I agree completely. I do think that XGBoost is a known thing and not really that complex. I do think you could duplicate what they do with with XGBoost (and add some additions methods). Especially if you focus on fundamentals. Or Steve could over at Colab. Or whatever direction is best with that. But getting XGBoost to produce good solid models with fundamental data from P123 can be done.
Just to be clear, the In-Sample/Out-of-Sample example that they give didn’t handle leakage, but maybe there is an explanation of why not if I were to dig deeper. In any case, there are advantages to keeping the data on P123. That part I like. But surely there is a cost for Data Robot that has to be offloaded on to P123 subscribers. And that is probably where you will have a stumbling block.
I have aspirations that go beyond XGBoost. As I mentioned in another thread, I may want to look at creating an AI-based ranking system designer. Think of the possibility of designing RS’s based on least square error instead of the ranking buckets that we currently have. And also employ some of the anti-optimization techniques from XGBoost, just not decision-trees. In other words, I want to keep my options open for how to work with ML/AI and not get locked into a platform that does some stuff well.
I think this is a small thing that FactSet can worry about. There was a portion of the video where the training data preceded the validation data (in time).
This is “causal” for sure. Clearly no look-ahead bias. I get that with a time-series they could do more. Exactly as you say.
I am all for you—over at Colab— fixing this to ensure there is no “data leakage” over at Colab. I understand the issue.
I know you can take care of this over at Colab. It is just a matter of where you slice the data. In fact, I think you have already addressed this.
Now if you and P123 can work on seamless downloads of data to Google Drive we can be up and running with one implementation of this by the weekend;-)
I actually have no problems using Data Robot or other software that Marco digs up. Just be wary that trendiness (Factset using ML) doesn’t imply success. A case in point, Quantopian… It was very popular with almost everybody. But they couldn’t make it work after years of trying. The fact that everybody was using it didn’t mean they were headed in the right direction. Data Robot may be very popular and very professional for the most part. But all it takes is one tiny aspect not handled correctly and you’ve got nothing.
If we can afford DataRobot or P123 can get us access to it then I am ALL FOR IT.
But Steve, I think Marco is just saying he likes what you are doing with XGBoost over at Colab and is getting different ideas on where to go with this (Colab and/or elsewhere).
Marco can clarify but I cannot imagine DataRobot is an option for us. Actually, I hope I am 100%, 180 degrees wrong on whether we could get access to DataRobot.
But Steve, you might declare a victory on this and keep going over there at Colab if I am right. I do not think we can afford DataRobot.
DataRobot is just a cloud service for ML. They help companies use ML, has a seemingly easier, no-code, front end, and they rent out their ML instances for big data. There are many others, and many are getting unicorn valuations . DataRobot valuation is $2.7B , or around 25% of FactSet! This last fact alone is reason enough for p123 to get involved in this.
I doubt DataRobot would even speak to us to do a proper integration (JV) . We’re too small. But you can certainly signup as a user to rent their ML instances using the data from P123 and take advantage of their slick interface and pre-built model blueprints. They offer $500 credit when you signup up. I bet you can do a lot with $500 credit. We don’t generate terabytes of data. Perhaps 1 gigabyte at most. To train a model with a gigabyte of data can’t be that expensive (they have to compete with the many ML cloud services out there).
DataRobot probably can charge a premium because of their front end and their “model blueprints”. For example their blueprint “Light Gradient Boosting on ElasticNet Prediction” has about 30 settings. Things like “subsample_for_bin” “min_child_weight” “min_split_gain” “reg_lambda” “max_delta_step” and so on. You need a data scientist to understand these. But judging from their demo they have reasonable defaults set for FactSet users. So, at the very least, we can use DataRobot to test a lot of these models and default values and just focus on the ones that work well for us. My guess is that each of these model blueprints is based on open source libraries and easily reproduceable elsewhere.
I got some data and spent a few years doing much of that. E.g., XGBoost, Ridge Regression etc.
I am now funding a model using Factor Analysis and going to convert it to XGBoost over the next week or two.
To see several years of work running real-time on multiple processors completed in minutes at most……Still finding the words.
