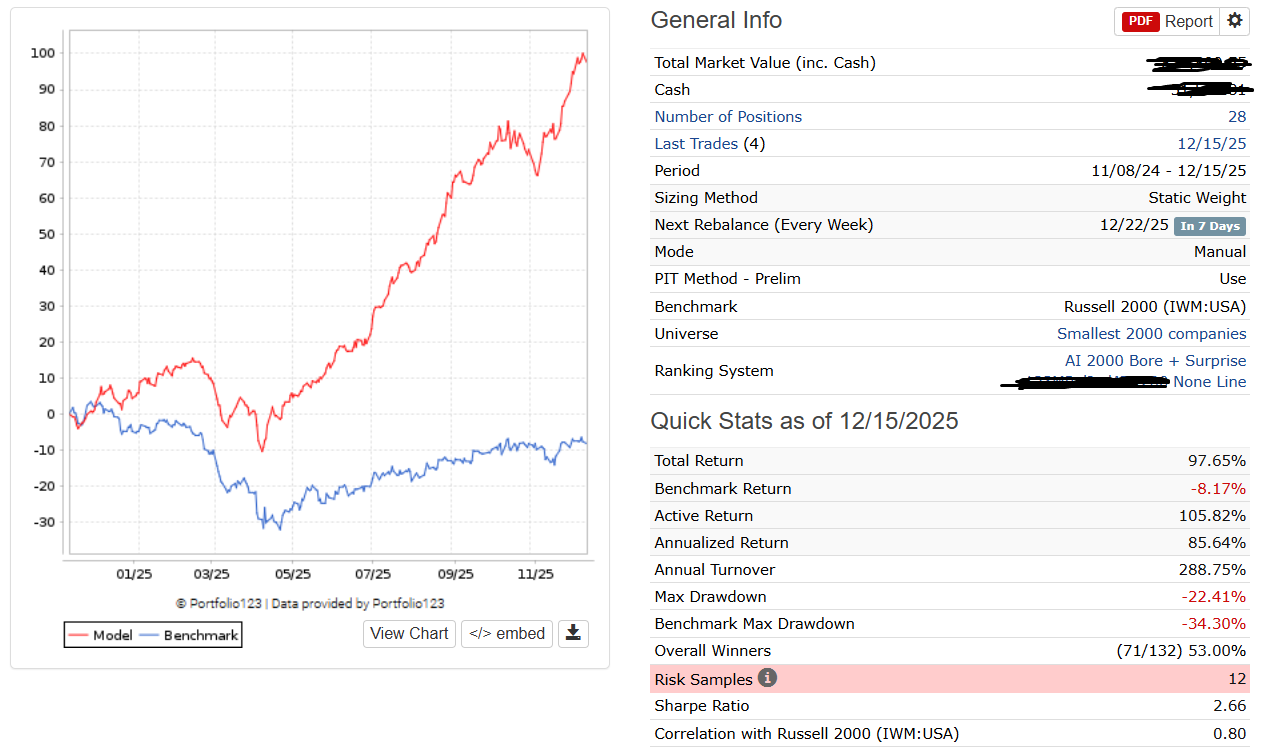
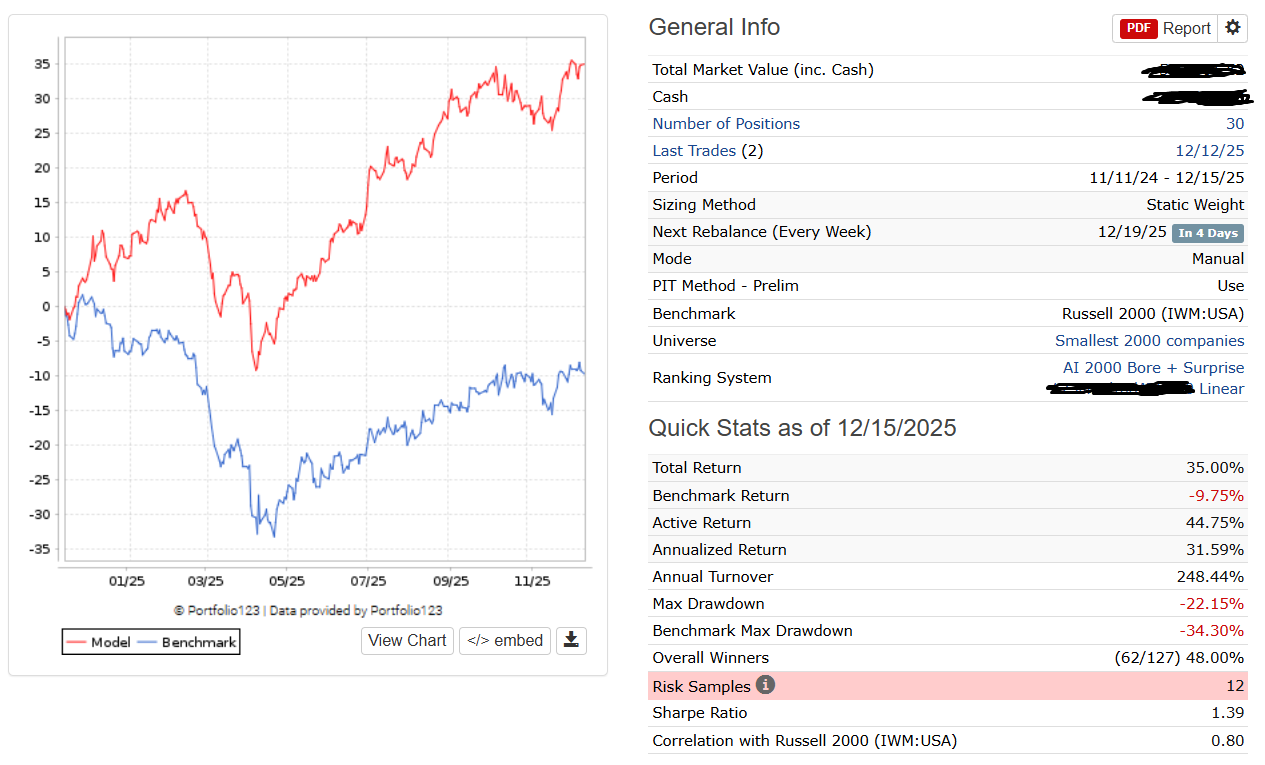
By the way this is what I understood from the substack post from Andreas:
| Setting | Large & Mid-Cap Stocks | Small-Cap Stocks |
|---|---|---|
| Architecture | ZScore-based only: 1. ZScore + Date (Global) with Skip and Date at the feature level. 2. ZScore + Dataset (Global) with Skip and Dataset at the feature level (considered best for long-term robustness). |
A combination of both: 1. ZScore + Date (Global) with Skip and Date at the feature level. 2. Rank + Date (Global) with Skip and Date at the feature level. |
| Rationale: Builds relative, dynamic rules that adapt to rapidly changing market structures. "Rank + Date" is too static and loses its robustness in these efficient markets. | Rationale: The two systems are complementary; they select different stocks, increasing the portfolio's capacity and diversification. "Rank + Date" works here because inefficiencies are more stable and can be captured with absolute rules. | |
| Target Variable | 9- to 12-Month Total Return / Relative Return. (Note: 6 months might be fine for Mid-Caps, but was not tested by the author). |
3-Month Total Return / Relative Return. |
| Rationale: Longer horizons smooth out short-term noise and align with how institutional capital rotates in more efficient markets. | Rationale: Signals decay faster in noisy small-cap markets. Shorter horizons are ideal for capturing strong, short-term mispricings. | |
