AIFactor() is for predicting using a trained Predictor. This is what you need for generating current predictions. For backtests use AIFactorValidation() which accesses the prediction data saved during validation, and it's very fast. The latter is very strict since the rebalance dates must line up.
Looks like you are using AIFactorValidation() instead of AIFactor(). Train a predictor then use AIFactor() in the ranking system.
Make sense?
PS. You can use AIFactor for backtests, but only up to one year in the past because it is too slow and often fails (we'll open it up some to 5 years soon).
@marco, how does factor z-score normalization work with the AIFactor function? If set to by date, is it recomputing trim and standardization levels as of the prediction date? And what about the case where normalization is done over the whole window?
And to follow up on that, what is the workflow to take a strategy from simulated to live? Normally, you can just save a simulated strategy as a new live one, using the same ranking system. But will you have to manually create a 2nd ranking system suitable for live trading by substituting AIFactorValidation() references to AIFactor()? Sorry if this has been addressed elsewhere, just trying to wrap my head around the current state of affairs.
By Date does indeed recompute any normalization factors (e.g. mean and standard deviation for Z-Score) using the prediction data. As for Entire Dataset, the normalization factors are computed over the entire dataset during dataset load and are are never recomputed after that.
As for simulated to live, there's currently no convenient transition from validation work to predictors. As Marco mentioned, the AIFactor() restriction will be loosened a bit to permit research using on-demand predictions. Just be aware that AIFactor() will not allow you to request predictions for dates within the training period, so if you really want to run a 5-year backtest, the data you'll have trained on would be at least 5 years old.
We've entertained the idea of allowing one to save multiple splits for a predictor to allow you to backtest just like you can with AIFactorValidation(). But even in that case, you'd be omitting the most recent data for the latest model. We'll just have to see if more core functionality would be needed after the AIFactor() restriction is loosened to 5 years.
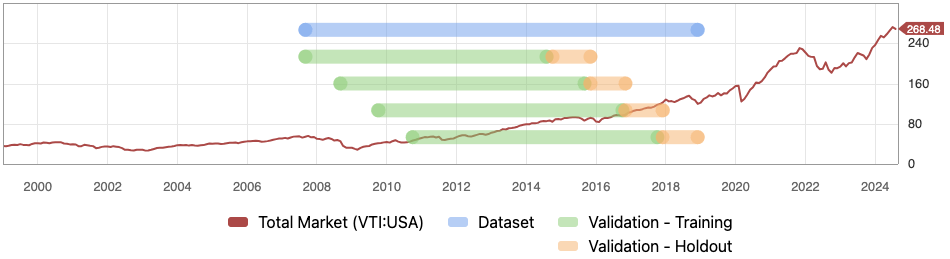
To clarify, does "by date" normalization just use factor values as-of that single date for prediction? Or up through that date, i.e. an expanding window? And I assume whichever the answer is that the same process applies during model training? For example, if I'm using rolling time series validation in the picture below, does "by date" normalization for the first green training window normalize each day's data point using only that day's factor values? Or is it using an expanding window within the training period?
Regardless of the answers to the above, I worry there's a subtle lookahead cheat if one uses the "entire dataset" z-score normalization. In the same example, the normalization would be done from standard deviations and trim levels computed over the entire blue ~2008-2018 window. And for the first yellow holdout window (which looks to roughly be 2015), you'd be normalizing predictors using these future-peeking stddev/trim values. This is not as egregious a cheat as making predictions for samples included in your training set, but nonetheless, it's not behavior that you can replicate in live trading if I'm correctly interpreting what "entire datasets" normalization is.
By Date is always handled on a per-date basis. Since preprocessing happens during dataset load and dataset load can be done before setting validation method, its behavior does not change between validation methods.
Regarding preprocessor lookahead, we went in this direction to keep the implementation/storage requirements simple. Imagine training 10 models with 10 folds. It would either have to store 10 different cached preprocessed dataset segments or run the same exact preprocessing 100 times. So this implementation accepts this spoiling of normalization factors with some future data in order to avoid having to solve the problems for the alternative.
Please correct me if I'm wrong but there is no way to run a simulation using the AI factor with Rolling Time Series CV? That is the reason for your remark above?
AIFactor(): returns the predictions from a trained model (a.k.a. a Predictor) in the Prediction tab. It's an expensive operation since it involves sending the dataset for the chosen universe to the AI backend, normalizing the data, unpickling the predictor (the "executable"), and calculating the predictions.
AIFactorValidation(): returns the saved predictions from a validation of a model in the Validation tab. It's very fast since it does not involve inference, but lacks flexibility (your backtest dates must exist for example)
He's simply saying that to use a Predictor for the past 5 year for example, you would need to train it with data older than 5 years. You will get an error if you try to get predictions using training data for obvious reasons: you will get amazing results.
And yes, you cannot run a simulation to recreate the (for example) High Portfolio of a Rolling Time Series CV at the moment using AIFactor(). You can only do it using AIFactorValidation().
Could you let us know if it's possible to combine two AIFactorValidations within either the screener or the simulation engine with the new feature release? If so, could you demonstrate how?
Additionally, what are your thoughts on the realism of the screener? I haven't typically relied on it based on P123's guidance, but it seems closely tied to the AI Factor. I haven't found a way to verify AIFactor features through simulation as we can with the screener.
@korr You can use AIFactorValidation() in a ranking system like you would any other P123 function. This includes using them in a stock formula within a ranking system and then using that ranking system in your simulation. You could also use AIFactorValidation() within the Buy and Sell rules in the simulation. But be aware that AIFactorValidation() only has values on the validation holdout dates generated based on combination of the period and rebalance frequency used in the AI Factor when you ran the validation. Trying to reference AIFactorValidation() on other dates will result in an error. For example, you would get an error if your rebalance frequency was every 4 weeks in the AI Factor but you try to run a simulation using AIFactorValidation() that rebalances weekly.
Hi @danp, thanks for the reply! It can be a bit tedious to get the universe set up correctly, but it’s great that it works!
Is there a similar method we can use for Long Short Simulations, like with the screener? I've never had much success running those two simulations independently and then combining them but with the AI Factor, it seems like a more useful and perhaps necessary implementation.
@korr123 For long short simulations you need to create a sim for the long side and one for the short side and then add them both to a simulated book. A common problem with this is that the short simulation will not run to completion because it has long periods of losses which causes the strategy to go down to $0 which causes the sim to fail. But perhaps with AI we can find short strategies that can stay solvent during bull markets.
@danp Thank you for the explanation! I noticed that in the long short portfolios section of the AI Factor, we're not seeing the portfolio going to zero. When we run the long short screener, it seems to somewhat mirror the AI Factor portfolios page.
Since P123 has always advised relying on simulations for accurate backtests, could you guide us on how to create that portfolio's "Hi-Lo" section using the simulations engine and AIValidation? I'm concerned that the AI Factor HI/LO and Screener results are not built to have real money follow them - this is why we have the simulation engine, right?