Anyway, I encourage you to keep looking into this and finding the best business model for P123. Not sure I can add anything to the business part of this.
Jim - I think the business model is for P123 to sell data to users and have them run the models with Data Robot. And maybe the next unicorn will be me (not likely). I could use a few extra $billion.
We will see what can be worked out with DataRobot. I will say you do not need it to do XGBoost and adding Ridge Regression or a Random Forest will not help you much.
"But judging from their demo they have reasonable defaults set for FactSet users. So, at the very least, we can use DataRobot to test a lot of these models and default values and just focus on the ones that work well for us. "
Marco - I just want you to know that my tulip python library takes care of all of the (major) parameters for XGBoost. It is not a problem and saves a tremendous amount of evaluation time. I think that the big problem with the code that I gave out was that it was at too high a level and most people can’t appreciate it until they discover how things work at a low level first.
Hi Marco, this is little off-topic I guess - but Factset (FDS) is showing up one of my screens (SP Global SPGI does sometimes too) and I was wondering if you had any general statements about the financial data vendors. Do they really have tremendous pricing leverage over customers, or is it becoming increasingly more competitive? I notice they’re buying up data competitors so it seems like may be a sort of marketshare/monopoly positioning effort going on, but kindof wonder how you see the competitive environment? If you feel free to comment, I appreciate any perspective you can share, either company or industry specific.
I wish it was more competitive. But when you need fundamentals + estimates + industry classification it’s either reuters , s&p or fds. And if you need dead companies keeping everything aligned with prices is a nightmare if you use different vendors. Probably a good trade with flat stock price and earnings coming up. I should have bought their stock long ago for the same reason I bought Comcast. Can’t get away from them.
