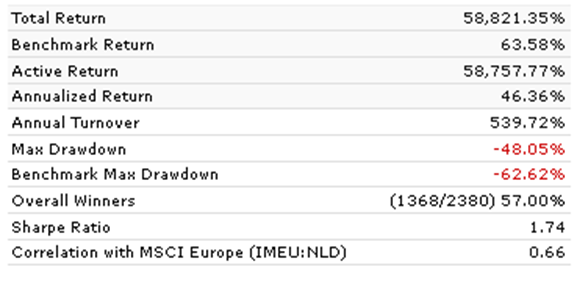
You hope to attract some people who use machine learning techniques with P123’s AI I think.
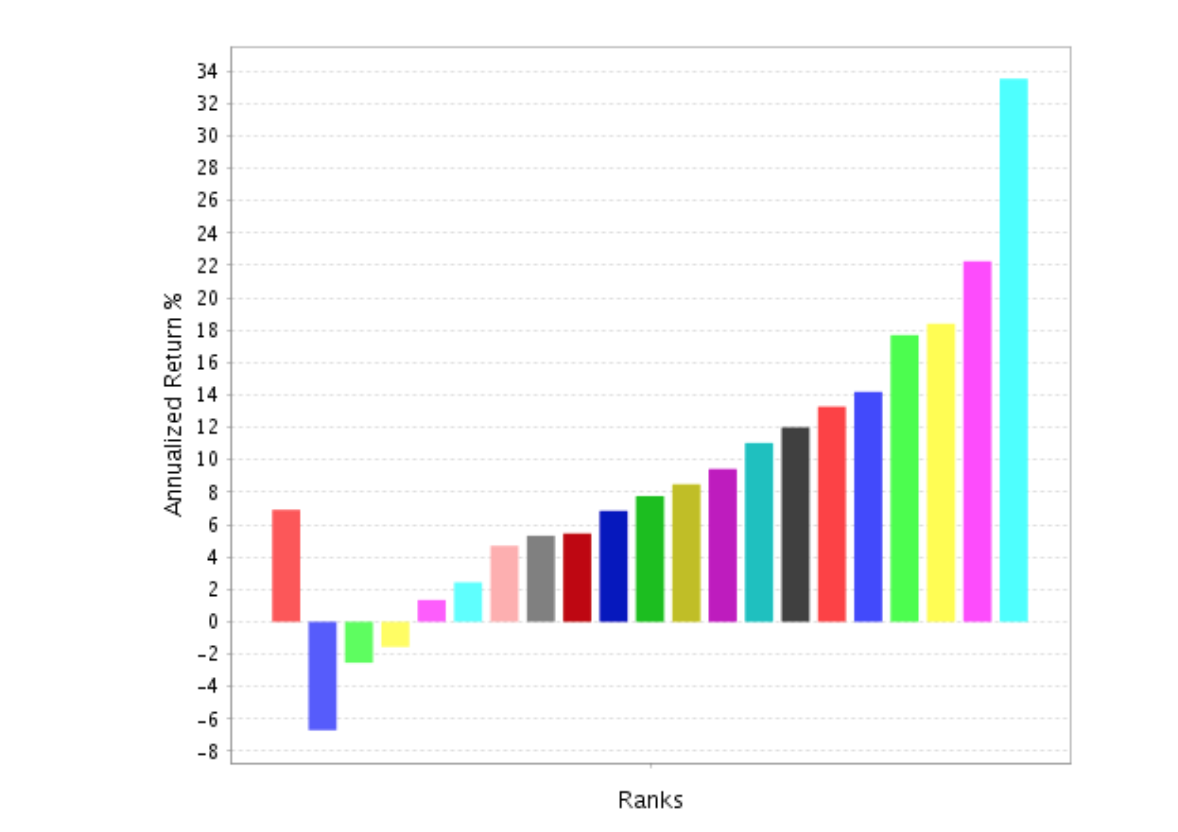
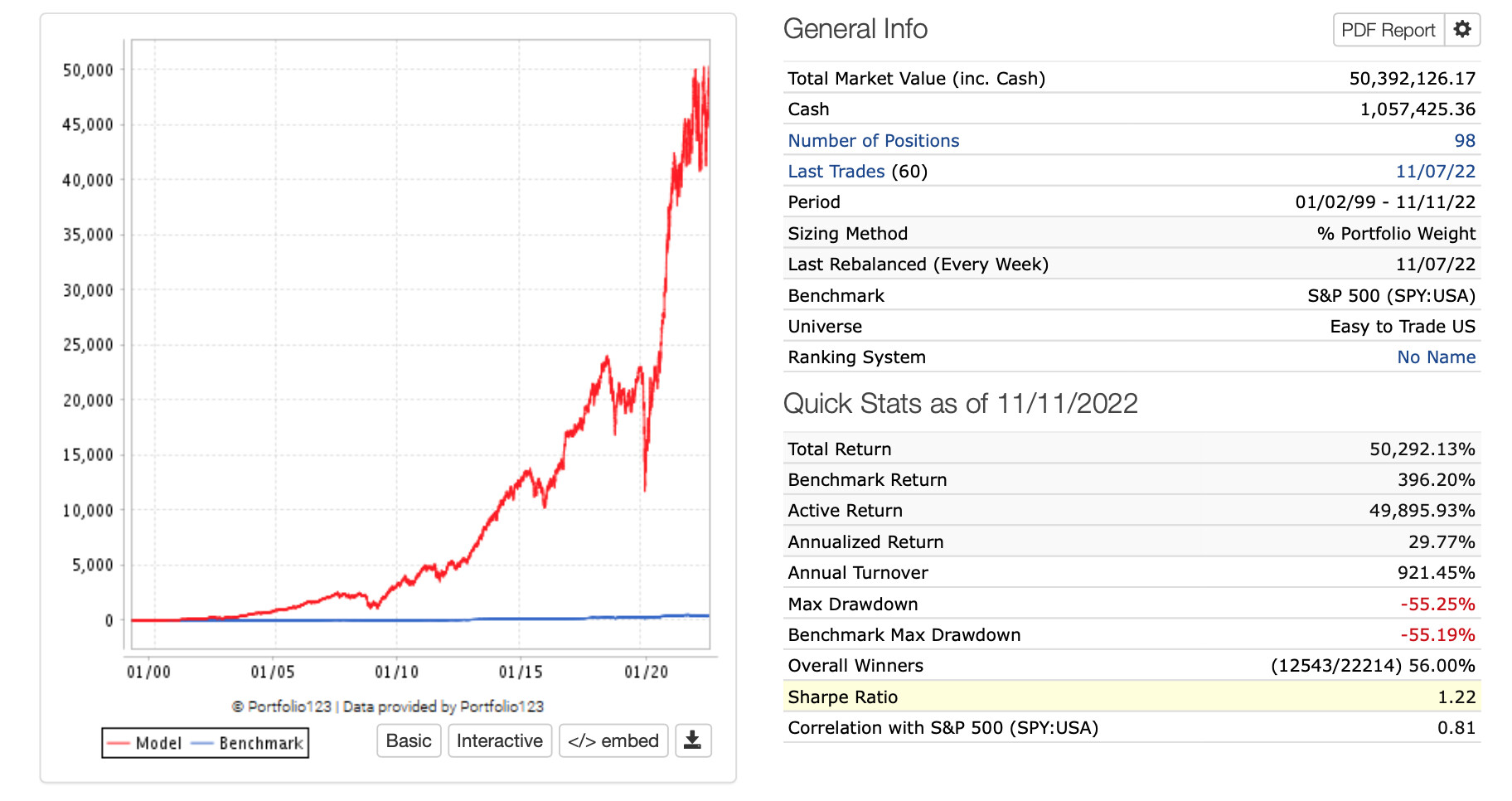
Here is one result of machine learning (using the “Easy to Trade” universe) with a perfect Spearman’s rank correlation of 1 for 20 buckets. Each bucket is higher than the last. The upper bucket could be better I am sure, but not so bad in the scheme of things.
