Thank you all for your contributions, albeit I see the argument has gotten somewhat out of hand.
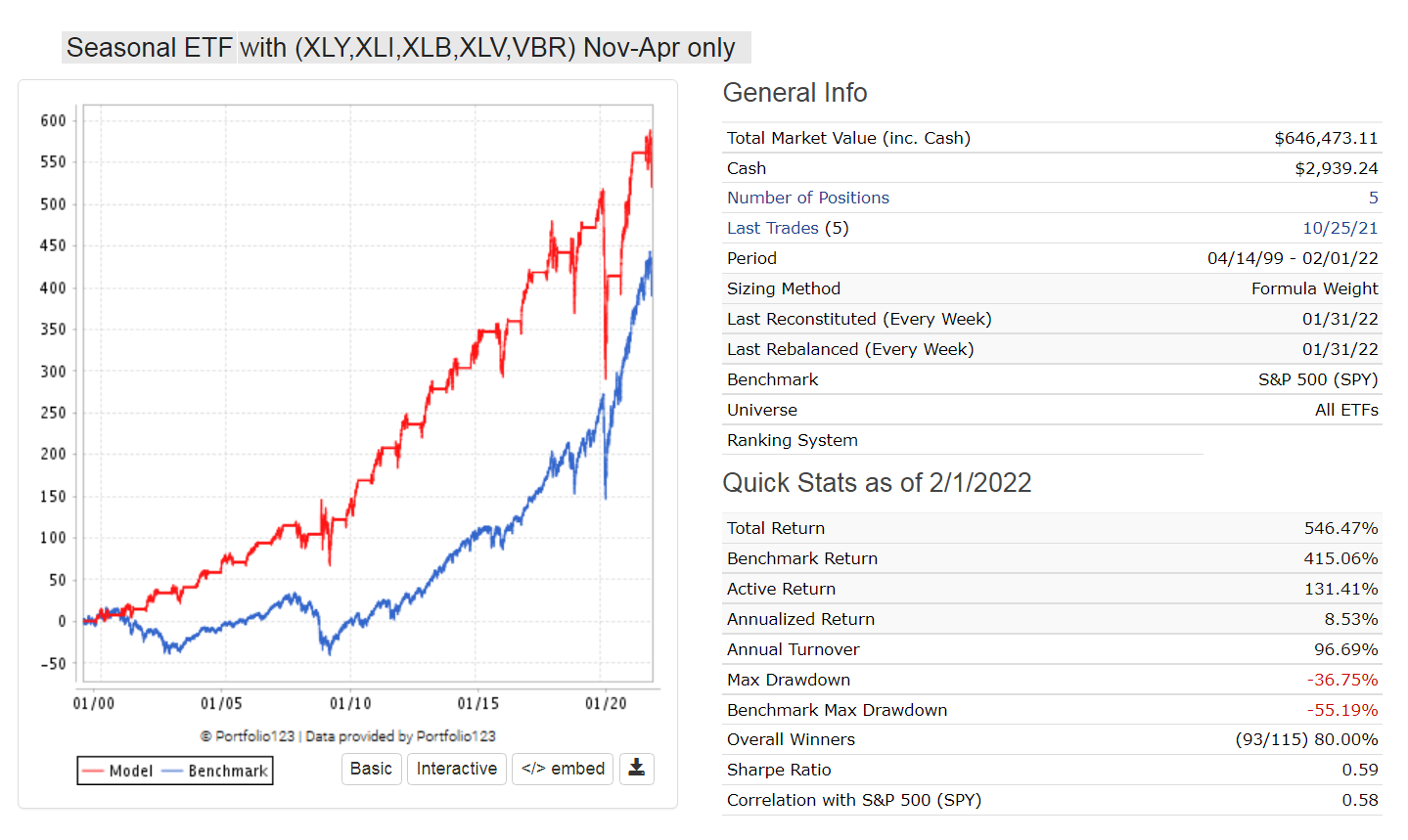
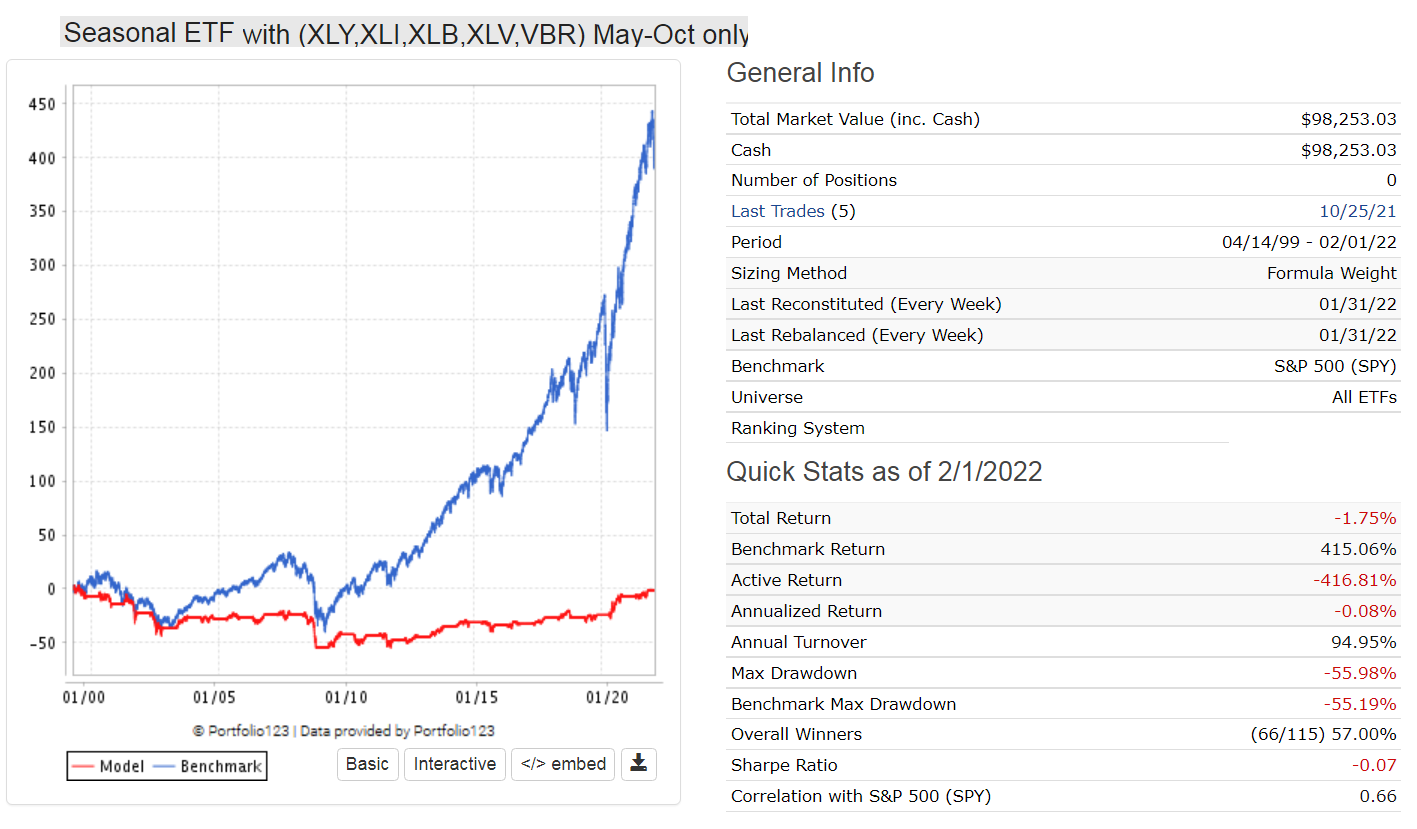
Thank you for linking to the models, Georg, but I, too, am afraid of overfitting, especially