Nasdaq has a tracker that shows how much volume of a stock is from retail flows.
could be interesting as more retail flow = more likely to be mispriced.
Nasdaq has a tracker that shows how much volume of a stock is from retail flows.
could be interesting as more retail flow = more likely to be mispriced.
Looks interesting . It’s cheap for individuals $10/mo or $100/year. For us to get it would be very expensive.
https://data.nasdaq.com/databases/RTAT/data
Right now you can import the data manually using “Imported Stock Factors”, but it would be cumbersome to keep it updated. But for what looks like $10 you can download the full history and see if it has any value in backtests.
NOTE: We are planning several upgrades of “Imported Stock Factors”. Mainly: 1) automation so that you could just enter your API key and we would updated the data automatically 2) rearchitect to handle lots more data. Right now it has problems handling millions of imported factors. For this dataset it should be ok I think.
Let us know if you need help
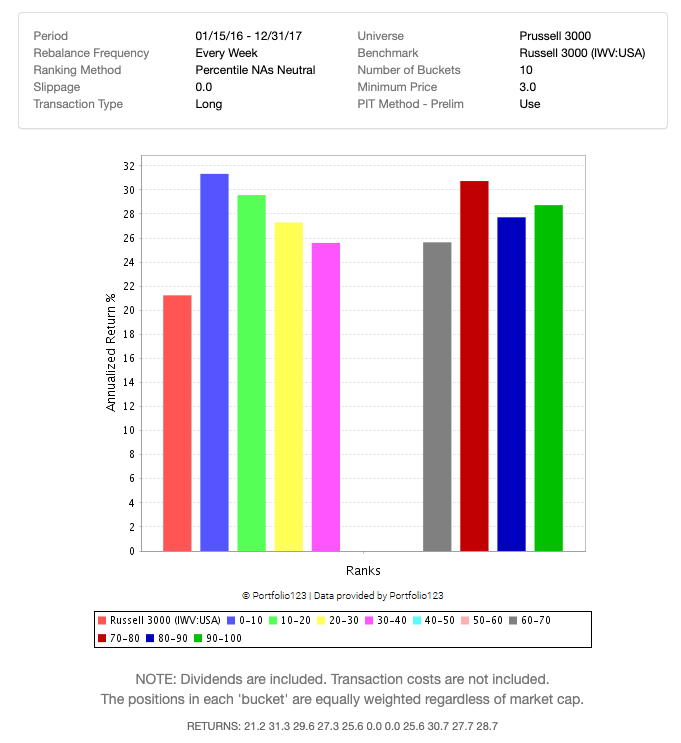
I purchased this dataset and imported as a personal stock factor to evaluate it for personal use. Here are my initial thoughts, having only looked at the first two years of data (01/15/16 - 12/31/17).
There are two factors in the RTAT dataset: activity and sentiment, sampled EOD for an average of 7500 US stocks and ETFs. Without additional filtering, each factor would require about 1.89 million samples for a single years worth of data, so you could only fit about 5 years of a single factor in your account’s allotted 10 million samples of imported data. To ameliorate things, I resampled the two factors weekly, using a rolling 10-day average for the activity factor to match how sentiment is calculated by Nasdaq. This would allow one to have about 25 years of a weekly sampled factor (for this universe size). Curious how much the planned p123 improvements to stock factor handling would relax some of these limits.
The activity factor looks flawed in its current formulation in that it’s biased toward higher cap, higher volume stocks. It looks at the ratio of the symbol’s retail volume to all retail volume without normalizing for the symbol’s overall volume. Higher volume stocks will naturally have a higher percentage of overall retail volume. More egregiously, 62% of all activity samples are exactly zero, so I’m not sure if they have a rounding issue, if there is imperfect heuristic in how this is being estimated from SIP data, etc. For stocks outside of the Russell 1000, it seems unlikely to yield many non-zero values.
The sentiment factor looks like it has much better coverage. But initial rank performance testing on the Russell 3000 doesn’t look too promising out of the box — at least when limited to this initial period.
For now, I will likely shelf this dataset, but I wouldn’t dismiss its potential utility just yet.
And some feedback for the p123 team after my first time using the imported stock factors feature in earnest.
You should be able to specify a universe when uploading a stock factor so that it can be downsampled on-the-fly to that universe to reduce the number of rows.
An upload with “Existing Data” set to “delete” should be allowed if subtracting the current number of rows from your account utilization would drop you below the 10 million limit. Right now, you have to completely delete the factor and its metadata and recreate it from scratch if you are over the limit.
The Data View page doesn’t work for imported stock factors.
Imported factors will always be necessary for bespoke datasets. But for vendor data like this, It’s not very scalable for N users to each have D datasets stored in p123’s database. Ideally, it would be nice to expose a marketplace where users could subscribe through p123 for access to private datasets for their personal use, whether these come from the FactSet Marketplace or other 3rd party vendors. This could also be a way to monetize the process that the current approach does not provide.
I’m wondering why P123 does not consider to collect/manage alternative data from various pubic sources.
This is quite a hot business nowadays. An example is a recent acquisition of UK-based startup Urgentem by ICE.
Their simple business relies on collecting emission data (scope 1,2,3) from financial statements + plus portfolio analytics.
Here are some examples of the data to be collected for each company:
Some startups get lucky, hit the vein, and make it look simple. We’ve always chosen the hard way.
Joking aside we just don’t have the people to do it at the moment.