Machine learning did that. And I am sure the men and women at Kaggle can do much, much better.
That should attract some machine learners to P123—shouldn’t it?
Not so fast I think. This is even interesting only to the extent that the data is good (without look-ahead base or information leakage). And “How good is the data?” will be the first question that will be asked by the type of people you want to attract long-term.
So let me be the first to say for anyone reading this that P123’s data is good enough to make money. You can quantitate the details yourself, after signing up.
But I think you might consider working to frame the answer to this question yourself. There are several proactive ways of doing that I think. I am sure I have only thought of a few ways to do that (maybe some of them good).
I will have to think about how much I want to talk about the particulars of my strategies. But generally,……
I think it has been sad at P123. We have people talking about all of these truly great (in my opinion) strategies. Using subsampling of universes sampling of factors averaging of models, correlations of strategies among universes etc.
Then coming out strongly against machine learning. I get that people should be able to self-identify however they wish. If they are not using machine learning then fine.
I think Marco (and rightly so) is not so caught up in the semantics and thinks his computer programing skills can be used to streamline the basic methods already being used at P123. If a few of them coalesce or combine into methods with names like Random Forest he seems okay with than now. Specifically, I am glad that Marco has decided to CONTINUE to develop methods of reinforcement learning on the P123 platform.
Anyway, I think you can develop a P123 ranking system using machine learning. I think people are already doing that and promoting their strategies. For whatever reason they want to call it something different and I have not problem with that.
But I do truly like some of their techniques—whatever they wish to call them. “A rose by any other name……”
But the data has to be good whatever technique one uses. And it is good enough, I think. P123 is fine the way it is but it could market itself better and maybe even clean up the analyst data while it is at it.
You are highly intelligent. And not entirely wrong I think. To the extent that you are right, I am going to have a hard time keeping my secret! It may already be out.
And for the record linear regression—that controversial and radical method we learned about in elementary school that has been around for over 100 years now—is a type of machine learning.
I actually think that linear regression can work but there are multiple ways to get the same answer. And frankly, it has been sad to see people argue over methods that are ultimately equivalent if you step back and look at the underlying ideas.
Pretty rank performance.
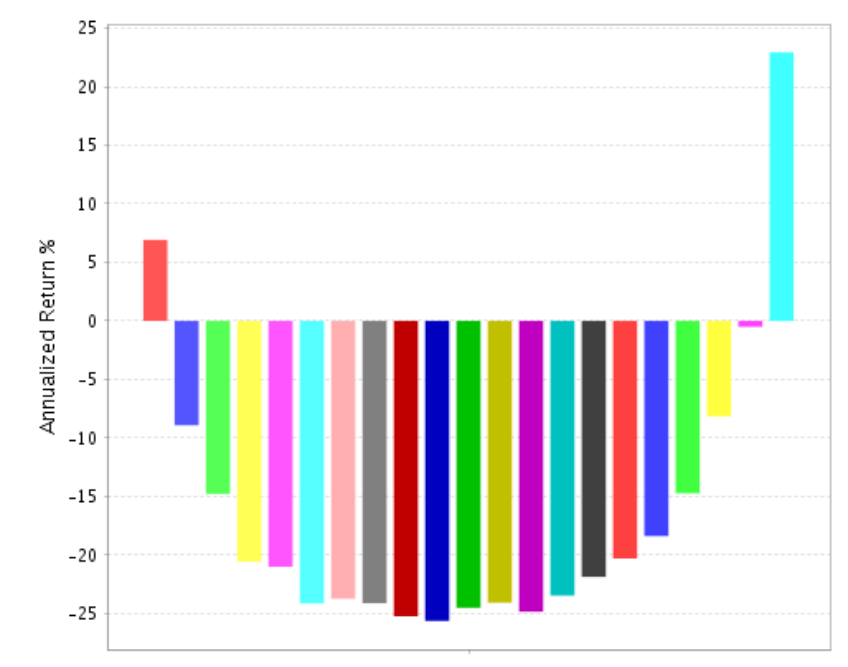
The universe has approx. 4,000 stocks, therefore 5%= 200 positions.
