Since we can only let you download ranks, but not the data point itself…What if we add more ways to rank , like normal distribution, pareto distribution, etc. And allow you to specify which ranking method to use for each factor/formula
Wouldn’t this be just as good as having the data itself ? Would this facilitate the ML studies you are doing?
XGBoost is amazing with regards to what you are asking. IT JUST NEEDS TO HAVE THE ORDER OF THE FACTORS PRESERVED.
So whether the factors are: raw data, ranks, Gaussian distributions etc IT MATTERS NOT AT ALL.
It is a non-linear and non-parametric method that can have the factors transformed in any way as long as the order is preserved AND GIVE THE EXACT SAME ANSWER.
Theoretically this applies to neural nets too but is GUARANTEED BY THE WAY A REGRESSION TREE METHOD LIKE BOOSTING WORKS.
In short, FOR BOOSTING RANKING IS ALL ANYONE EVER NEEDS!!! That as well as the returns and a usable index.
Sorry about the caps but if one is not excited by Boosting they just do not understand it. IT IS EXCITING TO SEE PEOPLE LIKE STEVE USING THIS.
Marco - I would have to think about that. The biggest issue for me is the target not the inputs. The current ranking system for inputs is probably adequate, but worth experimenting with for some of your suggestions. If your ideas help with generating a target that is closer to the real data then I’m all for it. I don’t know enough at present to say whether your ideas will help or not.
I would also like to remind you of my previous feature request. That is to allow negative time period offsets. That will make it much more straight forward to use one set of equations for generating the training data and for generating inputs for future predictions.
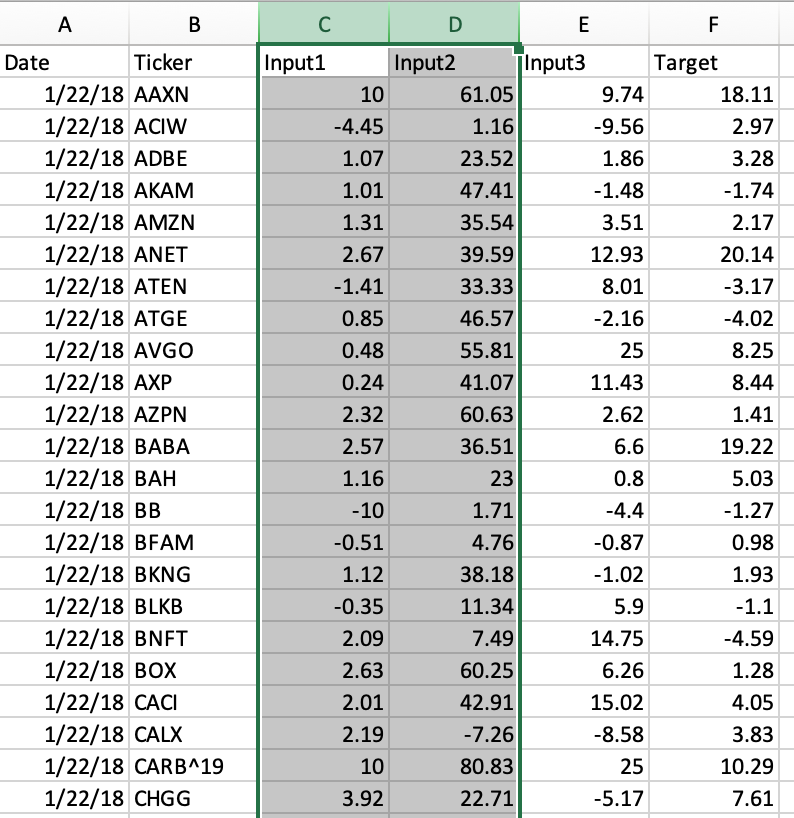
Steve will correct me on this if am not aware of everything he is doing. When we correspond I am not always aware of the nature of his inputs and Targets. They are often labelled Input1, Input2…. and Target. This is good. I am not looking to learn other peoples factors.
I think he uses different targets than I do, however.
