro cap, low scale solutions may be out there…
Here would be a real cool analysis:
Rank out of sample port performance based on the port number of rules/ranking elements.
Anyone want to put some bets on the result on this analysis? Anyone think of other analyses on ports that would be good to have? We can do them if we have a feature where we track ports like ETFs, along with attributes (mentioned earlier). And we will have a true market edge - at least for awhile…
My interest is in looking at the basics that work, when they work and when they don’t (Tortoriello). I don’t think digging deeper and deeper for that nugget, or nugget combo, is going to work that well.
One last point. A group put a lot of effort in tracking factor/factor combos that did well. A lot of work, and a lot of offine analysis. Imagine storing each combination (they are unlimited, but I think a few dozen key combinations would be telling) as ETFs and simply ranking them over time.
If you agree that we need to ETF-ize our ports, and have insights at the valuation and “complexity” levels, please vote for feature N in the poll.
If you disagree, please share why.
And again Tom, thanks for your eloquent analysis. This is the level of quality that makes this site an incredible value.
Carl