| ML Algorithm | ExtraTrees | LightGBM + ExtraTrees (used to provide complementary signals). |
| Rationale: Stable, low-variance, and performs well with the "cleaner" data typical of large-cap stocks. | Rationale: They serve different purposes: LightGBM is an "alpha extractor" (best for concentrated portfolios), while ExtraTrees is a "rank stabilizer" (best for broader portfolios of 30-100+ stocks). | |
| Number of Features | Sweet Spot: 87–180 | Sweet Spot: 87–180 |
| Rationale: A carefully selected set of features is crucial. The author emphasizes building on top of well-tested factors rather than reinventing the wheel. | Rationale: A broad, curated set of features is necessary to capture the various drivers in the more complex and noisy small-cap universe. | |
| Outlier Limit | Always 5 | Always 5 (for the ZScore architecture). |
| Rationale: The author emphasizes that the default value of 2.5 is too low and will remove too much valuable information. | Rationale: Same as for Large Cap; the default value of 2.5 is too low. | |
| Retraining | Less sensitive to retraining. | Rank + Date requires regular retraining (every 12–18 months). |
| Rationale: The ZScore approach is relative and has a "longer shelf life" across market regimes. | Rationale: The absolute, static rules in "Rank + Date" must be refreshed to remain relevant. The ZScore system is more robust over time. |