in models where I don’t know all of the criteria. Having said that, the seasonal effect (Halloween) on sectors is a well-documented phenomena. So, while I agree that it is not overfitting, you also have some other etf that is unknown to use in a seasonal cycle.
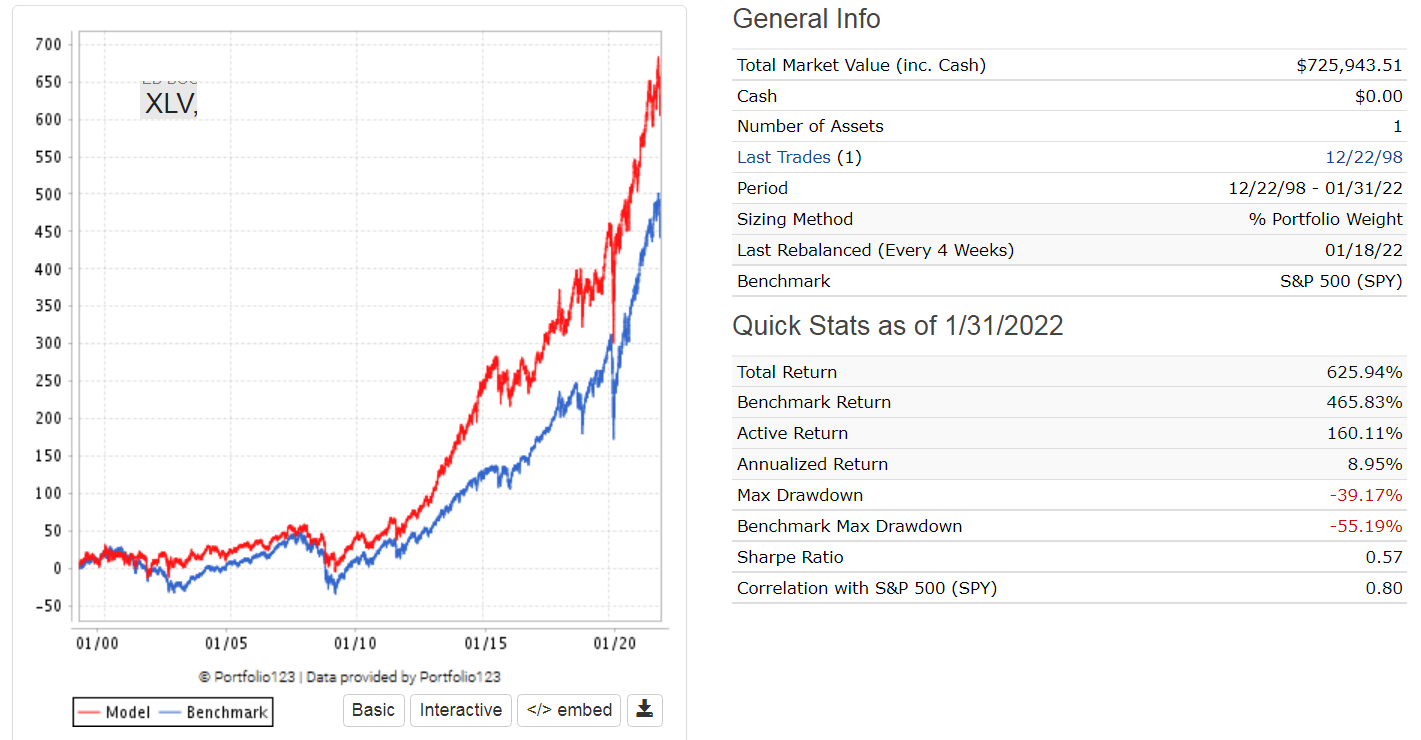
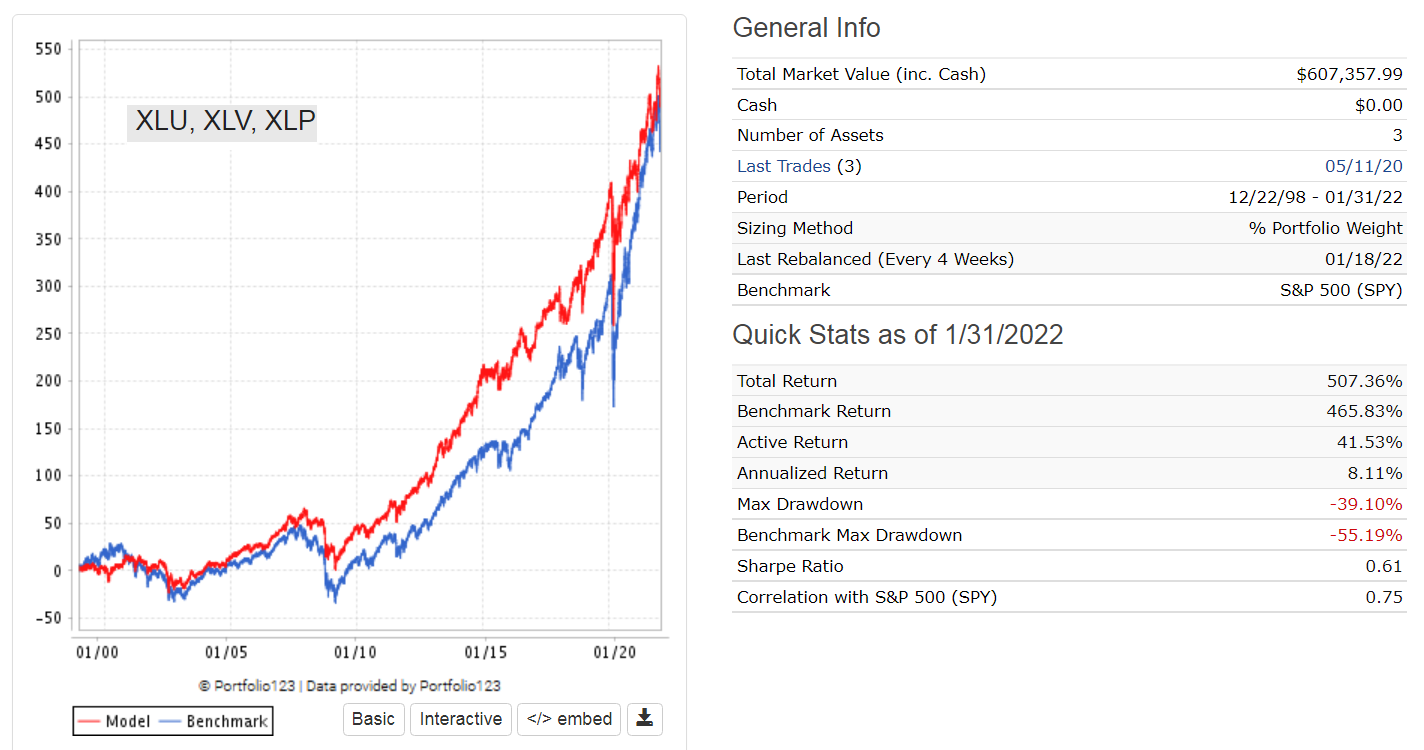
By the way, I’m extremely impressed with your timing model results, and I’ve attempted to understand it. I’m still not sure if it will work out of the backtestperiod. When was this model created?