Weekly rebalancing and slippage of 1.3% (lots of small caps among the high performers) then rank performance will look like this:
Thank you for helping to make my point and show how important my point is. I was not sure on your slippage number so I ran 100 stocks (I cannot run 200 with my membership) in a sim with variable slippage (Next Average of Hi-Lo). You are right slippage makes a difference:
So, someone experienced in machine learning (but not necessarily highly experienced with investing) will have to worry about slippage as you point out. Also overfitting (which they know will happen), as well as reversion to the mean for out-of-sample performance (which they know will happen).
And be told on a regular basis in the forum that the analyst data is not PIT (and FactSet’s fundamental data is not PIT either).
You could not have said anything more to make my point clearer. I am only saying I would try to control the narrative on that last point if I could.
One way (other than what Marco has already suggested for making the analyst data more PIT) would be to run a sim alongside every designer model and show that any effect (any difference) is small. Or at least make any uncertainty about the effect of this become a know quantity.
What I am sure about is that many people will need some proof that the efficient market hypothesis can be wrong to a large degree. Wrong enough to compensate for any risks ports and individual stocks pose. And compensate for the cost of P123 membership. Some engineers can be pretty rational—as you know. I am only guessing than many are pretty conservative or not wanting to take a lot of risk with their professional projects (e.g, demand certainty that a structure is not just stable but can withstand significant winds).
Saying it as they might: “I would consider rejecting the null hypothesis (that the efficient market hypothesis is correct) if I did not know from the beginning that the data was flawed. I certainly could not present that to my boss in my day job.”
Hi Jim,
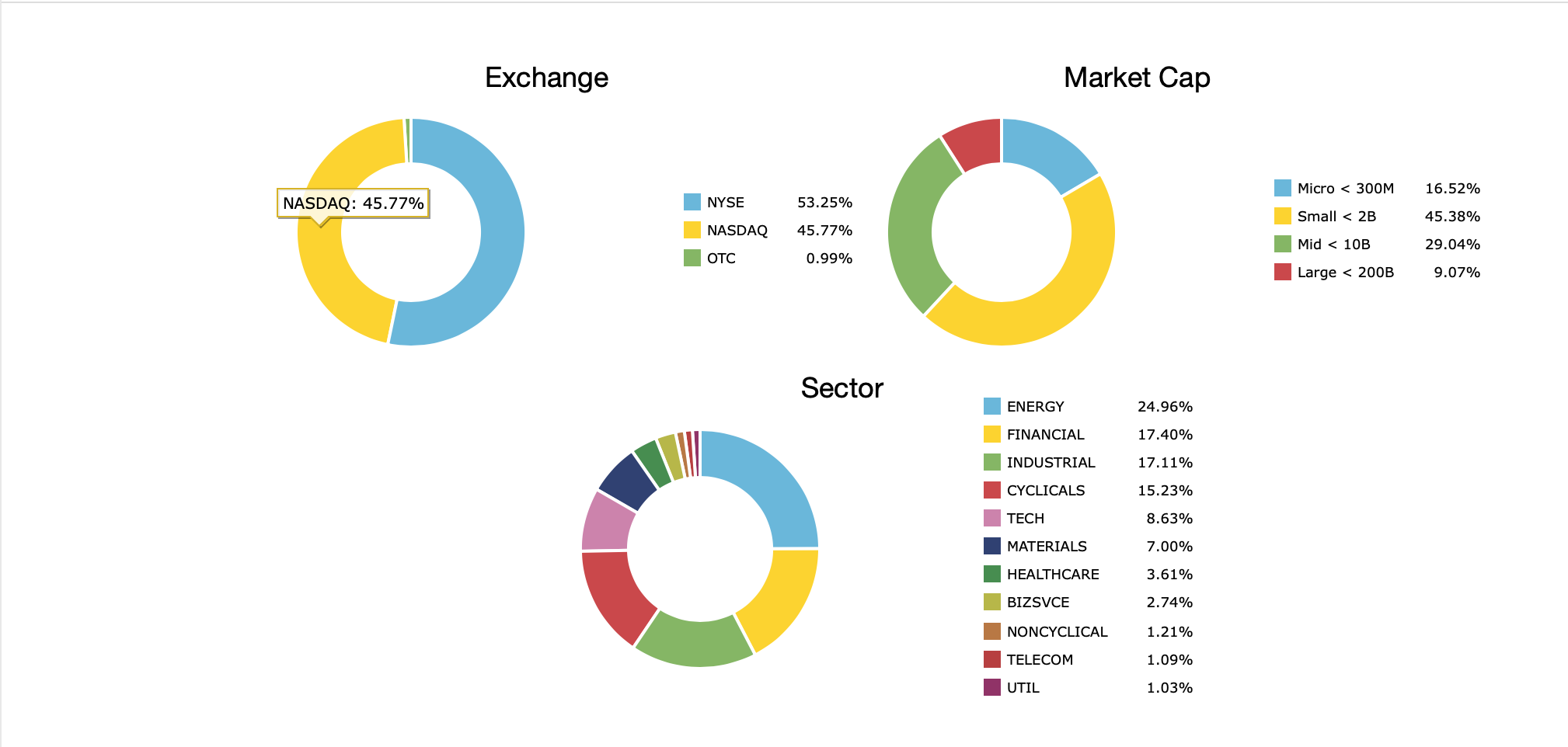
Can you share the holdings of the 'Easy to Trade" simulation? I’m curious about the characteristics of the holdings. No worries if you don’t want to do that.
Also, have your tried your ML process on a larger cap universe; ie S&P500 or SP1500?
I have not optimized this system (pure machine learning I have never used the optimizer for this) for the SP500 universe.