So I am going to have to give STRONG SUPPORT TO STEVE ON THIS. At least with the data I have so far.
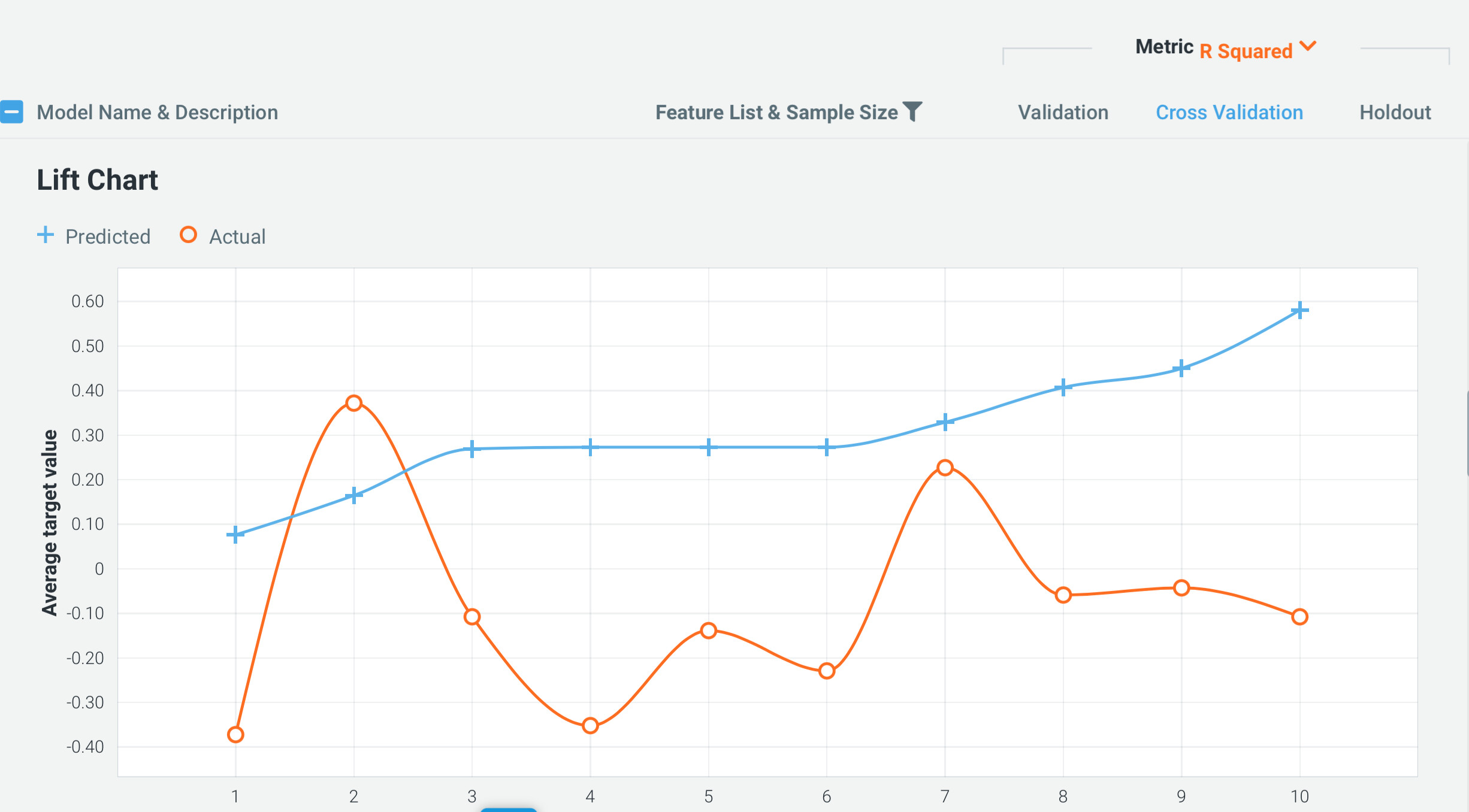
As you may recall I ran some data on JASP which gives me some control of the hyperparameters and that model was predictive of stock returns. The hyperparameters and the results can be found here: Boosting your returns
So I ran the same data on DataRobot and got the image below: boosting was worthless with their hyperparameters. This is their implementation of boosting (XGBoost in particular).
DataRobot runs a lot of models very quickly. It looks like they may optimize the hyperparameters for XGBoost to some extent.
BUT not like Steve does in his Colab program or even what I did with JASP, it seems. I think DataRobot MAY not optimize the hyperparameters like you would want if you were going to put money into a system. May not spend the computer time fully optimizing all of the hyperparameter for the multitude of models that they run so quickly. And some human art can be involved in finding the best hyperparameters.
And some of the ML/AI models cannot be expected to work with rank data (e.g., Ridge Regression). Ridge regression could work well with Z-score when P123 makes that available. But keep in mind ridge regression is about 3 lines of code in Python (once you have downloaded the libraries). 3 lines of code for ridge regression and a few additional lines of code in Scikit-Learn for the cross-validation. I am not claiming every newbie could do it without a little guidance from Steve (and other members), P123 or a combination of both
I need more data on this. I am not done and I do not have a firm conclusion on any of this. This is just one piece of data for me.
But score a point for JASP and some human intervention for now. And a point for what Steve is doing over at Colab.
I will look at this with XGBoost. Take a good long look with better data and a hold-out sample that will not have any potential for data-leakage whatsoever. Take my time getting it right. And also continue to look at this over at DataRobot (as long as my $500 credit holds out). No conclusions for now but I thought I would share some of what I have at this point.
I have had a chance to play with DataRobot a little.