But one usable target is just the next weeks returns (for a weekly rebalance). This can then be sorted and one can buy the 5 to 25 stocks with the best predicted returns for next week.
Steve does seem to agree that the ranks (for inputs or predictors) are all that are needed for the factors. I am just going to say this is absolutely true.
One of the pre-processing ideals for neural networks is to prepare the inputs so that there is equal distribution across the range of input, or as close as possible. The ranking system algorithm probably does a good job in that regard. And as Jim says, xgboost doesn’t care about linearity. It’s more of a concern for tensorflow. The main issue that I have is recovering a target that somewhat resembles what I am trying to predict, not a 0-100 rank. So maybe there is some distribution trick that can be used to get better results.
Correct. Which is already done by a Rank!!! Ranks do as Steve suggests: "there is equal distribution across the range of input. Or perhaps it is better to say that all inputs are scaled or normalized the same.
There are some who would divide the rank by 100 to make all of the inputs between 0 and 1. This can be done by Colab or Python or in a spreadsheet. So P123 would not need to make this a priority.
Any thoughts on other ML platforms that may be more suitable , easier to use to non AI experts (me for example) ? Chaikin uses https://www.r2.ai/ and he must have just learned it
It provides boosting, K-Nearest Neighbors, Random Forests, and Regularized linear regression. For both regression and classification. As well as unsupervised machine learning methods.
In addition it provides Bayesian methods.
I use if for Factor Analysis where it does as well as SPSS.
The ML portion is constantly being upgraded in JASP which provides frequent upgrades.
It is already usable. And is menu driven. NO PYTHON PROGRAMMING!!!
Marco, you should provide an easy download into a csv file that is immediately ready for upload into JASP.
There isn’t really enough technical info on the r2.ai site to say whether it is a good product to use. I was in the same state as you are now and reached out to Jim as I know he was using tensorflow and xgboost.
It looks to me as if r2.ai has a certain price but you may find that AutoML has usage fees in addition to what r2.ai charges. Another consideration is whether you want to base your efforts around a company that may disappear in the future… Think Quantopian.
The big decision is whether r2.ai or other company allows you to run an external program (your project code) to invoke their product and deliver results back to your program. With some products that I have seen, you actually have to power up the application, run the neural net, save the results somewhere in a file, then you run your external application and read the file. It is doable but will be a pain in the neck long term and especially if you are running a lot of NNs.
The advantage of tensorflow and xgboost is that they are free and there are no usage fees that autoML may invoke. There is little danger that Google will disappear. I believe that xgboost is open-source or is at least a standard import for Colab. The big thing is that you can run your own project code, whatever that may be… I am using Python, invoke the AI software and have predictions returned directly for my code to process and use. I can use the results directly as they are in arrays, not stored on disk somewhere. There is no need for a multi-step manual process.
I was in your situation a few weeks ago. I wanted a NN program with a nice GUI that allowed me to run things confidently. But I have gotten past that. I have Python code. If you want I can give you that (if Jim is OK with that) and it will get you up and running quickly. You have to learn Python though. Its not much different than any other programming language.
The nice thing about xgboost is that it is orders of magnitude faster than tensorflow, making some applications possible that I can’t do with tensorflow. I also find that it is pretty robust relative to tensorflow, based on the tests that I have been performing. xgboost is some sort of decision tree algorithm as opposed to a NN. I just treat them both of them as black boxes.
Honestly, my interests aside, I think there is a business opportunity here especially since Quantopian is leaving a vacuum.
And to reinterate no one is asking for P123 to provide any machine learning.
I do not think Colab will go away. Google is essentially training young people in machine learning that they hope to hire in the future. It is used in all of Googles online courses in Coursera.
And honesty even JASP is good. Drag and drop. Menu driven. Completely free.
Jim, I don’t follow. Target is ok for us to include. But what’s Input1, Input2, etc. ? Those are not ranks. Sure looks like data / factors and we cannot re-distribute that. They need to be ranks of some sort. That’s why I was proposing different ranking methods that transform the data but basically hold the same information for an AI system w/o breaching the license.