Although….Anyone who self-identifies as not using any machine learning thinks optimizing is not machine learning, right? I don’t want to interfere with people’s ability to self identify and I am good with whatever anyone wants to call that or define things. Although much of it seems “algorithm fluid” and constantly changing. Which is good; don’t get me wrong.
But actually, this is not optimized for the Easy To trade Universe either. I run a more liquid port for most of my investing. I did not try to adapt if for either the Easy to Trade Universe or the SP500. Just changed the universe without re-running the algorithms.
I did some testing on timing systems. They did not seem to work well for mee. In some cases, they reduce drawdown, but that’s usually what the achieve. Do you have other timing rules that you find interesting? Under are some of my tests.
Without timing systems: (25 stock 15year backtest weekly, North America (Primary) and volume rule: Mediandailytot(120)>( 100* 1000) and StaleStmt = 0
The hedges I have tried is:
(sell) eval(close(1,##inflexp)<=4.5, 0, 1 )
(buy) eval(close(1,##inflexp)>=4.5, 0, 1 )
SMA (3, 0, ##UNRATE) > 0.5 + LowVal (12, 0, ##UNRATE) > 0 and Close (0, $SP500) < SMA (210, 0, $SP500)
Entry Rules (Implicit AND)
sma(6,0,#SPEPSCNY) < sma(6,12,#SPEPSCNY) // SP500 blended estimates trending down
close(0,#bench)<close(100,#bench) // Benchmark lower than level 100 bars ago
Exit Rules (Implicit AND)
sma(6,0,#SPEPSCNY) > sma(6,12,#SPEPSCNY) // SP500 estimates trending up
close(0,#bench)>close(100,#bench) // Benchmark higher than level 100 bars ago
I think it would be helpful if someone defined what is meant by “machine learning” in the context of discussions here.
As I understand it, machine learning is when an automated model makes decisions based on data without being specifically programmed to make those decisions. Instead, it makes those decisions based on learning from the data it is given for training purposes, without being given a method to do so by a programmer. How much of the method is derived from the programmers and how much is derived from the machine trying out different approaches without specific programming is going to vary from machine to machine. But without at least some of the latter, I think labeling a model “machine learning” would be a misnomer.
