So I know I will get a lot of pushback on this but here goes.
“White’s Reality Check” and Aronson’s methods, in general, attempt to quantify how much a method’s performance (a sim in this case) is due to luck.
The assumption is that when we pick a sim we are picking the best performing sim. And that sim has performed well due to both luck and "predictive power,"using Aronson’s term.
He calls this luck factor the data-mining bias.
I do not think we can ever get away from this. This is because of the data-snooping bias. We read “The Magic Formula,” “What works of Wallstreet,” Fame and French’s Work—not to mention all of the public ranks and sims on P123. When we run our very first sim after joining P123 it can be the result of tens-of-thousands of trials (done by other people). Then we add more of our own trials over the years.
If you take one of your 5-stock sims and zero-out the mean return then it should have no predictive power. But how good can it do just by luck? If you bootstrap the sim and run it 2,000 (or so) times you will find out.
That is the beginning of finding out how much luck there can be in a sim.
Note that I said “can be.” I do believe may of the tests for overfitting reduce this. Yuval (testing 100-150 stocks), Denny (even odd) and other posts are very important. I agree: MAYBE THE DATA-MINING BIAS CAN EVEN BE REMOVED. I have some additional ideas on this. I will probably agree with other peoples ideas on this.
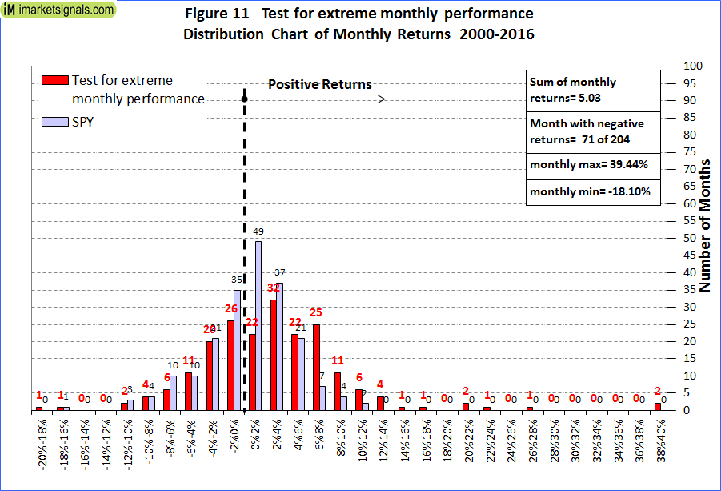
That having been said: a simplified “White’s Reality Check” suggests to me that as much as 35% annualized return in a sim is possible just by luck. This is based on the FACT that you can run 2,000 5-stock sims and have one of them return 35% annualized: on average. Even if the return is zeroed out and you know it has no predictive power. Now, if you do better than 35% you may be on to something. Just do not expect it to do as well as the backtest going forward. And if you really do a lot of checking—like looking at the entire rank performance and the above ideas on preventing overfitting—maybe you can get by if your sim does less than 35% annualized. Maybe.
And, of course, out-of-sample results change the numbers on this: especially if you are looking at your own ports which will be a limited number of ports that are not cherry-picked and do not have a large survivorship bias.
But even if you have chosen a perfect port with 100% predictive power which had no luck at all in the past: that is no guarantee the you will not be unlucky in the future. This addressed this possibility also. Instead of seeing how lucky your sim was in the past, you can get an idea of how unlucky your perfect port might be in the future. Bootstrapping using a 95% confidence interval suggests that a perfect port could underperform by 20% annualized over an 18 year period just because of bad luck. Only someone as unlucky as me would have both happen–pick a lucky sim that turns out be be an unlucky port–but that would be in the range of possibilities.
So even if you have the perfect port, it would be a mistake to dismiss White’s Reality Check entirely.
This is not intended to be negative: just a reality check. After doing this I have many sims and ports that I have confidence in: more that before. I just do not think I will be retiring next year. It could take two or three years;-)
BTW, the R code for bootstrapping is not that hard (or I could not have done it). You will, of course, name your own variables. s is the name of my Excel document in csv format. You would probably download it with read.csv(“directory path to s” header =T), sx is the daily excess log (natural log) returns calculated on the spreadsheet. Make sure to load the boot extension. Adjust the confidence interval as desired (possibly based on your data snooping bias and/or number of sim trials). See if any to this applies to you—assuming it is possible for you to be either luck or unlucky.
summary(s)
attach(s)
simx ← function(sx, d) {return(mean(sx[d]))}
simxx=boot(sx,simx,R=100000)
plot(simxx)
ci = boot.ci(simxx, type=“basic”, conf=0.95)
ci
print(mean(simxx$t[,1]))
More advanced coding doing White’s Reality Check exactly can be found on the web. Maybe even someone like me could cut-and-paste this. But I am so unconvinced that you could ever get a truly exact number that I have not tried it. It is enough, for me, to see that chance can always be a factor—since there is, sadly, no divine inspiration for making money here.
Best of luck!
-Jim