*** Full disclosure *** I slept through university stats class. Drinking and partying were more interesting at the time. My stats capabilities are therefore weak. I did do a lot of neural net experimentation through the '90s however. My main conclusions were:
(1) garbage in- garbage out - if your inputs don’t carry a level of significance then don’t expect miracles from your predictions.
(2) The best reason for NNs is to have a semi-rational output in the face of multiple conflicting input indicators.
(3) Deep learning is bad… you don’t want to memorize the inputs, but find some prediction power.
(4) There is the chance that the NN finds hidden undiscovered complex input-output relationships. For this reason alone, optimization is of use.
Steve, spoken like a true engineer.
To this one should add “don’t be greedy”; annualized returns like +30% one can only get from simulations. Aim for models with a 20% annualized return and be satisfied making 15% on your investment.
Here’s one way to do it. Go here: https://www.portfolio123.com/stocklookup.jsp. Click “Status: Any” and press search. Press the arrow next to 100 and scroll down and click on “All.” It’ll probably take several minutes to display the entire list of 36,196 tickers, but once it’s displayed, you can copy it into Excel (you can’t download it, though) and create custom lists; you can then create as many different universes as you want with “Inlist.” Tickers change all the time so you may have to repeat this every few months.
Here’s another way to do it. In the rules for universe 1, put EvenId = 0 and Trunc(100Mod(Ln(SalesA+1),0.02)) = 0; in the rules for universe 2 put EvenId = 0 and Trunc(100Mod(Ln(SalesA+1),0.02)) = 1; in the rules for universe 3 put EvenId =1 and Trunc(100Mod(Ln(SalesA+1),0.02)) = 0; and in the rules for universe 4 put EvenId = 1 and Trunc(100Mod(Ln(SalesA+1),0.02)) = 1. The only drawback to this approach is that about half of the constituents of universe 1 and universe 2 will switch every year, and ditto with universes 3 and 4. AstTotA will also work instead of SalesA in the above equations.
A third way to do it is to use the above equations but instead of Ln(SalesA+1) use Subindustry/XXXX, where XXXX is a large number like 4763. The problem with this method is all members of a particular subindustry will be in the same two universes. But maybe that’s a good thing.
Hmm. I guess it is like a random forest, but without the trees or the objective (classification/regression). Which means it’s different from a random forest too. But that’s not a bad analogy.
And, yes, I do this on a spreadsheet rather than “modern parallel computing.” It’s not so bad; I don’t mind.
yea. and in 136 years you will be caught up to what you could have done last night. If you do many spreadsheets every single day you can do it in your lifetime: just make sure to exercise and eat right. You can get a little ahead in leap-years,
It is a very good thing that you enjoy it:-)
What I say still stands. However you are doing it, it is impressive.
You have come a long way since you responded to a post about bootstrapping in the forum (me too I hope).
Bootstrapping (clearly a statistical method and the subject of the thread) is Astrology? Definitely a change.
Personally, I had no idea of how to use bootstrapping effectively back then.
I still would not know how to use it today without our posts. Thank you for that.
BTW, BOOTSTRAPPING WAS DEVELOPED IN 1979 and RANDOM FORESTS WERE DEVELOPED IN 1995. With the right diet, I know I can learn some 21st Century methods in my lifetime.
I want to be clear about how good of an idea this is.
Someone on their own—even with a review of the literature and other readings—coming up with the idea of bootstrapping and averaging simpler models together is absolutely INCREDIBLE!!! Full stop. No qualification.
This is what makes Random Forests popular in theory and in practice. I could share equations as to how this diversity of models (the independence of the models) is helpful. I could even quantitate how much this diversity does help. It is a function of the correlation of the models.
One need not be (should not be) tied to decision trees to use this basic principle. A Random Forest simply serves as a well-known example of where this is routinely automated. Parallel processors was mentioned because each tree can have its own (parallel) processor speeding the runtime by a factor equivalent to the number of core processors (up to 28 for a Mac Pro). But you can run 50,000 trees on a laptop (usually 4 cores maybe up to 8) overnight—the software is the good.
To show you what we are up against: de Prado has Python code that allows each THREAD which to be use is usually a lot of threads. The memory sharing can cause problems , theoretically, but not so much in practice he says. Also Amazon Big ML uses 32 cores and presumably has a lot of memory. This is not very expensive. If one wants to get it done they can do it.
