I completely agree with this, it is all a lot of BS. Every fund provider is now supplying factor ETFs, even Vanguard since Feb-2018. But can anybody please tell me which factor fund I should buy now, and provide evidence why it will do better than any other factor ETF. And of course, we also need to know when to switch factor ETFs. There is nobody around who knows.
Here is a link to a recent article showing why Vanguards selection strategy for their momentum ETF (VFMO) is not going to work:
Why Not To Invest In Vanguard’s U.S. Momentum Factor ETF
The problem with “alpha” is that it can/will fade over time. We all know that. And that leads to the problem with the current ranker performance binning scheme - it merges performance across the entire evaluation period. If a system did have alpha but it faded to neutral, that early out-performance will taint the summary statistics. We really need to see the evolution of the performance bars over time within a rolling simulation window. And that would be for a complete ranking system. Fishing for effective single factors and then grouping them together to make a complete ranking system has seldom worked for me. The interaction of factors has importance, too, as does their individual, independent contributions.
This is 100% true in my estimation too. Marc has been a champion of interacting features for a long time also.
But the Excel download does let you work with whatever combination of factors you wish. It is a great tool! A tool that everyone wants to do something slightly different with.
Given a choice I would prefer to munge (wrangle) the data than be locked into someone else’s Alpha, Beta or Omega.
We are asking P123 for a tool. As a Product Manager, I feel like your job is understand our requirements and prioritize them. It’s not to berate our understandings of markets.
Moreover, I feel like all of the issues you cite have simple solutions or caveats to the user. While I could respond to these by line item, I feel that is not my job to teach transformations, logarithms, project management, and factor sorts.
Like you say, P123 shouldn’t interpret the data for us.
This wasn’t meant to be combative. Its a pretty reasonable and common request and is already out there. It is simple factor analysis. A starting point. If this isn’t useful to you - fine. But it is ‘absolute gold’ to me. Every few months I have to pretty much run as many single factors by hand as I can. If P123 had a few hundred public ranking systems with a single factor each - and provided the exact same stats as they do for every other ranking system on an easy to view page - that would suffice. Not asking to reinvent the wheel here. Just that if P123 can shave 30 hours a quarter off my time…well that’s why we pay for this service and do not just source data ourselves and run everything by hand. Or just use a platform like Quantopian where the data is mostly free but where you have to program in Python.
I think it was CapIQ that I was using now that I think about it. It is probably integrated with their Market Intelligence platform now but I can’t be too sure as it was 5 years ago when I used it. At any rate, thank you for your personal thoughts on what you find useful and not. I would still like to make this a request even though you may not use this feature.
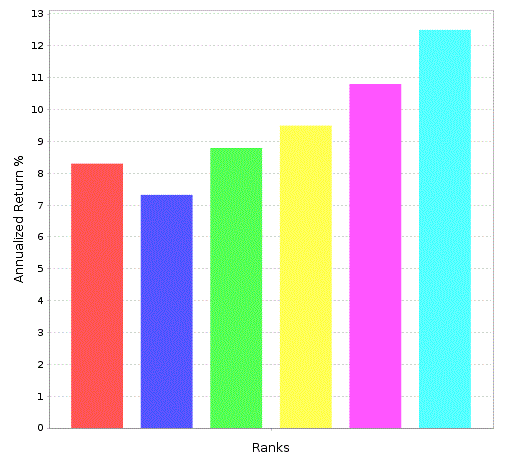
And there are a number of factors for which the right buckets perform the best and the difference between the first and fifth bucket will tell you something.
You are confusing factor evaluation with trading system performance.
See above.
Having the proper tools will give us some idea of factor persistence. Right now we can only guess or for some people look down on this without having a knowledge or data to base opinions on. If P123 is going to use AI, as has been stated in the recent past, then one has to believe that there is something behind determining which factors are “working” and how long they will persist.
Factors don’t individually degrade in a nice fashion. It doesn’t mean that they shouldn’t be used, just that should be used in a smart way, such as putting multiple factors into a ranking system.
Factors may be connected but that shouldn’t stop someone from testing in isolation. Financial institutions have been doing this for years. I have seen past reports indicating which factors are “working”.
One of the most respected and sited papers in recent times: THAT SPECIFICALLY USES THIS FAMILY OF METHODS. They used deciles instead of quintiles which would be a user-chosen option for any well-engineered feature at P123.
Walter, it only “merges performance across the entire evaluation period” if you check the box marked “annualized returns” at the bottom. If you check “performance” instead you can follow the performance over the entire period and see the performance of each bucket over time. You can also download all the data and do what you want with it. The ranking system performance is a very flexible and invaluable tool.
A rank bucket equity curve can hide disappearing alpha. I’ve run into systems where there’s out-performance in the first few years and then alpha disappeared. Since the equity curve got a nice bump early on, lifting the remainder of the curve, the overall plot looked like a winner. It wasn’t. Buyer beware.
I like the ranking performance tool but I prefer to look at the annualized returns over a three year period. By stepping back a year at a time (w/ the ‘<<’ button) and rerunning, I can see how performance changes over time.
However, I would like to see an option to plot risk-adjusted performance (i.e. alpha). Just sayin’
I measured the high decile minus the low decile of share turnover (lower numbers better) just for kicks. Below is the result with monthly, annual, and, just for kicks, 3-and-a-half-year returns, all re-scaled to a -1 to 1 range so that you can compare them easily. There is absolutely no resemblance between them. You can see that on average the top bucket slightly outperforms the bottom bucket because all three lines spend more time above 0 than below 0. But the actual graphs here are useless.
