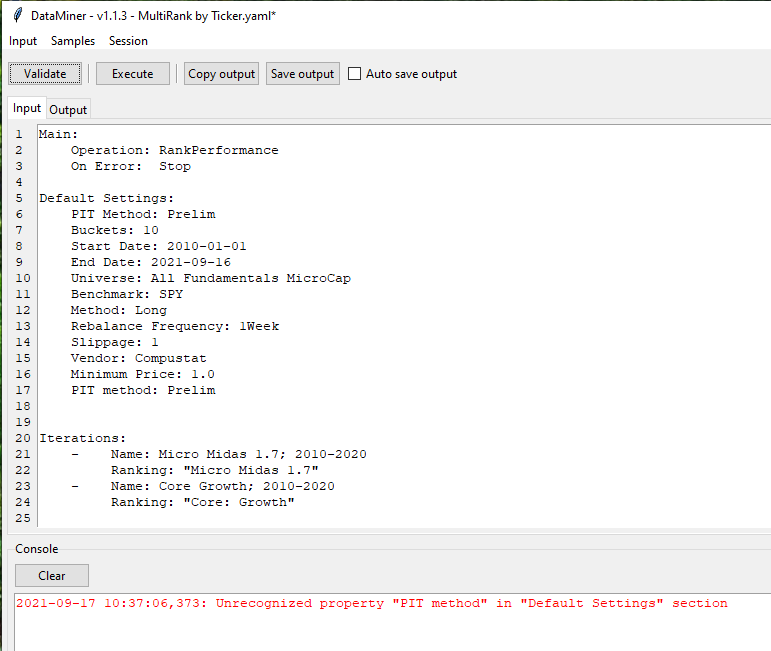
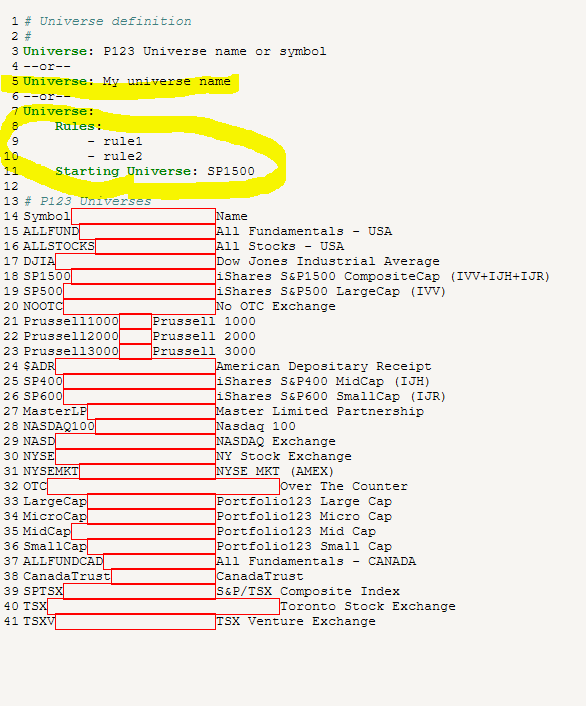
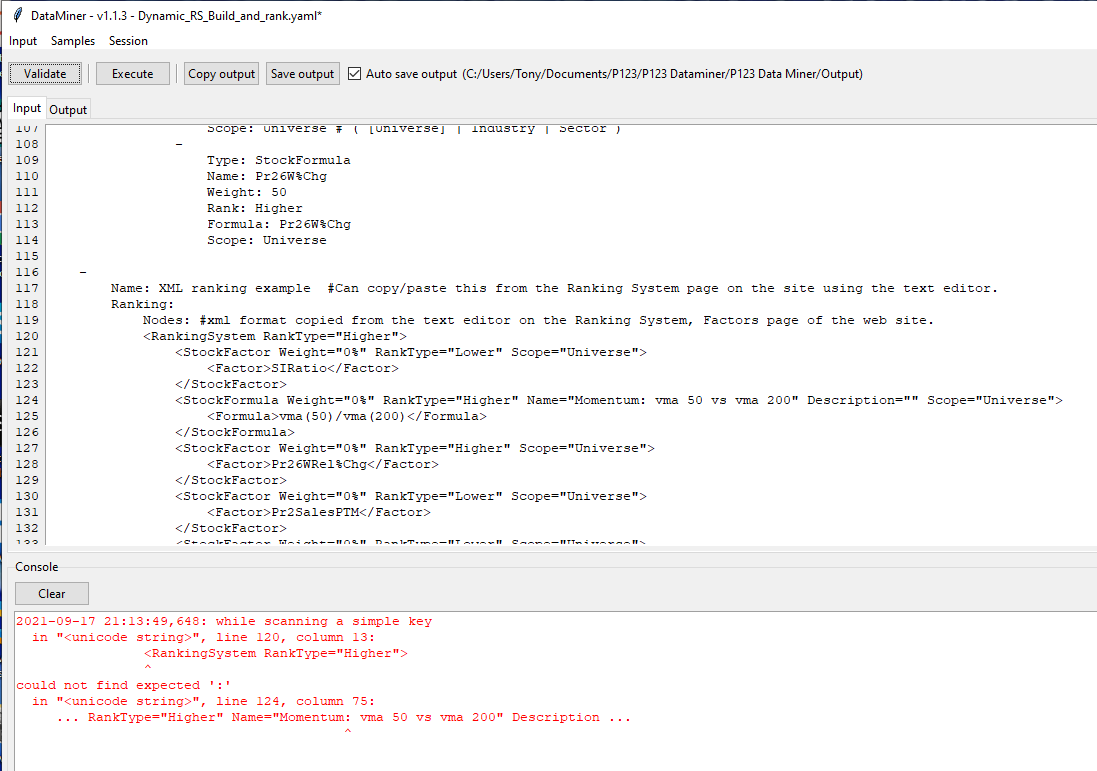
I get this PIT error in data miner.