Marco - What Jim was showing was a small sample of data that I scraped somewhere. it will all be ranks. I just wrote a routine that pulls ranking system data weekly and dumps it into a file. I haven’t tested a neural net with Ranked inputs but will be doing that soon. All is good.
Right. I was just focusing on the column headers. Sorry for not being more clear.
The reason for the oversight in the way I presented this to you is XGBoost literally does not care (and therefore I was not even looking at Steve’s numbers). Steve could have sent me raw data, rank positions, multiplied everything by 1,000, given me the Z-Scores and XGBoost will spit out the same answer. Literally exactly the same answer (because the order is preserved with each of these “transformations”).
It is true that it is probably best to normalize neural net inputs which ranking already does. If a person who uses neural nets likes to have the inputs normalized between 0 and 1 (as is often recommended) the ranks can be divided by 100.
Steve has more experience with neural nets than is apparent in his posts. Perhaps his is avoiding jargon that he thinks will not be understood by everyone in the forum. We talked about normalizing the data (or standardizing it) for the neural net. But he knows a neural net can generally handle data that is not normalized. Often it just takes longer to run as was the case with his data.
Consider this. Neural nets are famous for recognizing picture of cats on the internet. Who thinks the distribution of cats on the internet is a Gaussian distribution? Or that the data for self-driving cars is a bell-shaped curve?
And the code I shared with him uses “BatchNormalization” that normalizes each batch and GENERALLY resolves these issues. Not that he won’t address this at some point before he funds a neural net model or makes it available to others: he will I think.
And I reinterate that this whole topic of normalization can be dropped completely for boosting.
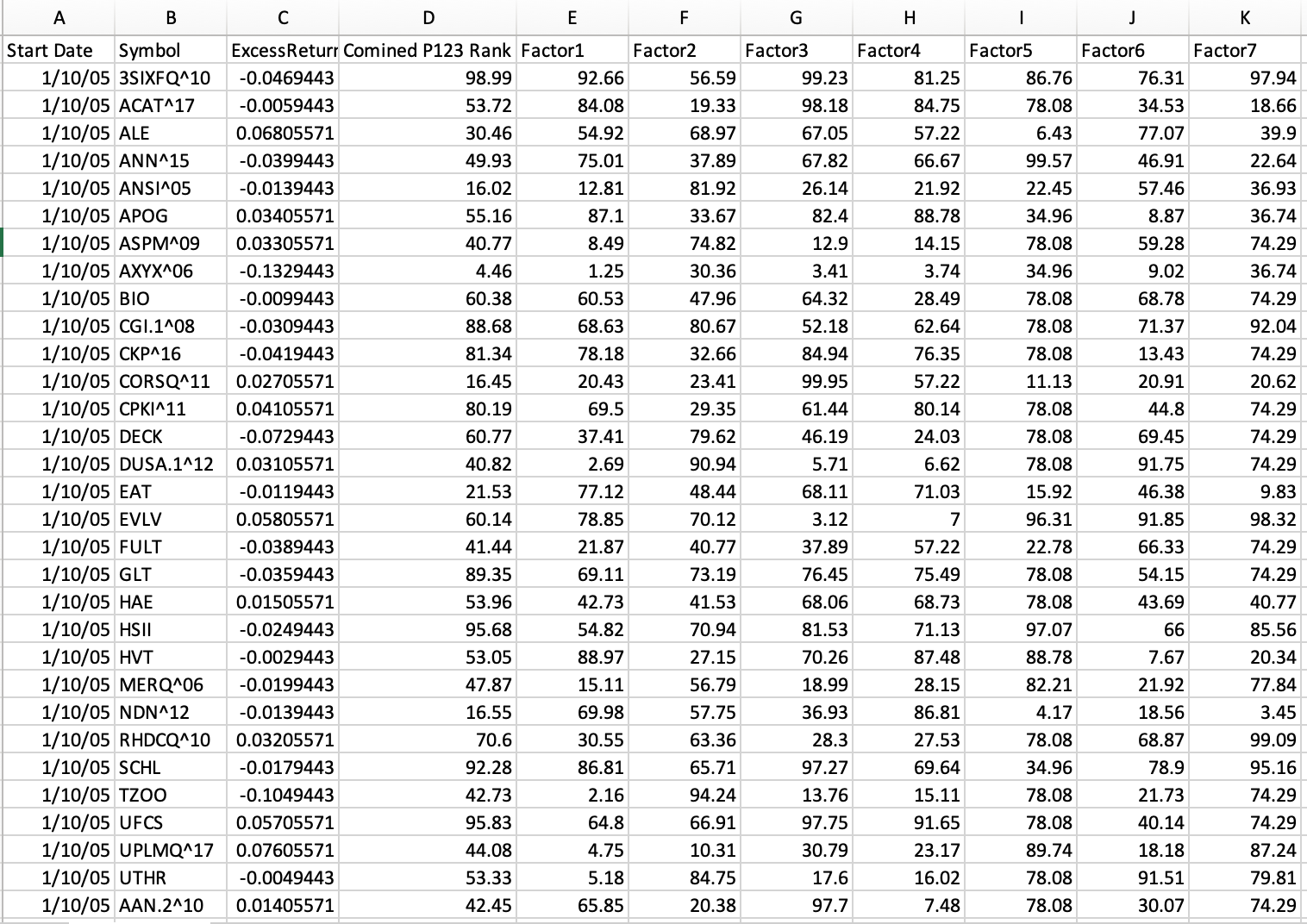
So anyway to the point. Here is an example of a spreadsheet with over one million rows of data.
This does use ranks.
I like to use excess returns for the Target. This reduces the noise that comes from random changes in the market.
“Combined Rank” is P123’s rank using all of the factors. Factor1, Factor2,……., Factor7 are ranks of individual factors (each given 100% weight).
So I could get predictions on each ticker and compare (after sorting) to see how “Combined Rank” performed. I compared how P123’s rank performed to the predicted returns with a neural net or with boosting using the the individual factors as inputs for ML. So for the ML predictions the ranks of individual factors were used as inputs.
