Doug,
Here is the article from WSJ. Like my post earlier, it highlights the difference between backtest and out of sample performance this time for AI.
Regards
James
Use AI for Picking Stocks? Not So Fast
AI investing strategies, when put into practice, don’t produce particularly unique portfolios, a new study finds
By Mark Hulbert
Jan. 5, 2020 10:06 pm ET
Artificial intelligence burst onto Wall Street several years ago, to fanfare and hope. Unfortunately, AI-based investing strategies have struggled to live up to some of the more inflated expectations for their performance.
There is no denying these strategies’ theoretical promise. By being able to sift through otherwise prohibitively large amounts of data, and then “learn” from it, AI is supposed to be able to discover profitable patterns that were previously invisible to mere mortals.
And, sure enough, they appear to have done so—on paper. Doron Avramov, a finance professor at the Interdisciplinary Center Herzliyah in Israel, says that when tested using historical data AI strategies have been phenomenally successful, beating the market by as much as 40% on an annualized basis.
No other approach has come even close to producing that kind of a profit.
Making this market-beating potential even more alluring is the deteriorating profit of many of the well-known factors (or stock characteristics) that previous research had identified as having value when picking stocks—such as momentum, market cap, volatility, low ratios of price to earnings, book value, sales and so forth. Researchers have found that more than half of the paper profit that initial studies reported for those factors disappeared when they were put into practice.
Unfortunately, according to a new study recently completed by Prof. Avramov and two colleagues ( Si Cheng of the Chinese University of Hong Kong and Lior Metzker of the Hebrew University of Jerusalem), the same thing is true about AI strategies. In the real world, their market-beating performance almost completely disappears.
INVESTING IN FUNDS
Reality check
Prof. Avramov and his colleagues reached this conclusion after re-creating several different neural networks (a set of algorithms designed to recognize patterns) and other machine-learning techniques that past AI researchers have found to be worthwhile. They then fed into these networks virtually all of the indicators that previous research had found to have at least some value when picking stocks—more than 100 in total. They then “trained” their network on a database of U.S. stocks dating back to 1957, looking for interactions between, and combinations of, these indicators that were more profitable than any of them individually.
A number of alarm bells started going off as they examined the portfolios that their networks produced. For example, they noticed that much of the portfolios’ paper profits were coming from microcaps—stocks with tiny market caps. That’s troublesome because so few shares of these stocks trade that it’s difficult to establish a sizable position in them without causing their prices to skyrocket. It’s also difficult to borrow shares of these stocks when you want to sell them short.
This heavy reliance on microcaps is just one way in which the AI strategies often make unrealistic assumptions about the real world. Upon restricting their AI strategies to stocks that were relatively easy and cheap to trade, Prof. Avramov and his colleagues found that more than half of those strategies’ paper profits disappeared. And that was before transaction costs, which could easily eat up the remainder of those strategies’ theoretical profits—given that machine learning generates much higher trading volume than that of conventional strategies such as momentum and value investing, according to Prof. Avramov.
Mediocre machines
A perhaps even more surprising conclusion from the study is that the portfolios the AI strategies produced weren’t particularly distinctive. On the contrary, Prof. Avramov says, they were quite similar to portfolios produced by the well-known factors. In other words, these machine-learning techniques largely failed to live up to their promise of finding previously hidden patterns in the stock market.
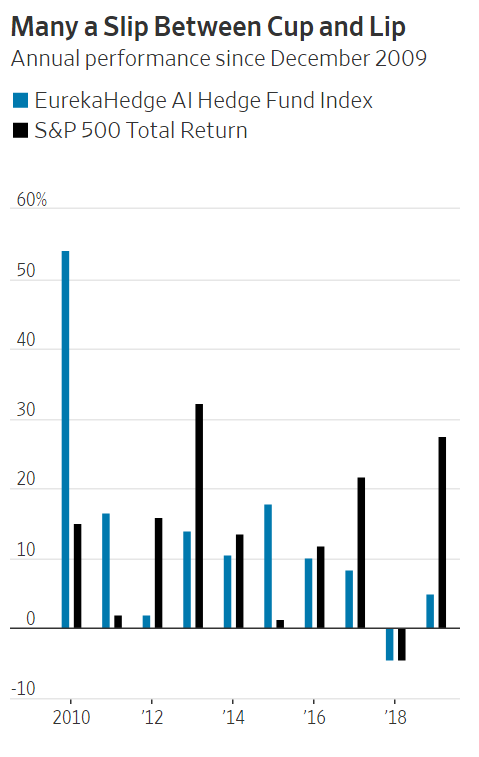
All in all, it appears that there is “many a slip between the cup and the lip,” to quote the ancient proverb.
This perhaps helps to explain why hedge funds that employ AI haven’t outperformed the S&P 500 over the last decade. Consider the Eurekahedge AI Hedge Fund Index, which “is designed to provide a broad measure of the performance of underlying hedge-fund managers who use artificial intelligence and machine learning theory in their trading processes.” Since its inception in January 2010, the index has produced a 12.7% annualized return, in comparison to a dividend-adjusted 13.3% for the S&P 500.
These results don’t mean that AI is worthless, Prof. Avramov is quick to add. “It’s just that its potential has yet to be proven,” he says. “AI definitely has promise, perhaps not just as much promise as some have made it out to appear.”