This does work with a spreadsheet. However, bootstrapping multiple different models happens to requires an awful a lot of spreadsheets (arrays in memory for Python)—or you ain’t doin’ it right.
It is just me who would not want to try to do that—even if I thought I could.
[color=firebrick]Whether one prefers spreadsheets or Python, the principle behind this is wicked-smart and Yuval deserves credit for that.[/color]
Thanks for the kind words. I have to say I got both the bootstrapping and the averaging ideas from O’Shaughnessy. After looking into it, what I’m doing is now called “bootstrap aggregating.” There are no trees involved. And I don’t see how you could work decision trees into the process. Or if you’d want to. You can do bootstrap aggregating without using trees.
What’s important to me is to come up with a ranking system without overfitting. It strikes me that bootstrap aggregating might be better for out-of-sample results than creating a system that gets 70% to 90% annualized returns (my bootstrap aggregating system gets a rather small fraction of that). But the actual procedure creates a host of other problems that I’m trying to grapple with. I’ve only begun, really, and I don’t know how it will all turn out. In the meantime, I’ve started buying a few undervalued large-cap health-care stocks, which I’ve rarely done before . . .
There is also BRAGGING. Bootstrap ROBUST aggregation. You might like that. Robust in the sense that you use the median instead of the mean.
Yuval, let me just put this out there without a response. It would not be up to just you anyway, I think. There are a lot of different ways to implement some of this. More ways than you or I could come up with, in that proverbial lifetime.
But get Walter, others and new members using Python……there will be things that I, at least, could not dream of: with regard to designer models.
Just for future thought as you get a better idea of how useful you think this is.
BTW, a letter of intent (of how P123 and I both could benefit) and an NDA and I can solve some of your problems. Not that you won’t solve them on your own in your own way.