My opinions on the value of ML were not formed without evidence.
Yep. Steve gets it. Steve is incredibly intelligent, is a good programmer and has more experience that people realize.
As an aside this seems weird:
Isn’t Marc Gerstein over there at Chaikin? You know the guy who c*sses every time anyone uses a number and calls them a quant?
Marc is now over there producing a product that uses machine learning? Has he gotten Physics Envy all of the sudden?
Maybe h*ll has frozen over.
So P123 is now literally the last place on earth to advocate using stock IDs to download data onto a spreadsheet to simulate bootstrapping (if Yuval is still recommending this use of spreadsheets) when one can do real bootstrapping with a drag and drop program that is menu driven (like JASP). Do it correctly and literally in seconds. Or if so inclinded use some of the most advanced programs on the planet (like TensorFlow) without that much additional work.
Weird. I think even Marc is not willing to die on that hill and is willing to adapt.
Anyway, it would take just a little for P123 to move away from spreadsheets and the DDM as its only business model. And you can keep the ranks, I believe.
Here are my 2 cents. I am not an ML specialist, just a former software architect. I have tested only a couple of scikit-learn algos in the (dead) Quantopian environment, I don’t know Colab and JASP. These are my ideas to start a higher-level interface between P123 and any ML environment
First question (to Marco and P123 staff): Does P123 want to provide a higher-level Python interface to help advanced users feed ML apps or web services?
If the answer is yes, then the first step is to define a GENERIC OUTPUT FORMAT for tables of features/labels, independently of the target app or service (should it be hosted by Google, Sagemaker, Azure ML or other) . Specialization to fit a specific environment (JASP, Colab) may come in a second step if needed. ML algos eat tables of features and labels, separed in training, validation and test sets. A generic output format for features/labels is especially important because ML is a fast changing world, but the paradigms of features/labels and training/validation/test are constants in supervised learning (which is the subset of ML we seem to be interested in).
The output format can be determined by a few constant and variable characteristics:
We are manipulating financial timeseries, so the index of the table’s first axis (= key of each row) is a couple (time,ticker). We are handling daily data, so time is a date. The number of rows in the table depends on the combination of (ticker,date) we want in the training set (or validation set, or test set).
