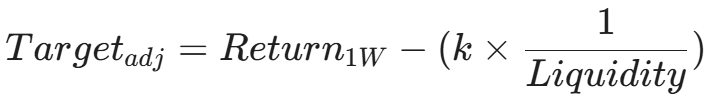Had a chat with Gemini about modeling slippage and turnover for illiquid stocks in to (Linear) AI models to the rank engine. Got a few interesting technique ideas. I before spending time testing them I want to hear what the community has to say about them.
_____
Does Liquidity-Adaptive Smoothing use "Old Information"?
Short answer: Yes, but that is a feature, not a bug.
In quantitative finance, there is a fundamental trade-off between Responsiveness (using the latest data) and Reliability (avoiding noise).
By using an EMA (Exponential Moving Average) for your scores, you are introducing Lag. However, for illiquid stocks, "Fresh Information" is often just "Microstructure Noise."
-
Why Lag is acceptable for Illiquid Stocks: Illiquid stocks have high transaction costs (slippage). If you react to a "fresh" signal and buy on Monday, but the signal disappears by Friday, you have lost 2–4% in slippage for zero gain. The smoothing forces the stock to "prove" the signal is persistent. You enter a bit later, but you enter with much higher conviction that the move isn't a one-day fluke.
-
The "Speed" Control: Because the smoothing is adaptive, you aren't using old information for the whole portfolio.
-
Apple (AAPL): High liquidity = High alpha (e.g., 0.9). You use 90% of today's new ML score.
-
TinyCorp (XYZ): Low liquidity = Low alpha (e.g., 0.2). You only move the needle 20% toward today's score.
The result: Your "Turnover" (and thus your slippage cost) drops significantly, while your "Alpha" (returns) usually stays stable because you are only trading the most persistent trends in the small-cap space.
____________________
Volatility-Weighted Training (Sample Weighting)
In your MetaModel (ElasticNet) and SequentialNodeBuilder (Ridge), you can use the sample_weight parameter during fitting.
-
The Concept: Tell the model to pay less attention to the volatile/illiquid stocks during training.
-
Implementation:
-
Result: The model minimizes error primarily on stable/liquid stocks. For illiquid stocks (which have low weights), the model produces a "flatter" (more conservative) prediction because it isn't trying to chase every random spike in their data.
Expanding on Volatility-Weighted Training
In your current code, every row (every stock on every date) is treated as equally important by the Ridge or ElasticNet solvers. Volatility-Weighted Training tells the math engine: "I care more about being right on stable stocks than on wild, volatile ones."
How it works mathematically
Standard Linear Regression tries to minimize the Sum of Squared Errors (SSE):
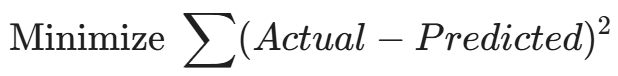
In Volatility-Weighted Training, we add a Weight ($w$) to each row:
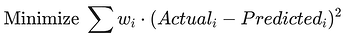
If a stock is highly volatile or illiquid, we give it a low w. The model will essentially "ignore" the errors it makes on that stock to focus on getting the high-weight (stable) stocks correct.
Why this helps you
-
Reduces "Coefficient Hijacking": A wild penny stock that jumps 500% can "hijack" a linear model. The model will change its feature weights drastically just to try and minimize the massive error on that one stock. Weighting prevents this.
-
Improves Signal-to-Noise: Volatile stocks have a lower signal-to-noise ratio. By down-weighting them during training, you are training the model on the "cleanest" part of the dataset.
-
Natural Turnover Reduction: Because the model was trained primarily to satisfy stable stocks, the resulting "Ranking System" will naturally favor features that work in a stable, persistent manner.
___________________
Interaction Features
Since you are using linear models, they cannot inherently understand that "Signal A is only good if Liquidity is High." You must explicitly tell them.
-
Technique: Create "Interaction Anchors" or Support Features.
- Instead of just
SalesGrowth, add SalesGrowth * log(Volume).
-
Result: If Volume is low, the value of this feature drops to near zero. The model naturally learns to ignore the signal for illiquid names while trusting it for liquid names.
________________________
Target Engineering (The "Cost-Adjusted" Target)
Instead of training your models to predict raw 1W_Future_Return, train them to predict Liquidity-Adjusted Return. This forces the ML to "learn" that a 2% gain in an illiquid stock is worth less than a 2% gain in a liquid stock due to slippage.
-
The Concept: Subtract a "Virtual Transaction Cost" from the target variable before training.
-
Implementation:
-
Where k is a penalty factor you tune.
-
Liquidity can be Volume, Turnover, or Bid-Ask Spread.
-
Why it works: If an illiquid stock has a modest return, the penalty drives its target value to zero (or negative). The model learns to only rank illiquid stocks high if their predicted return is massive enough to overcome the penalty. Liquid stocks get a "free pass" and can be ranked high even with smaller predicted returns.