Marco,
I like your PV ideas. Be aware that there is some look-ahead bias in both of those methods. Keep those (I like them too) but possibly add this following method. This is a “timing-method.” The timing may or may not be useful. But probably many will use the timing, I am guessing.
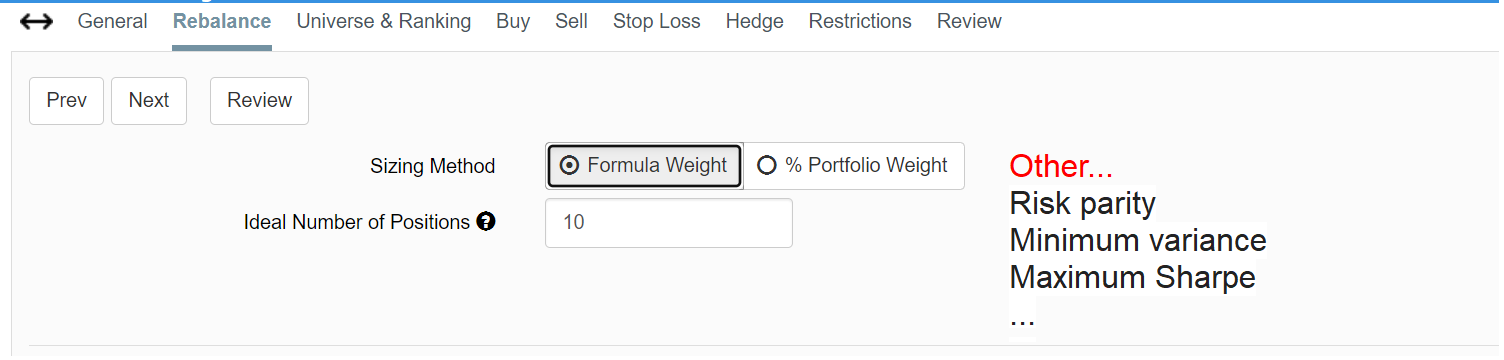
But also it is an example of walk-forward cross-validation. 2 birds with one method. This uses “risk parity.”
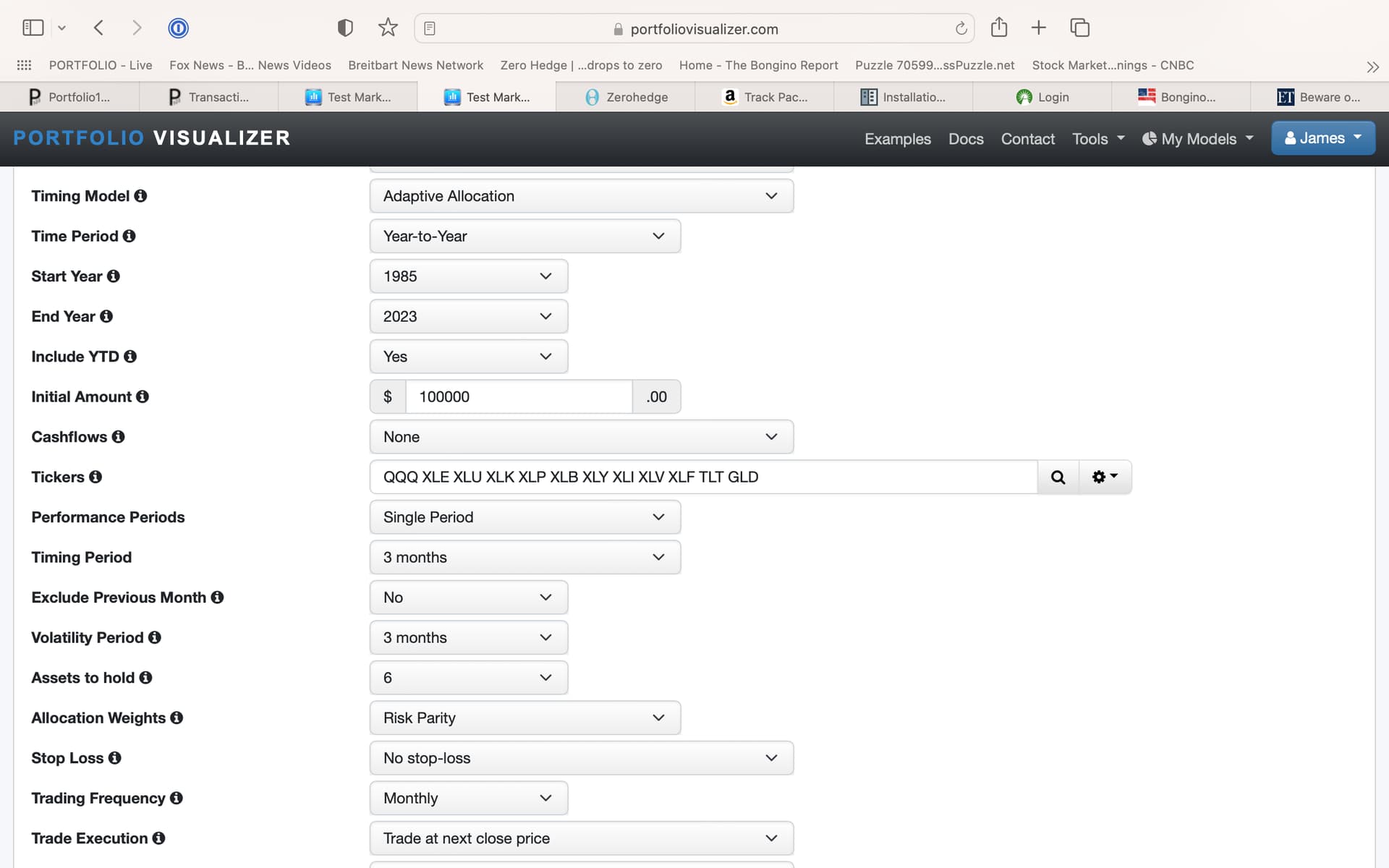
I think I have to use a screenshot in this post as you will not have access to timing models unless you pay for a membership to PV (I think).