Basically, plotting a time series of the top bucket minus the bottom bucket of an isolated factor is an exercise in futility because changing the period measured changes the results so drastically. The results of the above-mentioned paper are a foregone conclusion because the method of measurement is so flawed. Subtracting the bottom bucket from the top bucket of an isolated factor tells you absolutely nothing about actual real-life performance. It’s a useless fiction, and shouldn’t be encouraged by anyone. Despite its use by academics over decades, I have yet to read a single paper that shows it being successfully put into practice. Those firms that have actually tried it (e.g. AQR) have failed miserably.
Share turnover? What were you thinking you would find that proves some important point about the method? And I would have done it like the paper. The time series is not helpful. Again, one look at share turnover proves what?
Didn’t you use the top quintile minus the bottom quintile to make a point about dividends just two days ago? IN THIS THREAD? I guess the point you were trying to make changed.
I do get your point: those NBER guys (publisher of the paper) are jerks.
De Prado and the rest of the (well paid and well educated) guys at AQR do not know what they are doing.
And we do not need to take David, Kurtis’, Walter’s or Steve’s requests seriously because “the method of measurement is so flawed.” We now have the final word on this—even though Kurtis has been using it very actively and with success if I understand his post.
And this form another post:
Maybe we should call the Nobel committee and see if they can put a little asterisk by William L. Sharpe’s name explaining how “seriously flawed” his work was now that we have Yuval’s opinion on this.
Does anyone else see a pattern or is it just me?
Yuval,
Did I understand correctly in the quote above? You have never done a “p-test?” I guess that means you have never calculated a p-value either?
Oh, I get it. The paper has a t-score and if you have never calculated a p-value………
Hmmm. I do not think my opinion of Steve’s, Walter’s, Kurtis’ and David’s request has been changed much…
Taking the difference between high decile minus and the low decile does not make any sense to me. What is it supposed to tell you?
However, if one compares monthly performance of the stocks in the high decile and low decile one can simply do a t-test to see whether they differ significantly. I compared the All-Stars: Greenblatt ranking system with Yuval’s large-cap system applied to the S&P 500 Index universe from 2004-2019. The Greenblatt ranking system is supposed to perform well with the S&P500 according to numerous commentaries on this forum.
For the Greenblatt ranking system the t Stat = -1.23 for the monthly performance in the high decile and low decile. t Critical = 1.98, signifying that we CANNOT REJECT the null hypothesis. The observed difference between the sample means is not convincing enough to say that they differ significantly.
For Yuval’s large-cap system the t Stat = -2.12 for the monthly performance in the high decile and low decile. t Critical = 1.97, signifying that we REJECT the null hypothesis. The observed difference between the sample means is convincing enough to say that they differ significantly.
This indicates that Yuval’s large-cap system is better than the Greenblatt system because there is a statistically significant difference between the high decile and low decile mean of the monthly performances for his ranking system, whereas for the Greenblatt ranking system the sample means do not differ significantly from each other.
I checked all P123 Ranking Systems for monthly performance of the stocks in the high decile and low decile applied to the S&P 500 Index universe from 2004-2019. There is not a single ranking system where the observed difference between the sample means of the high decile and low decile is convincing enough to say that they differ significantly.
This is the essence of quantitative investing. Why doesn’t it make sense to you?
In any case, you need to be careful as to how you run your tests. For example, you need to make sure that NAs are set to neutral or the results won’t be good.
This is what I get (see below) testing the Greenblatt RS from 2004 to 2019 against the SP500. There is nothing wrong with that. Also. I don’t care whether Yuvol’s RS is better than Greenblatt, however, make sure that when you are testing on Out-of-Sample data. If his RS was developed in 2019, then it isn’t a sound test to compare it with an RS that was developed in 2012.
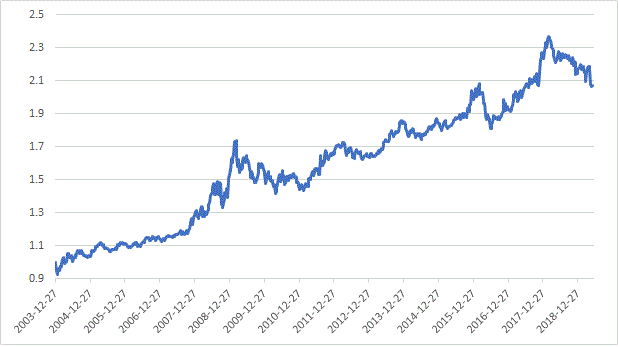
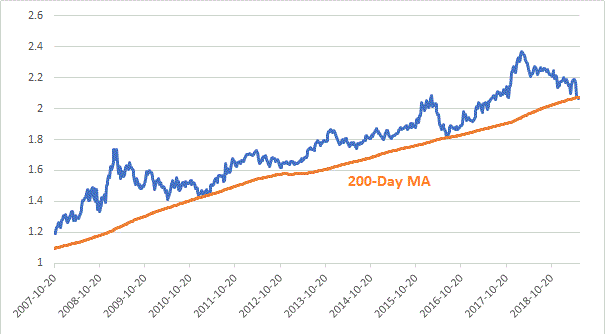
Looking at this slightly differently. Here is a plot of rank 80-100 equity curve divided by rank 0-20 equity curve with NAs neutral. SP500 stock universe, Greenblatt RS. As you can see there are times when the top bucket underperforms. However, the overall long term trend is positive.