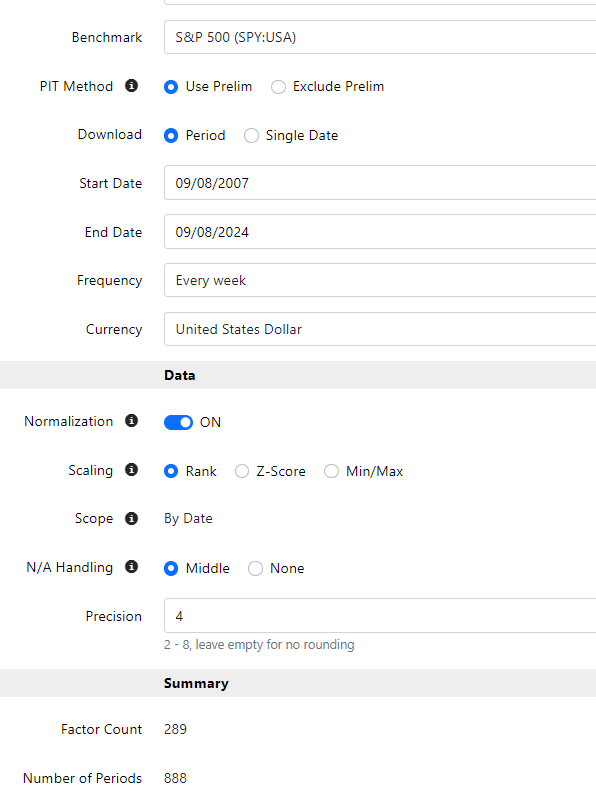
In column D, I have three months of future relative returns compared to SPY( FutureRel%Chg_D(65, GetSeries("SPY"))).
What if I
Filtered out the 5,000 best performers from a total of over 100,000 lines in column D.
Then, I add a new row nr. 1, that sums the number of normalized values that are 1 for each factor (feature). (I may have misunderstood this, but 1 is the highest score each factor can achieve.)
Then, I create a ranking system based on, for example, the 40 nodes that have the highest number of 1s among the 5,000 best performers.
Wouldn't that provide a very good indication of which of my 300 features (nodes) perform best in relation to future three-month returns?
The idea here is that the features with the largest amount of 1 in the 5000 best performers give a indication of what characteristics that would be a part of the winning stocks.
But would a large enough sample base—even more than 5000 help to model away from fitting the strategy to the "winning lottery tickets"?
One question, when you normalize numbers, am I correct in understanding that 1 is the highest. So if the stock factor (node) is a measure of high insider buying, the largest amount insider buying in the sample set will get a normalized value of 1?
As I recall, the machine learning model trained on the 1/5th of the stocks with the highest future returns in the paper I'm talking about got OK returns, but they were extremely volatile, and the return-to-risk ratio was not even as good as the model trained on the 1/5th of the stocks with the second highest future returns.