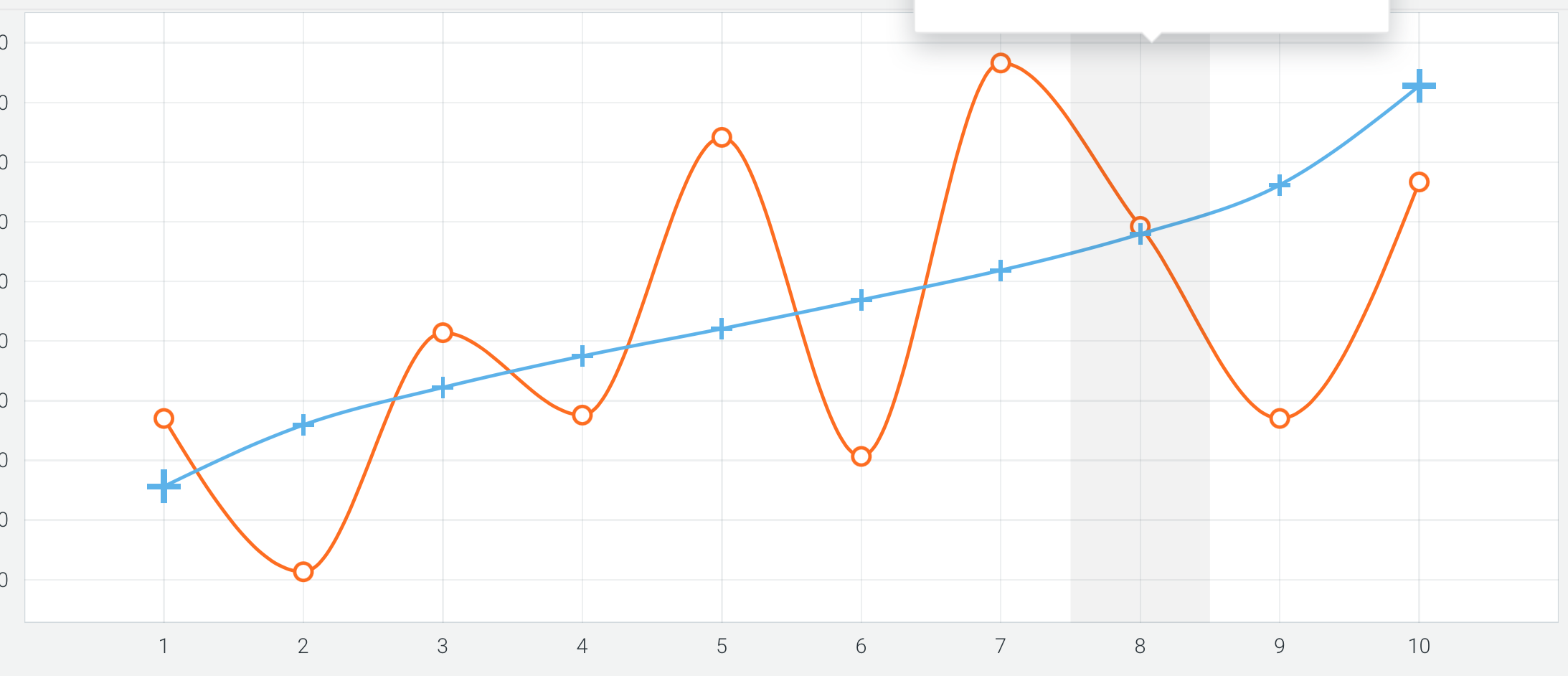
I just wanted to say I have gotten some results that are better than above although not necessarily anything I would invest in or recommend for investing based on the the results below. In fact, the results below as well as what I get in Python (with the same data) is making me inclined to not invest in the strategy. Or if I do to use P123 classic (perhaps with a bit of factor analysis) for this data and these factors.
This is a holdout test set (not validation data).
There is some capacity to change the hyperparameters in the program which I had not found when I wrote the above.
I like the program at this point. I am suspicious about the pricing as I cannot find the pricing anywhere and they have not contacted me yet. Although the fact that I have not burned through my $500 credit yet is a plus I guess.
Marco, I do not know if you are still looking at DataRobot but I did not want to leave an unfair opinion as my last post on this. Still not an expert on DataRobot by any means.
In addition to DataRobot you have mentioned Azure. Steve Auger introduced the forum to Colab. This is in addition to the obvious possible use of Python on a personal computer. (e.g., Jupyter Notebooks).
Now, IBM Watson Studio Cloud is offering some free services. It is perhaps similar to Colab. At least similar in the sense that one can run XGBoost and TensorFlow for free on it (they say). However, I have yet to find a command-prompt on the site after signing up.
For comparison, it was easy for me to find (and use) Colab’s command prompt.
I became aware of this because the new version of Anaconda has this integrated into it (somehow).
FWIW if you are still looking at ways to market P123’s API and its possible use for ML/AI applications.