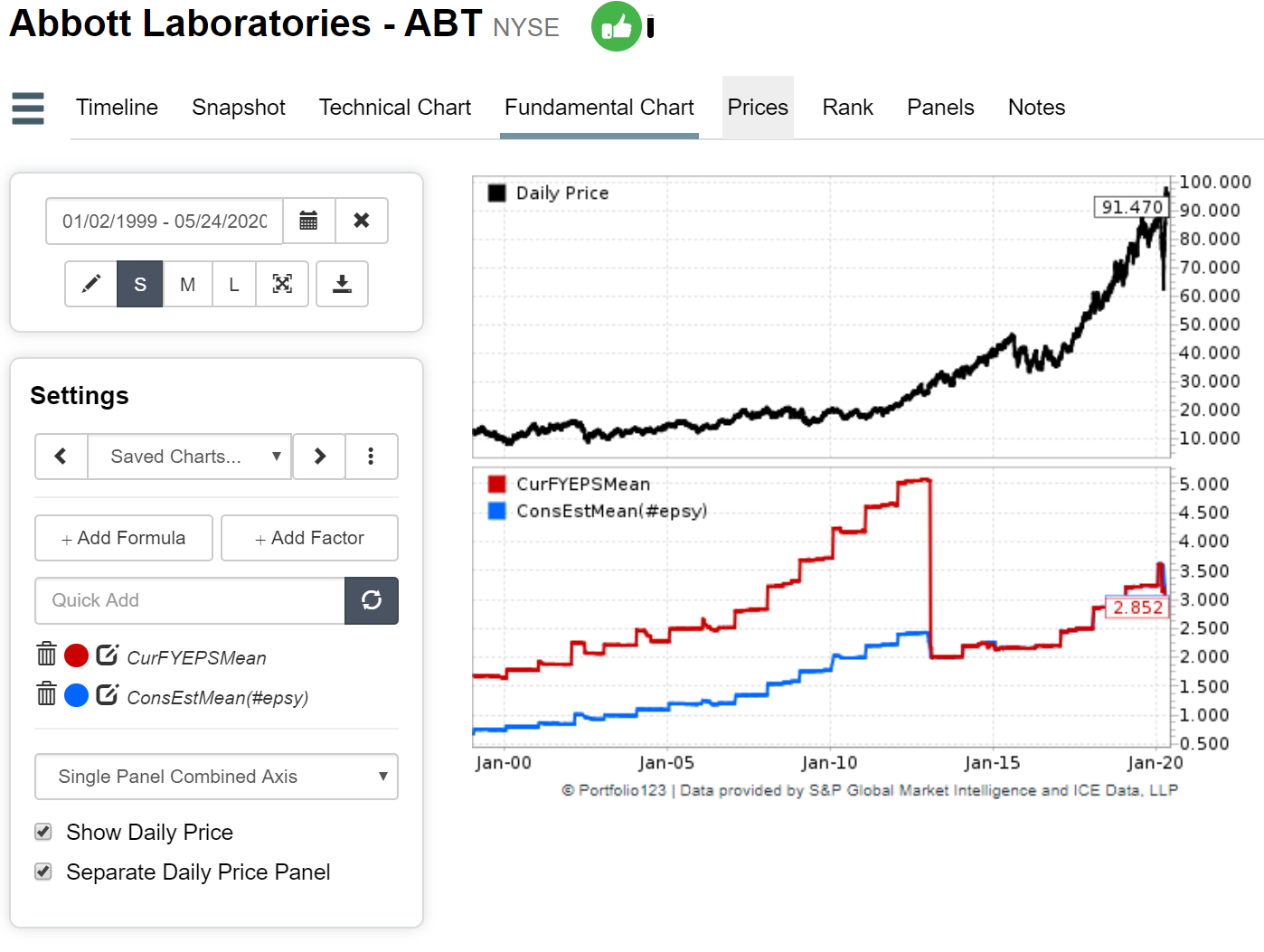
These consensus functions only pull in FactSet data even if you point your engine to Compustat. This is pretty handy since you can compare the values and it’s helping us find issues. See image below. With the engine set to Compustat I charted these factors for ABT
CurFYEPSMean
ConsEstMean(#EPSY)
As you can see there’s a big jump in 2003. This is due to the ABBV spinoff. While Factset , like Compustat, has point in time estimates they adjust all past values when splits/spinoffs occur. This makes it easier in the present to chart a smooth graph but requires adjustments with a point in time engine. Compustat is the opposite.