The columns of the table are inputs used for prediction (= features) and outputs to predict (= labels). The number of columns (excluding the double index) is the number of features, plus at least one column of label (more if we need multi-labels: predicting return AND volatility for example). If P123 allows us to export ranks and not raw data, one feature is either a rank, or another authorized exportable data (sector or industry for example). The label is the outcome to be predicted. It may be the future return of the ticker 1 week, 1 month, 1 quarter after the date of the row’s index value (when the ranks are measured). But it should not be limited to that. It may be a discrete classification with 2 or more values (example with 3 values: beats the sector index by 1% or more, lags the sector index by -1% or more, or in between). I think classification algos (predicting a category) are more appropriate for our purpose than regression algos (predicting a return), but this is debatable: so let the choice to the user.
A key point in the structure: a feature is measured on the date of the index value, a label is measured after a specified elapse time (outcome to be predicted).
THE OUTPUT STRUCTURE MAY BE DEFINED AS A CSV FILE. HOWEVER, IN A PYTHON API WE MAY DIRECTLY OFFER POWERFUL OBJECTS: PANDAS DATAFRAMES.
In an ML app, the upstream data wrangling (cleaning, reformating, enrichment of features) is much more important than the algo itself. Pandas is the best of Python for that. An overview of what is embedded in a pandas dataframe:
Usual array functions optimized for large datasets, with cleaning operations (like dropna).
multi-indexing (naturally fits our need of a double index)
a bunch of statistical operations (useful for feature enrichment: creating new features from existing ones)
SQL-like groupby function calling statistical functions on subsets (for example to create new columns with cross-sectional features on sectors) and multi-table queries (join and merge).
Json, csv or binary serialization (to feed external apps or web services)
Hope this helps
Frederic is right about machine learning (as he always is).
I did not read through all of his his post as much of it does not apply to me.
But he is clearly correct about cross-sectional data and time-series data both being widely used and being different.
I emphasized cross-sectional data. For the most part that is what P123 does with its ranks and sims.