I have a model going myself: paper traded. One that uses bagging but may be different in a lot of ways.
[b]Always happy to discuss general ideas but only up to Random Forests (and analogous bagging) for now[/b]
Perhaps a new function that returns an unique stock ID would be helpful here. That ID could then be used in a hashing function to partition simulation universes.
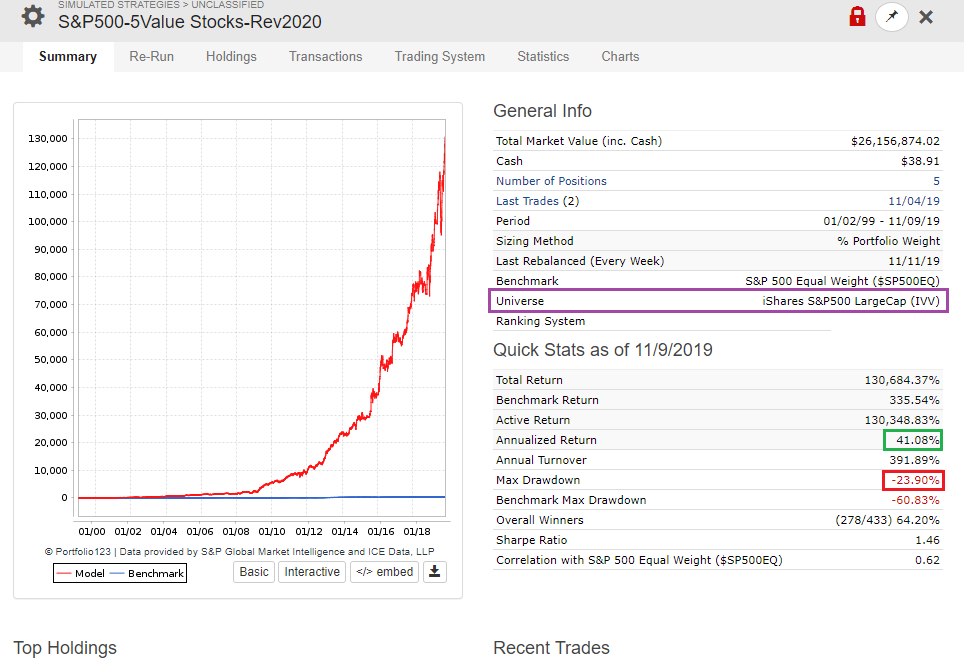
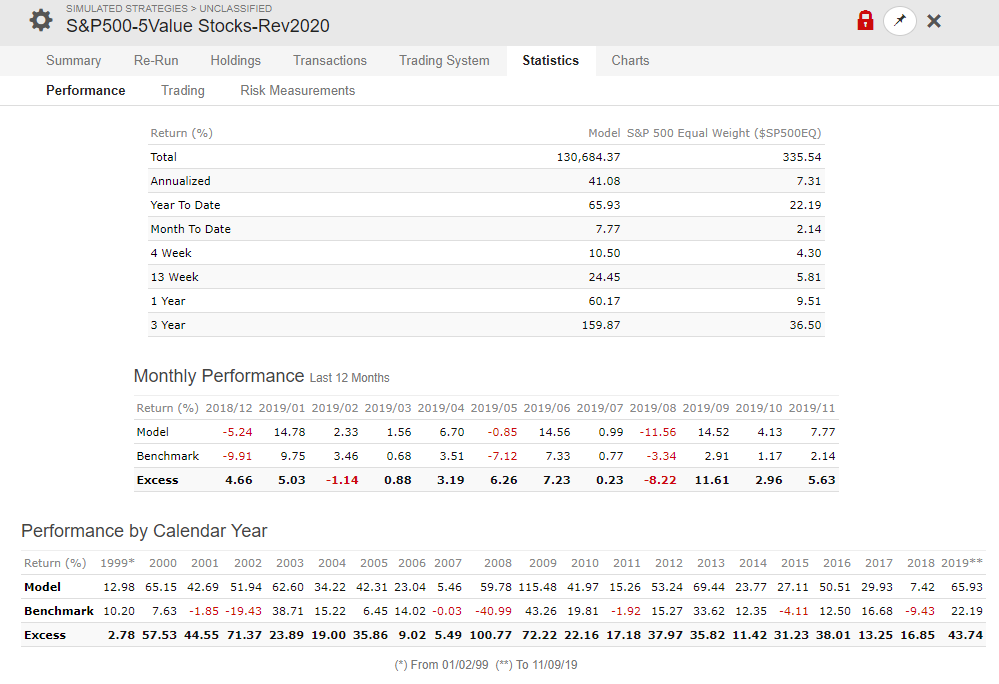
after designing SP500 10 stocks value model for around 4 years.
analyzing the model all of my model;
performance looks just matching benchmark.
and the draw down looks like can’t hold the investment during rough time.
As individual investor we are looking for better return. if we able to achieve 2X return every year consistently using 5 stocks, that is worth the effort, energy and time.
That is the primary reason we are with P123.
Large cap and liquidity models are working fine with long term holding.
Here, I am attaching screen for reference.
Long term holding, Large cap and liquid models are asset protection and the return anywhere between 30% to 40% per year twice the performance of best mutual fund in the world 15% to 20% average return in 5 years.
Yearly 20 Stocks picks systematic manual pick as best stocks using all of my skills/knowledge. 100% Non Quant System. 12 months holding.
=================================================
If you have right skills and knowledge, I don’t think Quant and Non Quant system makes any difference.
When i was working in Singapore in 2000, I argued with my team lead, i have passed typewriting in lower and higher in first class;
So, I can type faster the program / word document etc.,
My team lead said it does not important how fast you type, the important is what you type (knowledge/wisdom).
My stock market skills is result of 6+ years with P123 and
5+ years dedication with SP500 universe and designing models.
and always kept my best simulation as designer model.