Am I using it incorrectly?
Thanks
Tony
Hi Tony. You have the PIT Method line twice in the script. My script still runs with 2, but try deleting one of those lines.
Also, do you have a Compustat license? If not, you need to change the Vendor line to Vendor: Factset or just remove it since Factset is the default.
If you still get the error, please try moving the PIT Method line from the first line to another place in the script. I want to see if you get an error related to the new first line in the script - maybe the script is failing and the error message will mention whatever the first line is.
Also, verify that you have the latest DataMiner. You should see v1.1.3 in the top left corner.
If none of those things resolve your error, please let me know any I will recreate your script exactly to find the issue.
Thanks Dan. It works better if I follow the examples accurately. I am using v1.1.3
I do not have Compustat license but I was probing to see what would happen.
One more question. What is the difference between these two universe sections?
I noticed I cannot use my custom universe in the second, larger universe section.
Tony
Starting Universe works like the Starting Universe on the Universes page on the web site. You select the Starting Universe and then whatever rules you add are used to filter the Starting Universe to create a custom universe. There is a limited number of universes available as the Starting Universe and you cannot use your custom universes as you mentioned.
Here is a is a DataMiner example of how to create a custom universe in the script:
Universe:
Rules:
- mktcap < 700
- AvgDailyTot(20) > 200000
- CompleteStmt = 1
Starting Universe: Prussell3000The other option is to create a custom universe on the web site and use that directly in your script like Universe: myUniverse
Thanks Dan.
Is it possible to use the ‘Rank Performance’ operation in data miner but build the RS on the fly using the InLine RS building feature?
I see examples to do one or the other but not both in the same script.
Thanks
Tony
Yes it is possible Tony. I’ll make a cleaner version of the example below and add it to the other examples, but this should be good to answer your question for now.
Main:
Operation: RankPerformance
On Error: Stop
Default Settings:
Vendor: Factset
PIT Method: Prelim
Buckets: 10
Start Date: 2010-11-01
End Date: 2010-12-01
Rebalance Frequency: 1Week
Benchmark: SPY
Minimum Price: 3
Method: Long
Slippage: 0
#Can use an existing universe or create a custom universe inline
# Universe: #SP500
Universe:
Rules:
- mktcap > 50000
- AvgDailyTot(20) > 200000
- CompleteStmt = 1
Starting Universe: Prussell3000
#Could use an existing Ranking system:
# Ranking: "Core: Growth"
#Can use a single factor ranking system defined inline. This is called 'quick rank'.
# Ranking:
# Formula: "PEG"
#Or define a multifactor ranking system inline. This is a short example. The ranking system can have multiple composites or nested composites.
Ranking:
Rank: Higher # ( [Higher] | Lower | Summation )
Method: NAsNegative #( [NAsNegative] | NAsNeutral )
Nodes:
-
Type: Composite
Name: Value Composite
Weight: 100 # ( [0] - 100 where 0 indicates equal weight)
Rank: Higher # ( [Higher] | Lower | Summation )
Nodes:
-
Type: StockFormula
Name: EarnYield
Weight: 50 # ( [0] - 100 where 0 indicates equal weight)
Rank: Higher # ( [Higher] | Lower | Boolean )
Formula: EarnYield
Scope: Universe # ( [Universe] | Industry | Sector )
-
Type: StockFormula
Name: Pr2SalesTTMvsInd
Weight: 50
Rank: Lower
Formula: Pr2SalesTTM
Scope: Industry
#Each iteration will use the settings specified in that iteration instead of the default settings above.
Iterations:
-
Name: Baseline #uses the settings above with no changes.
-
Name: Single factor rank
Ranking:
Formula: EarnYield
-
Name: 2 week rebalance #Test multiple rebalance periods.
Rebalance Frequency: 2Weeks
-
Name: 4 week rebalance
Rebalance Frequency: 4Weeks
-
Name: Univ P3000 #use an existing universe instead of the custom universe defined in the top section.
Universe: Prussell3000
-
Name: Univ mktcap 100-500 #Use a different universe defined inline here.