We are adjusting Factset data for splits, but just figured out we also need to adjust for special dividends due to spinoffs.
Could you explain how the new revision ratio factors work? I’ve discovered that ConEstDn has been implemented, even though it wasn’t in your original post. And I learned by trial and error that the acceptable parameters for “weekAgo” in up/down revisions are 0-3. But I’m not certain what periods these values refer to. I’m intrigued by the increased granularity these factors offer, so I’d like to be clear on how they’re working.
Not sure how ConsEstDn & ConsEstUp work yet. We’re just exposing whatever they give us. I think we need to add up all the values they give us during a period to replicated something like “Up revisions past week”
FWIW, my best guess based on the pattern of the data was that the “weekAgo” parameters designated cumulative periods: 0, the latest four weeks; 1, three weeks excluding the latest week; 2, two weeks excluding the latest 2 weeks; and 3, four weeks ago. But that seems counter-intuitive, so I will be curious to see what you find.
Wrote about this in another thread, but wanted to mention it on this thread as well. I am seeing significantly more Turnover (~400% more) in Sentiment based models using the FactSet Estimate data as opposed to the Compustat Estimate data. Not sure what would cause this, but think it might be something worth looking in to.
With regard to estimates we should rule out a simple possibility.
It is a simple truth that doing a sim with look-ahead bias will perform well (falsely).
This (from FactSet) is also true (I assume they know):
“The traditional FactSet Estimates Database uses the “Research Date,” or the market date of the broker contribution, to calculate the consensus. This exposes a look-ahead bias because most research dates are T-1 day of the broker contribution’s “Input Date,” or the date when the contribution was collected into the database. Clients have the option to use the “Input Date” to calculate their consensus to eliminate the look-ahead bias of including contributions in a consensus before the date they were collected.”
I submit that P123 probably chose the PIT data if given a choice or that perhaps the default “option” is to have it be PIT and that this “option” was selected as the default.
It may be that FactSet uses a different method than CapitalIQ. FactSet data can be PIT. I will have to see evidence before I believe that Capital IQ uses the same method as FactSet’s PIT method.
Summary: make sure this is not a good thing that P123 would want to take credit for. I cannot be sure which “option” was selected but perhaps there is general agreement that PIT data is a good thing.
Appreciate your thoughts on this. In my opinion, what I am seeing is most likely caused by something different than just the Input or Research Date issue.
There appears to be significantly more volatility in the Estimate Data provided by FactSet which is born out in a significant increase in the rate of change in the relative ranking of Stocks based on Sentiment (which is based on the Estimate Data). I am not sure why the Date used would have much impact on the rate of change of rank for the stocks in question (P123 LargeCap Universe). For me this increased volatility is not a positive outcome as it seems to both significantly increase Turnover (a huge pain) and significantly decrease Performance.
My question is why would the Estimate data be more volatile? Does FactSet update Estimate data more regularly than Compustat? Does FactSet have fewer analysts per company than Compustat thereby making Consensus Estimates more volatile? Or is it some kind of Data Provider to P123 interface difference. I believe the cause is important to understand.
I will try to spend a little more time on this today digging in to the underlying data, but would be curious to hear from any P123 staff before then if there is a known issue.
I suspect your impression is correct and a better reason will present itself.
Be aware that you will probabLy leave a position A WEEK EARLIER (or possibly enter it later) when there is a discrepancy between the PIT and traditional data. And this effect could be significant if there are preferred days for reporting by analysts. It would be surprising if there are not preferred days for estimates as there are clear preference for the days that companies report
Again your belief is probably correct but this fact is why I post here. Furthermore, I think others are asking questions about the data discrepancies.
I submit that P123 should call FactSet if it does not know which option it took (or find out if there is no longer an option) and should think about sharing that information with us.
And again, this could only be good for P123. Unquestionably good if it is confirmed to be the PIT option. And either the data is more or less like we have been using (okay) or it is better (great). Win-win-win. I would leave it alone otherwise.
After digging a bit more into this it seems that the increased volatility in Sentiment Ranks (which leads to increased Turnover in a Sentiment driven portfolio) is being driven largely by the “Estimate Revision” node in the Sentiment Ranking system. As described by Yuval elsewhere on this forum, the Factset engine is not correctly applying stock splits or dividends to the estimate data which could be the cause of this problem (i.e. artificial changes in Estimates increasing Estimate volatility). As such, I’m going to stop work on this until that bug fix is completed, and see if it fixes the problem.