If a system is algorithmic, quantitative, as free as possible from qualitative decision-making, and mines data to the hilt, it can be wonderful, but is it “machine learning”? If it doesn’t involve unprogrammed decision-making, I would prefer to call it “data-based,” “algorithmic,” or “quantitative.”
I would welcome alternative views. And perhaps this is only a semantic quibble. I am curious, though, whether the system that Jim is discussing here is “machine learning” or not, since I know little about how it was developed.
Undoubtably it is semantics as you suggest (as a possibility). And I am not actually fond of the word(s) machine learning.
I might even kind of be thinking like you in this regard: Who, exactly, is going to be in charge of looking at what I do and what some other members at P123 do and putting their work into bins labelled machine learning, statistical learning, AI and “not machine learning.”
I would note that anyone in charge of this process—using only those terms–would probably have to put any algorithm using regression into the category of machine learning. And certainly the use of a correlation is machine learning but would at least qualify as statistical learning by any definition, I would think.
One of the things I like about the term reinforcement learning is that I would not preclude some of the learning occurring within a human mind—as clearly happens at P123.
Reinforcement learning is kind of like developing an algorithm for what humans do. That would not preclude a robot stopping for moment to run a little routine that uses a spreadsheet or running a regression along its path to its goal. Something a human might also do.
Argument for liking the term reinforcement learning by comparing the P123 optimizer to machine learning.
Machine learning: uses gradient descent (almost always now even for simpler regressions). As magical as the term may sound it is not really much different than this:
P123 user:
try something in the optimizer
increase the weight of one of the factors
if the results improve increase the weight of the factor a little bit more
If things (i.e., any metric) continue to improve (e.g., returns) increase the weight again
Repeat, repeat,
When things stop improving stop increasing the weight of that factor
Look at another factor. Repeat, repeat, repeat.
Gradient descent and what one might do with the optimizer at P123 is the same. Exactly the same (or can be proven to be mathematically equivalent yielding the same result). Name it whatever you want.
One could also use a “Grid Search” with machine learning. Something that humans are clearly duplicating with the optimizer at P123.
FWIW. I am all for people calling what they do whatever they want. Probably there will be a day that I want to call what I do: “Jim Rinne’s expensive (but high-performing) quantitative algorithm that is NOT MACHINE LEARNING that only he can do and I am so grateful he has made it commercially available, sign me up. OMG this is great. I am going to text all my friends” That will be the literal name I will give it, I note that I can name a designer model anything I want although I admit I am not sure about the number of characters allowed.
If an outside observer wanted to say “nice name but I think that is machine learning,” speaking only about what I have done she would have the following points:
Some use of both frequentist and Bayesian statistics.
The final weights for the factors and nodes come straight out of a Python program that most people would agree can be called machine learning. Without modification.
Some cross-validation was used which can only be described as a machine learning tool uhhhhh…or alternatively common sense. But in this context I make the argument that it is machine learning.
Again, speaking about only what I have done: She is wrong. My algorithm is not machine learning. I was too involved in the process to call it that
Just some thoughts. Yuval,I like what you do with your models no matter what you prefer to call your own models. I truly do. Full stop. I certainly appreciate your professional work—especially in the area of what I would call feature engineering. I appreciate it without really caring what you wish to call it. A rose by any other name……
I fully agree. I would only add the term reinforcement learning to this list without caring much whether some of the learning occurred within a human brain (or not).
TL;DR. Everyone at P123 uses the equivalent of gradient descent (and/or a grid search) whether it is done by a machine, by the human brain or both in a reinforcement learning algorithm. That is how I would try to parce it. But just me without really caring how someone else wishes to do this.
BUT WHAT I DO IS NOT MACHINE LEARNING!!!
Edit. BTW I think this supports what Marco is doing with the platform and happens to be true. I would not have said it otherwise. P123 is an opportunity to print money and I want it to be available forever (even if they decide to change the name).