One reason I did not mention time-series data is that I just get that from Yahoo! when I look at that time-series data. I am not sure that this is where P123 can show its true strength.
And I have tried recurrent neural nets with advanced Long Short-Term Memory for time-series data that has been developed just recently. I have not gotten it to work for me. That is not to suggest that someone else cannot get it to work for them.
Anyway Frederic and Steve both have good insights, IMHO.
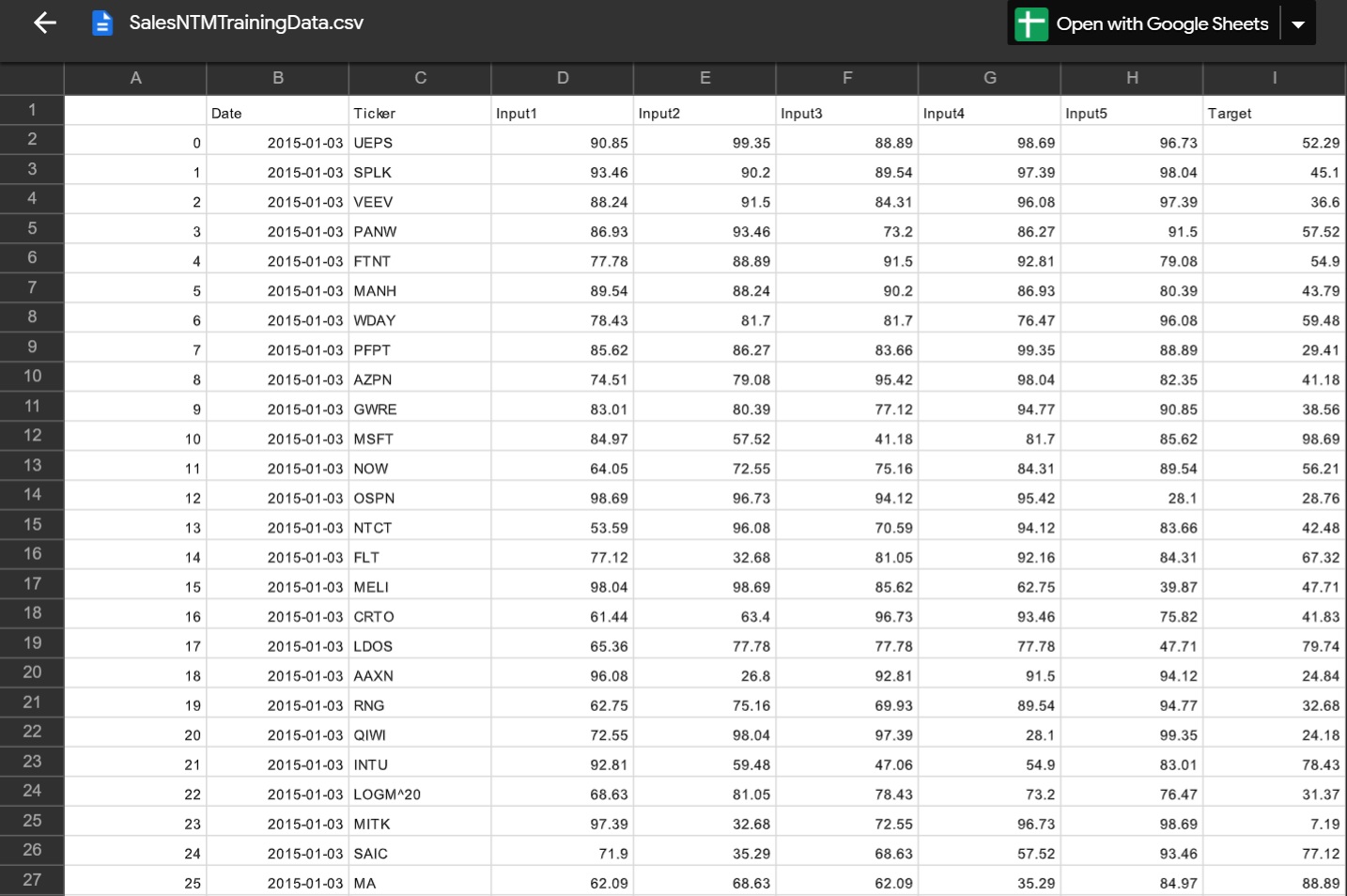
I have Python code right now that takes a simple ranking system and dumps the outputs to a csv file stored on your Google Drive. You provide the date range and the program generates the weekly RS data. It is written for Colab but you can easily port it to your desktop. A sample file output is attached.
I will be making this public. P123 can take it and make the code more professional if they wish.
You need to put p123api.py onto your Google Drive in a subdirectory called ‘Modules’. You can of course modify the code and directory as you wish. The p123api.py file has to be in its native form (text file). If you try to extract it from GitHub and then save it using Colab you will get an error when you try to import it into your code.
The CSV file will be written into the Google Drive directory ‘Modules’.
Who would have know that I just had to reshape the array into a flat structure? I have done this before in TensorFlow for time-series data: but just barely.
Anyway, excellent. I think I can get what I need thanks to Steve’s help.
Still, if it were me I would make it a little easier.
I know i am the big advocate for machine learning including the use of TensorFlow. But some days I wouldn’t mind taking ten seconds to run a regularized regression on JASP. AND MARCO SEEMS TO BE MINDFUL OF THIS. Or download some data on my Mac without using Parallels or Bootcamp or going back to the office for a Windows machine. And Steve has been doing this all of his life.
I don’t really like doing this any more than Steve would want to take over for me during surgery, I suspect.
And just to be clear for anyone having any doubts about using machine leanring, TensorFlow and XGBoost are not the hard parts of this. I think Steve will attest to this in a few weeks if not already. Our hardest problems have been getting the data over to Colab without a doubt. And it took Steve to do it.
P123 could make if a little easier I believe. But still very much appreciated all around. Thank you Steve and P123. I could live with it as it is. Probably.