Jrinne, I agree that a backtest does not always offer much, but it can provide some hints on models that might work. Do you have a link to someone you believe can work and who can be tested on P123?
mv388158, Yes, I attempted to create some of the models in p123. I don’t always get the same results, but I keep on trying.
I don’t want to trade frequently; once a month is about right, and Im not looking for some extreme returns. Its even enough to have the same as the market but but less drawdown. However, I want to use p123 for an asset class rotation portfolio with a specific hedge function for my stock portfolio. So I’m interested in all of the systems offered on p123 that anyone can recommend. Then its possible to altso test them.
For the time being, I’m looking at these models:
https://allocatesmartly.com/livingstons-muscular-portfolios/
https://allocatesmartly.com/financial-mentors-optimum3-strategy/
https://allocatesmartly.com/taa-strategy-accelerating-dual-momentum/
https://www.cxoadvisory.com/momentum-strategy/
A simple take (start) on theese models:
Papabear:
Buy the top tree
Ticker("VWO VNQ EFA VTV VUG IJT DBC IAU TLT ") // papa
ShowVar(@PAPASCORE,ROC(63)+ROC(126)+ROC(252))
CXO Momentum:
Buy the top tree
Ticker(“SHY, TLT, vglt,VNQ, IWM, SPY, GLD, EFA, EEM, DBC voo”) // CXO
ShowVar(@CXO,Roc(84))
Dual Momentum:
Buy the one with highest momentum
Ticker(“scz,voo,sptl,tip”)
ShowVar(@DM,ROC(21)+ROC(63)+ROC(126))
In this model VOO and SCZ has to bee in positive terrain to be bought. If not buy TIP or SPLT with the highest one month momentum
Optimum 3:
Buy 3 of the top 6 based on momentum, but choose the tree that is least correlated
Ticker(“SPY, QQQ, VNQ, REM, IEF, TLT, TIP, VGK, EWJ, SCZ, EEM, RWX, GLD, DBC, BWX”) // O3
My take on the momentum is the same as PAPABear:
ShowVar(@O3,ROC(63)+ROC(126)+ROC(252))
I have no idea how to program the pick of the least correlated tree og the top 6.
CXO: https://www.portfoliovisualizer.com/test-market-timing-model?s=y&coreSatellite=false&timingModel=4&timePeriod=4&startYear=1985&firstMonth=1&endYear=2021&lastMonth=12&calendarAligned=true&includeYTD=false&initialAmount=10000&periodicAdjustment=0&adjustmentAmount=0&inflationAdjusted=true&adjustmentPercentage=0.0&adjustmentFrequency=4&symbols=DBC+EEM+EFA+GLD+IWM+SPY+TLT+VNQ+BIL&singleAbsoluteMomentum=false&volatilityTarget=9.0&downsideVolatility=false&outOfMarketStartMonth=5&outOfMarketEndMonth=10&outOfMarketAssetType=1&movingAverageSignal=1&movingAverageType=1&multipleTimingPeriods=false&periodWeighting=2&windowSize=4&windowSizeInDays=105&movingAverageType2=1&windowSize2=10&windowSizeInDays2=105&excludePreviousMonth=false&normalizeReturns=false&volatilityWindowSize=0&volatilityWindowSizeInDays=0&assetsToHold=3&allocationWeights=1&riskControlType=0&riskWindowSize=10&riskWindowSizeInDays=0&rebalancePeriod=1&separateSignalAsset=false&tradeExecution=0&comparedAllocation=-1&benchmark=VFINX&timingPeriods[0]=5&timingUnits[0]=2&timingWeights[0]=100&timingUnits[1]=2&timingWeights[1]=0&timingUnits[2]=2&timingWeights[2]=0&timingUnits[3]=2&timingWeights[3]=0&timingUnits[4]=2&timingWeights[4]=0&volatilityPeriodUnit=1&volatilityPeriodWeight=0
PAPA: PAPABear
DUAL: DUAL