But this will look at the last 3 months to determine the holdings of the next month, then walk forward a month (looking at the rolled or ‘walked-forward’ next 3 months) to determine the holding of the following month (data for that month not being used to determine the holdings, repeat,………walk-forward till today). No information for the next month is known or used.
So this is a backtest that does not use any information from the future: unlike what we do at P123.
So just like P123 (except with a walk-forward backtest which has advantages). No look-ahead bias. MUCH LIKE A ROLLING BACKTEST BUT BETTER THAN A ROLLING BACKTEST because there is no look-ahead bias.
Then if you like the backtest just use it as a “PORT.” So same thing as P123.
Note. Yuval was a big fan of Omega for a time. If he still is (I have no information on this) that is available on PV also. But lots for everyone to look at. I do not claim the above is the only addition you may want to look at or even the best.
** But I like walk-forward backtests wherever I find them (including PV or maybe P123 if you end up using this).**
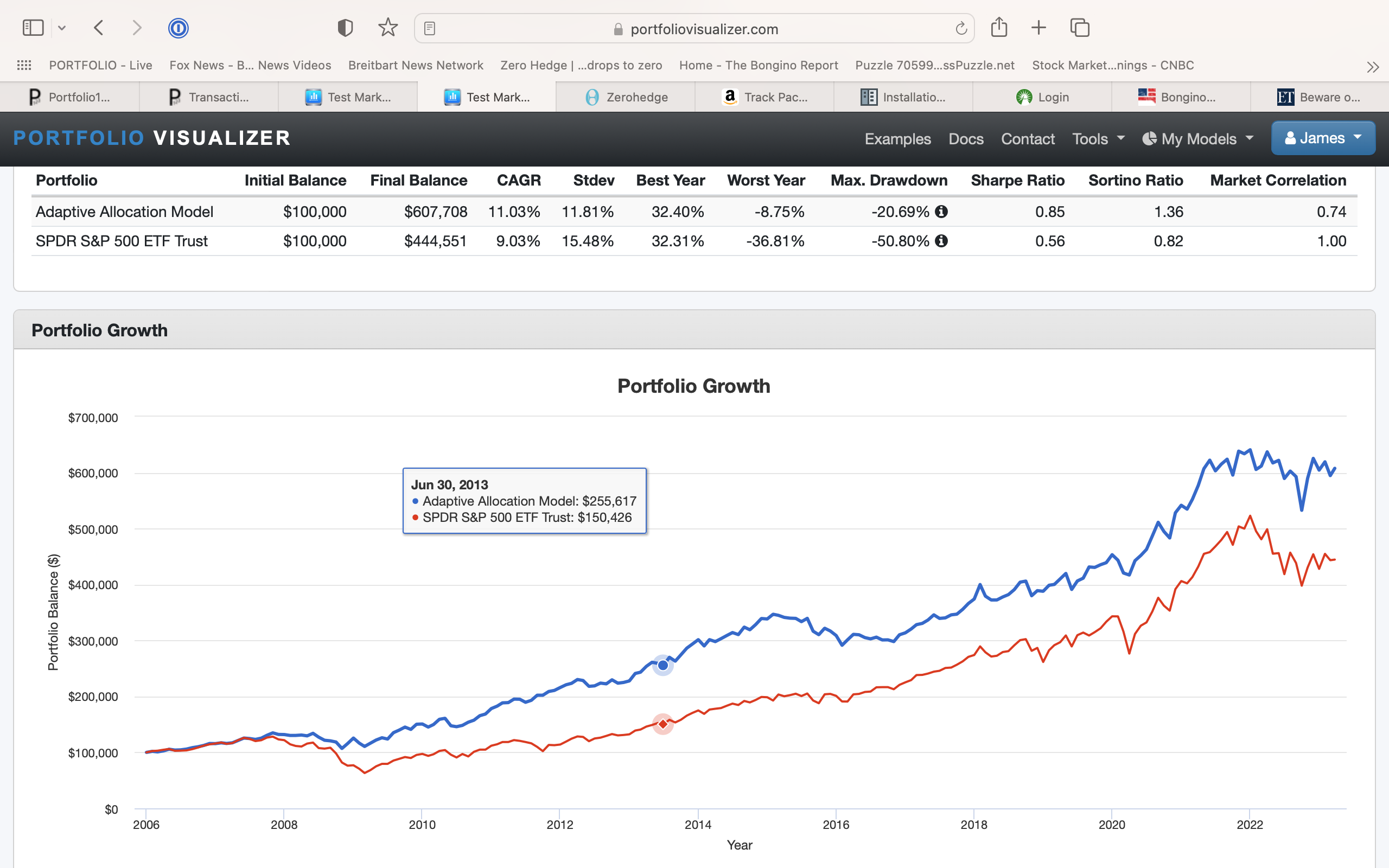
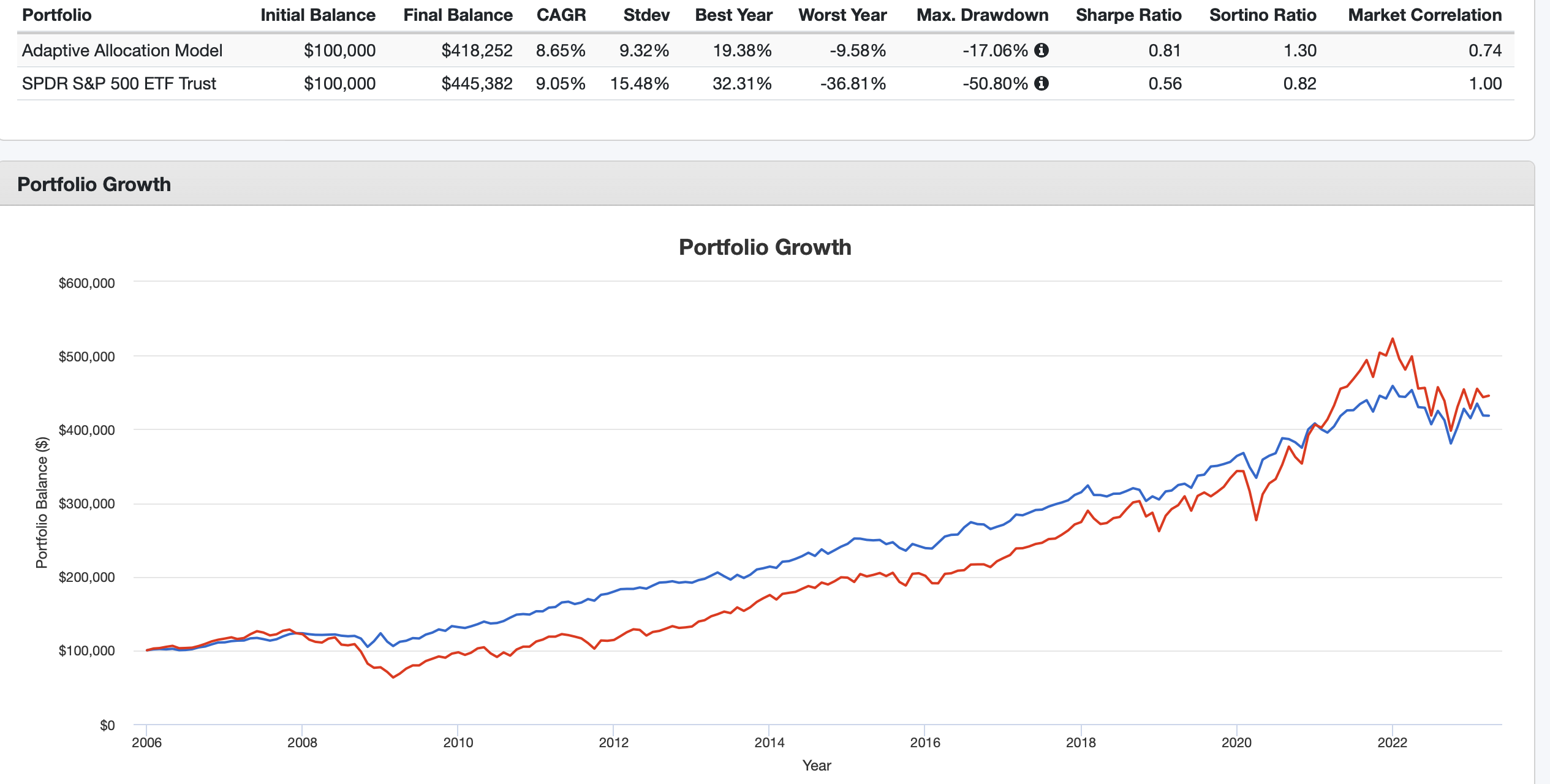
This is meant to be keep generic (just the SPDRs, TLT and GLD). Better returns and less risk by most measures (drawdown and Sharpe). I am sure others can find better models. I am not using, selling or recommending it!!! Anyone welcome to criticize with that in mind (I won’t care).
Even now at PV and especially if P123 staff and members vote to adopt this you can use sims that are uploaded into PV instead of tickers.
Jim
")