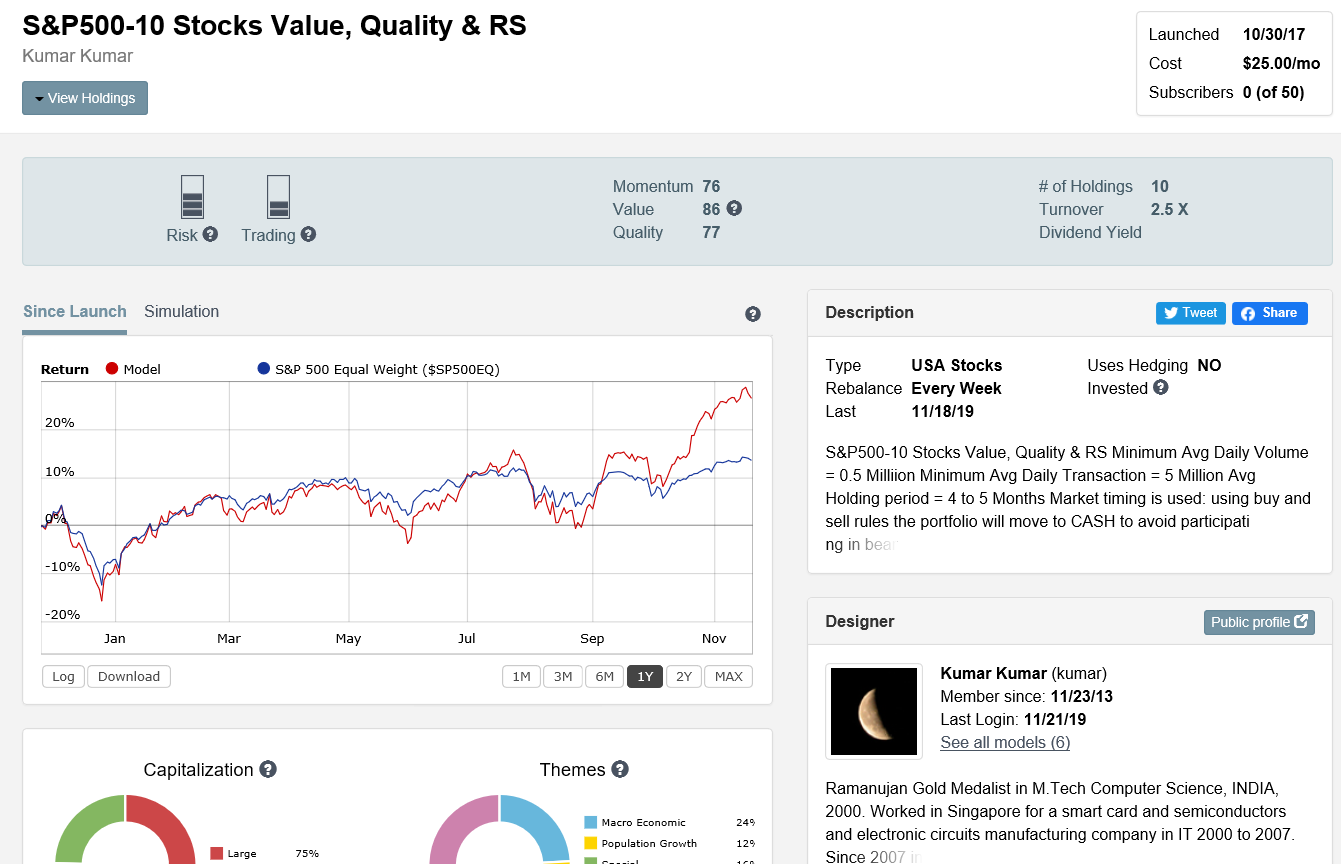
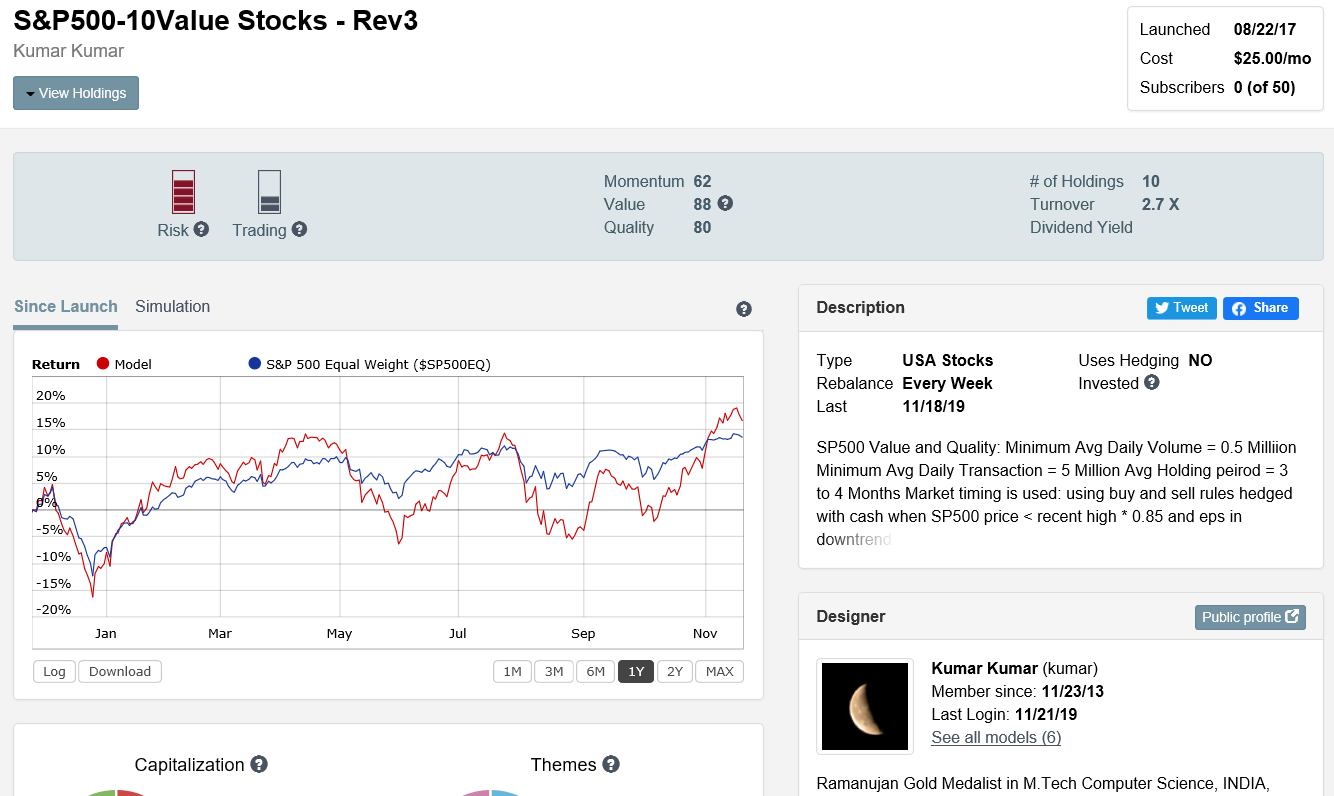
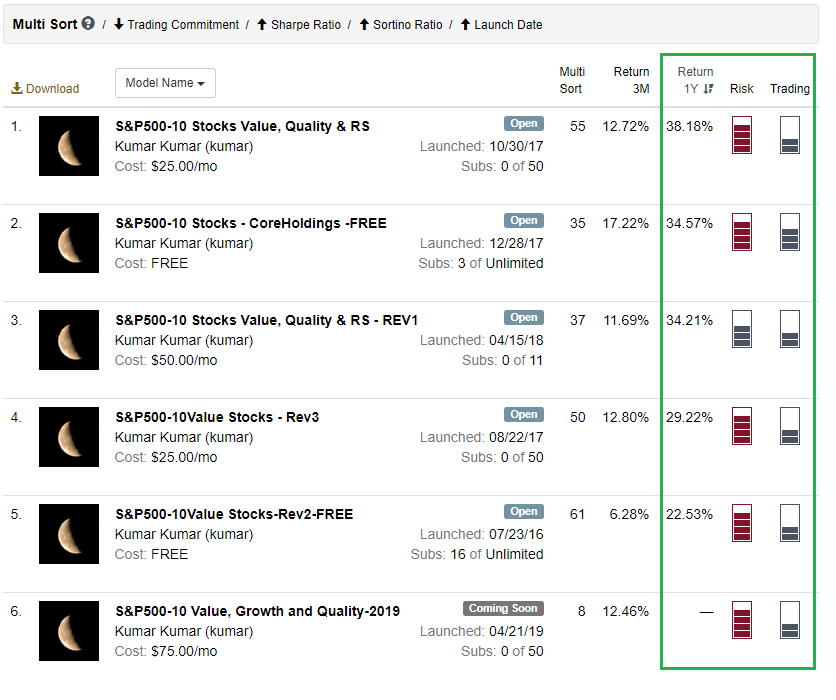
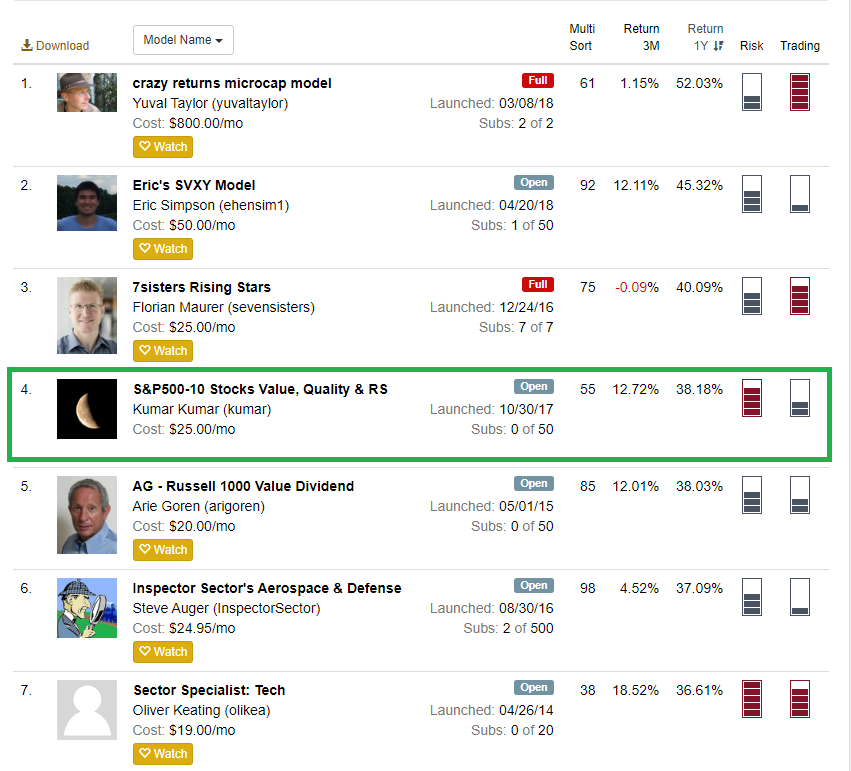
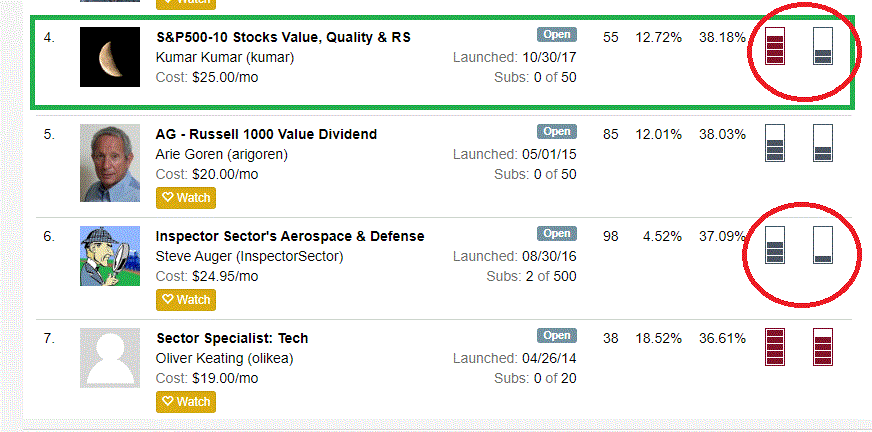
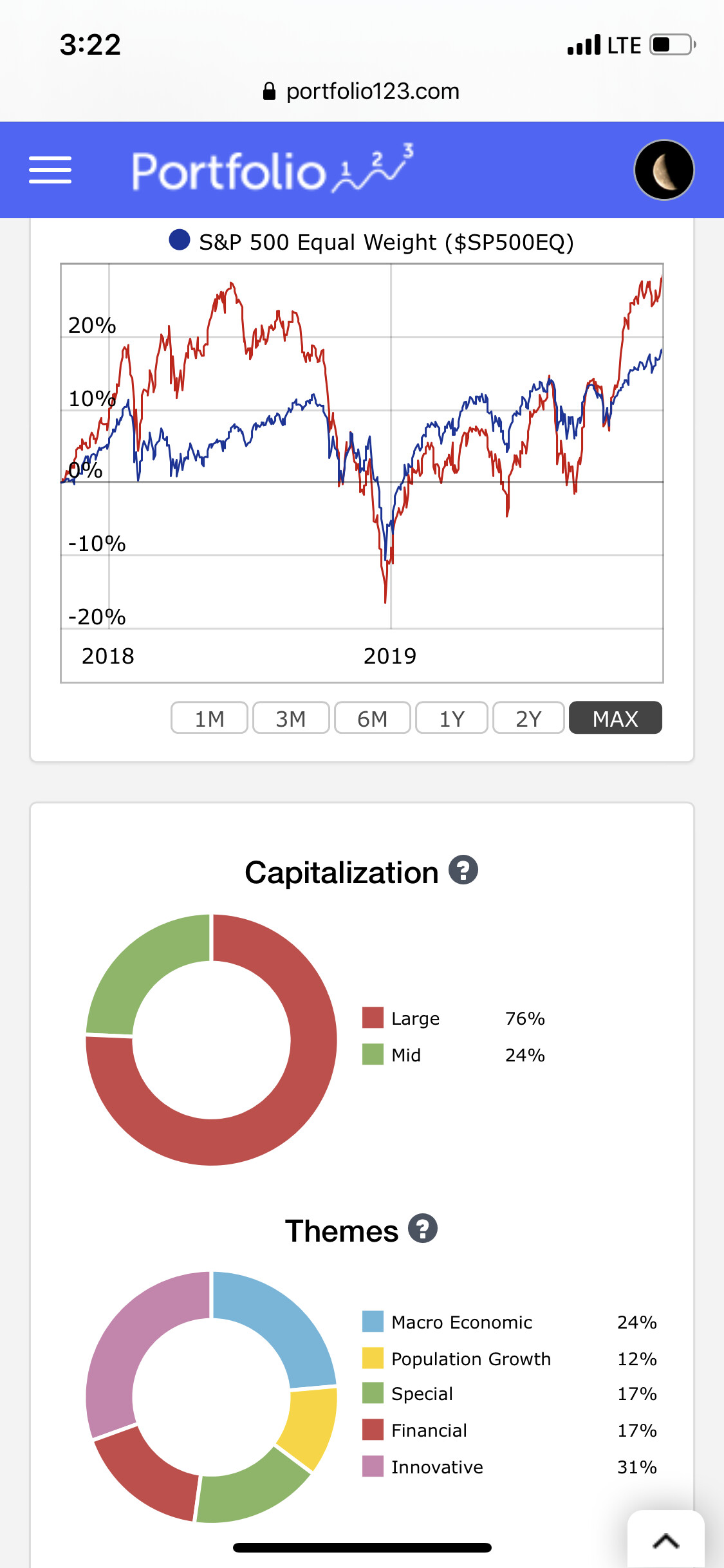
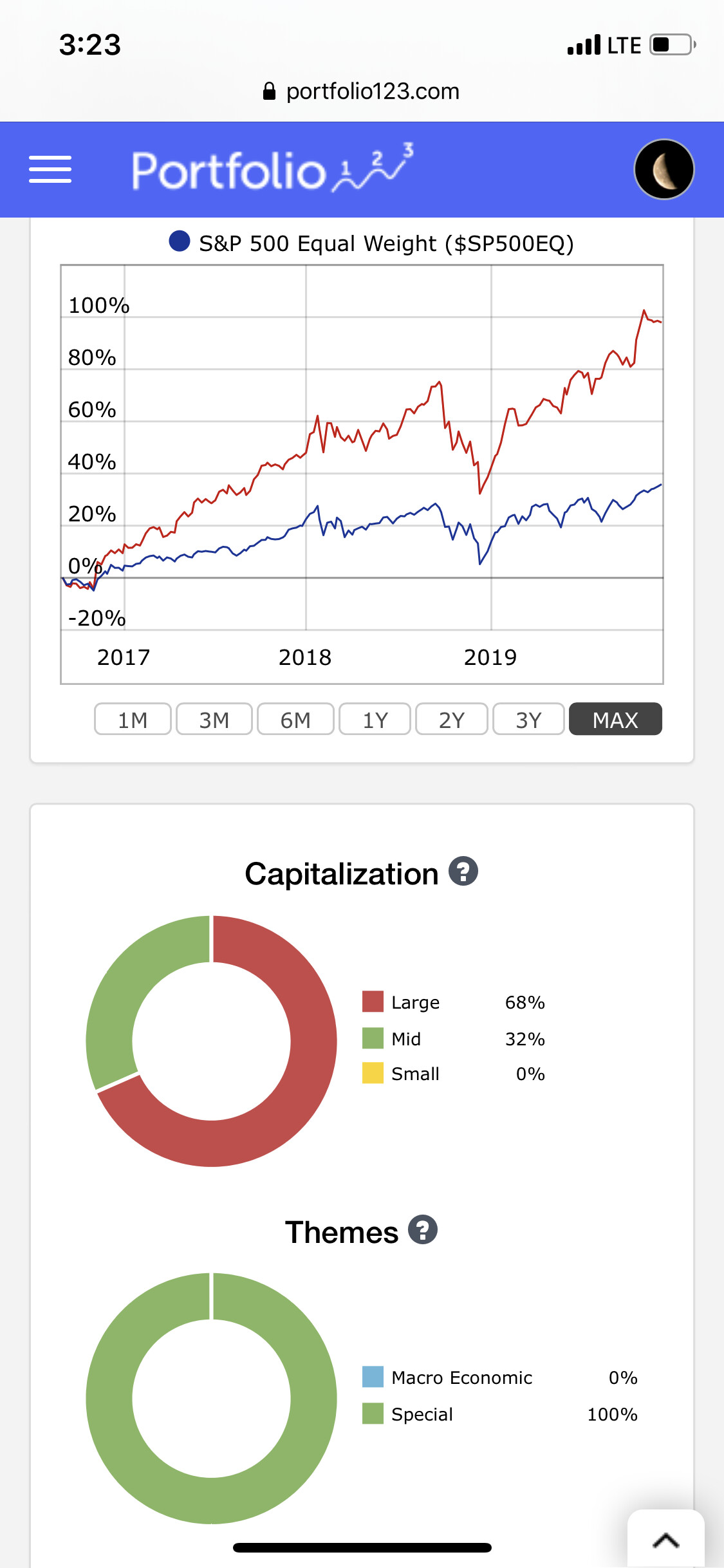
Kumar - I don’t wish to rain on your parade but the claim of “best liquidity models” doesn’t make sense. First of all, 10 stocks is not a relevant criteria. Why not 20? 50? 5? 1? Number of stocks isn’t something to base the selection of a system on. What is more relevant is Alpha, Beta, etc. Looking at the total history of S&P500-10 Stocks Value, Quality & RS, there is lot of Beta but it isn’t clear that there is any Alpha present. Compare this