Universe:
Rules:
- Between(mktcap,100,500)
- AvgDailyTot(20) > 200000
Starting Universe: Prussell3000
-
Name: Univ mktcap 500-1000
Universe:
Rules:
- Between(mktcap,500,1000)
- AvgDailyTot(20) > 200000
Starting Universe: Prussell3000
-
Name: MomentiumValue ranking #Can create a ranking system on the fly here also.
Ranking:
Rank: Higher # ( [Higher] | Lower | Summation )
Method: NAsNegative #( [NAsNegative] | NAsNeutral )
Nodes:
-
Type: Composite
Name: Value Composite
Weight: 100 # ( [0] - 100 where 0 indicates equal weight)
Rank: Higher # ( [Higher] | Lower | Summation )
Nodes:
-
Type: StockFormula
Name: EarnYield
Weight: 50 # ( [0] - 100 where 0 indicates equal weight)
Rank: Higher # ( [Higher] | Lower | Boolean )
Formula: EarnYield
Scope: Universe # ( [Universe] | Industry | Sector )
-
Type: StockFormula
Name: Pr26W%Chg
Weight: 50
Rank: Higher
Formula: Pr26W%Chg
Scope: Universe
-
Name: XML ranking example #Can copy/paste this from the Ranking System page on the site using the text editor.
Ranking:
Nodes: #xml format copied from the text editor on the Ranking System, Factors page of the web site.
<RankingSystem RankType="Higher">
<StockFormula Weight="0%" RankType="Higher" Name="test" Description="" Scope="Universe">
<Formula>eval(InsNetShrPurch>0,InsNetShrPurch/InstitutionalShsNet(0),NA)</Formula>
</StockFormula>
<StockFactor Weight="50%" RankType="Lower" Scope="Universe">
<Factor>Pr26W%Chg</Factor>
</StockFactor>
<StockFactor Weight="50%" RankType="Higher" Scope="Universe">
<Factor>TotRevisions4W</Factor>
</StockFactor>
</RankingSystem>Dan very nice.
Can data miner be called to execute a specific yaml file from the command line?
And. How large of a yaml file can this handle?
If I programmatically built a giant yaml file to tests thousands of iterations, could it handle that?
Tony
Hi Tony,
I am not aware of any capability to run DataMiner from the command line, but I will ask Dev.
If you send me the id for the large ranking system that is giving you the problem, I will figure out what the issue is. The id is the number found in the URL while you are in that ranking system.
Here ya go dan: 387697
Thanks
Tony
Dan, is there a way to pinpoint which XML tag is causing this in RankUpdate.py
I can email the file is that is helpful.
API request failed: Open quote is expected for attribute “Name” associated with an element type “StockFormula”. (on line 1)
EDIT: Dan, it appears that having an “&” in a factor name causes this error.
Thanks
Tony
Dan, I am not sure how many of these bugs you would like to see but…
In the example script: ScreenRun.py
This seems to fail:
from p123api import Client, ClientException
try:
client = p123api.Client(api_id=‘100’, api_key=‘xxxxxxxxxxxxx’) #Insert your API Id and Key
With this error:
except p123api.ClientException as e:
NameError: name ‘p123api’ is not defined
While this succeeds:
import p123api
try:
client = p123api.Client(api_id=‘100’, api_key=‘xxxxxxxxxxxxx’) #Insert your API Id and Key
Regarding the large ranking system and XML - The bug that was fixed today resolved the issues. Below are the steps I used to create a DataMiner script:
Go to the ranking system page and then to the text editor tab.
Copy all the text from the editor into Notepad++ or another editor.
Highlight the text you just pasted and press tab as many times as needed to indent the text so that it will be in the correct column when pasted into the DataMiner script.
Copy the text from Notepad++ to your DataMiner script. Note: this text goes under the “Nodes:” line in the Iterations section.
Some of the formula names in your ranking system have colons in them. That is a special character in Yaml, so we need to either remove those or do this:
Copy the XLM portion of the script into Notepad++ or some other editor.
Escape each double quote (") by replacing each double quote with "
Wrap the entire XML that comes after “Nodes:” in double quotes ie one " at the start and one at the very end.
Handling special characters is explained in the README.TXT file that is in the DataMiner dropbox:
YAML uses a few special characters to format the data: #, :, -, [, ], {, }, ", |, >, + and -. In most cases, the YAML parser is smart enough to handle them, but there could be
rare occasions where these special characters cause a formula to fail. If you should receive an error, you can fix the formula by wrapping the whole property value in double quotes thus explicitly telling the parser that it is dealing with a string. Examples:
For the question regarding running DataMiner from the command line: That is not currently possible.
If you want to only import the Client and ClientException classes, then you need to remove the ‘p123api.’ from the 2 lines below. Like this:
client = Client(api_id=myid, api_key=mykey)
except ClientException as e:
“In the example script: ScreenRun.py” - Is there an API example file somewhere that is using ‘from p123api import Client, ClientException’? If so, could you please let me know where you found it so I can fix it?