That shouldn’t affect estimate revisions, only yearly estimates of stocks with subsequent splits or spinoff activity. Dividends aren’t actually a problem after all–I spoke/wrote too soon.
If we take the case of AAPL, in FactSet the 2010 CurFYEPSMean is given as 1.87 versus 13.14 in Compustat. Since the current CurFYEPSMean is given as 12.35 in both systems this would imply that the FactSet Earnings Estimates have an implicit upward bias that is not present in the Compustat data. If we extrapolate a step farther one could reasonably assume that a number of companies have an implicit upward (or perhaps downward in some cases) bias in their FactSet numbers. This bias would introduce more volatility in the Earnings Estimates over time, and would possibly show up as increased variability in the Earnings Revisions node Rankings inside of the Sentiment Ranking System. Obviously the easiest test for this will be seeing if the increased variability in Rankings disappears when the bug in question is fixed.
If I am in fact incorrect in my assumption here, do you have any thoughts on what would be causing the increased variability in Estimate Revision rankings? Note that the Current Date Estimates provided by FactSet and Compustat for the P123 Large Cap are basically identical, which to me implies that the problem is something to do with how the FactSet Earnings Estimates are changing over time.
I’m as mystified as you are, Daniel. Can you please show me how you figured out that increased variability in the P123 ranking system is due to FY estimate revisions? The reason why I don’t think the bug is at fault is that the difference between CurFYEPSMean and CurFYEPS4WkAgo is just as large/small whether you adjust for subsequent splits or not. And there’s no reason to assume there’s an implicit upward bias since there are plenty of companies with reverse splits. And that bias wouldn’t explain increased variability in this one measure.
Yuval, didn’t do anything especially fancy to come to that conclusion. I have a very simple model that buys the top 25 stocks according to a ranking system and sells then when their RankPos drops below 100. I am running that model on the P123 Large Cap Universe and using the Core: Sentiment ranking system.
If I run that model on the Legacy engine then I get a Turnover of ~800%, but if I run the same model on the FactSet engine I get a Turnover of ~… well shit nevermind the higher turnover is gone… What did you guys change over night??? Whatever it was completely fixed the problem.
Lol
Well this is definitely a good thing, but I kinda hate myself for spending so much time on this now.
I need to apologize for not knowing exactly what I was saying earlier. I now have everything clear. Here’s what’s going on.
All estimate numbers for FactSet stocks reflect FactSet data EXCEPT for estimate revisions (functions like CurFYUpRev4Wk), which are still powered by Compustat.
The ConsEstUp and ConsEstDn functions are under review. We’re not precisely sure what those functions are doing, even after talking with FactSet about it. We’re hoping we can use them to get the equivalents of Compustat’s estimate revisions; if not, we’ll figure out some way to get that data.
The estimate revisions in the P123 Sentiment ranking system are entirely different from the estimate revisions given by CurFYUpRev4Wk and so on. The ones in the ranking system are based on changes in CurFYEPSMean. Those are powered by FactSet, not Compustat, numbers. The estimate revisions under EPS REVISIONS in the Factor & Function Reference are based on the number of analysts changing their estimates, not on the mean estimate.
I hope this clarifies things and again, I apologize if I misstated things earlier.
Can you help to get the correct FHist formula for both cases? I am really struggling to get it right. Also the past comment of Marco “I would NOT use FHist with estimates” makes me a bit uncomfortable.
Marco said that because if you use it wrong, you’ll end up with the wrong quarter’s estimate. ConsEstMean(#EPSQ,0,13) will be totally different in most cases from FHist("ConsEstMean(#EPSQ,0),"13) because the first will point to the most recent quarter and the second will point to the quarter before that in most cases.
For the first case, this should work pretty well: Eval(LatestActualDays=NA, NA, FHist(“ConsEstStdDev(#EPSQ,0)”, Trunc(LatestActualDays/7 + 1)))
For the second, it would be more of a guess–use the same formula but + 14 in place of + 1.
Perhaps we should enable -1, -2, -3 etc in the second parameter. But we haven’t done so yet, and I’m not sure when we will.
As always with FHist, you need to watch out for splits. FHist never adjusts for those.