to Inspector Sector’s Aerospace & Defense, a 5-stock model. The indicators next to the model tell you everything you need to know in terms of risk and ability to trade. (See attached).
Your model is awesome with 5 high quality stocks and it is belongs to same sector/same theme. If this particular sector broke, not sure the model will swim against downtrend sector.
My model has diversification with 10 stocks. There is no filter on sector and industry. Only have avoid over weight filter on sector and industry.
If one company go to bank corrupt my model will loose 10% of assets, your model will loose 20% of assets.
In simulation your model took 4 years to get again all time high. My model in less than a year. From 2008 market melt down.
Definitely, I will Learn the quality and momentum from your model.
If you able to achieve same kind of out of sample straight performance curve with 5 sector theme diversified and 10 stocks; i will be your subscriber.
If your model has diversification then the benefits are not readily apparent. Repeating myself, you have high beta, but not high alpha. I reach this conclusion simply by looking at the equity curve since launch. It is not a question of how many stocks the model is holding.
That’s why it is limited to 5 stocks. This gives plenty of opportunity to diversify your investments across multiple models targeting industries with higher than normal growth expectations. The point is to not put all your eggs in one basket. You don’t want to hold one model with too many stocks betting on one strategy that may break at any time.
Investors should also consider the intelligent targeting of industries, not blind trust to whatever industries your model decides to diversify across. We are in a trader’s market and can’t afford to pursue strategies that are not focused.
Aerospace and Defense is a great place to allocate funds while a Republican president is in office. As an engineer who worked in that industry, I learned this the hard way that funding was not forthcoming through the 8 years of Obama administration. If Democrat POTUS arrives in 2020 then one should scale back on A&D. A republican POTUS on the other hand will keep the floodgates open.
Cybersecurity is another industry worthy of pursuing. Healthcare will be a bonanza if POTUS is a democrat in 2020. I can think of a few other industries worth targeting but I don’t want to give away all my ideas.
Your idea is best, it is backed up by your 4 decades of experience with the market and you are with P123 over 15+ years.
I am amazing to see, you are working on new designer model using new ideas. No Sunday to Sun and Steve!
Fidelity sector has 41 ETFs which is investing only 61 industry out of 155 total industry.
IBD50 find 20 industry as growth industry out of 155 total industry.
Still, I need to find a way how the Fidelity
find 1/3 as profitable industry.
In other words how the filtering out 2/3 as weed industries