Just starting out my P123 journey, wanting some confirmation my process is correct for optimising factors, and would appreciate your opinions as to whether I’m over-optimising factors that should be trashed.
Currently I have about 175+ factors I’ve populated into a ranking system. I’m now assessing each factor.
Ranking settings: Time Period: Max; Rebalance: Weekly; Ranking Method: NA’s Neutral; Universe: my personal universe I plan to use if I go live (low-liquidity, no REITS, financial, etc).
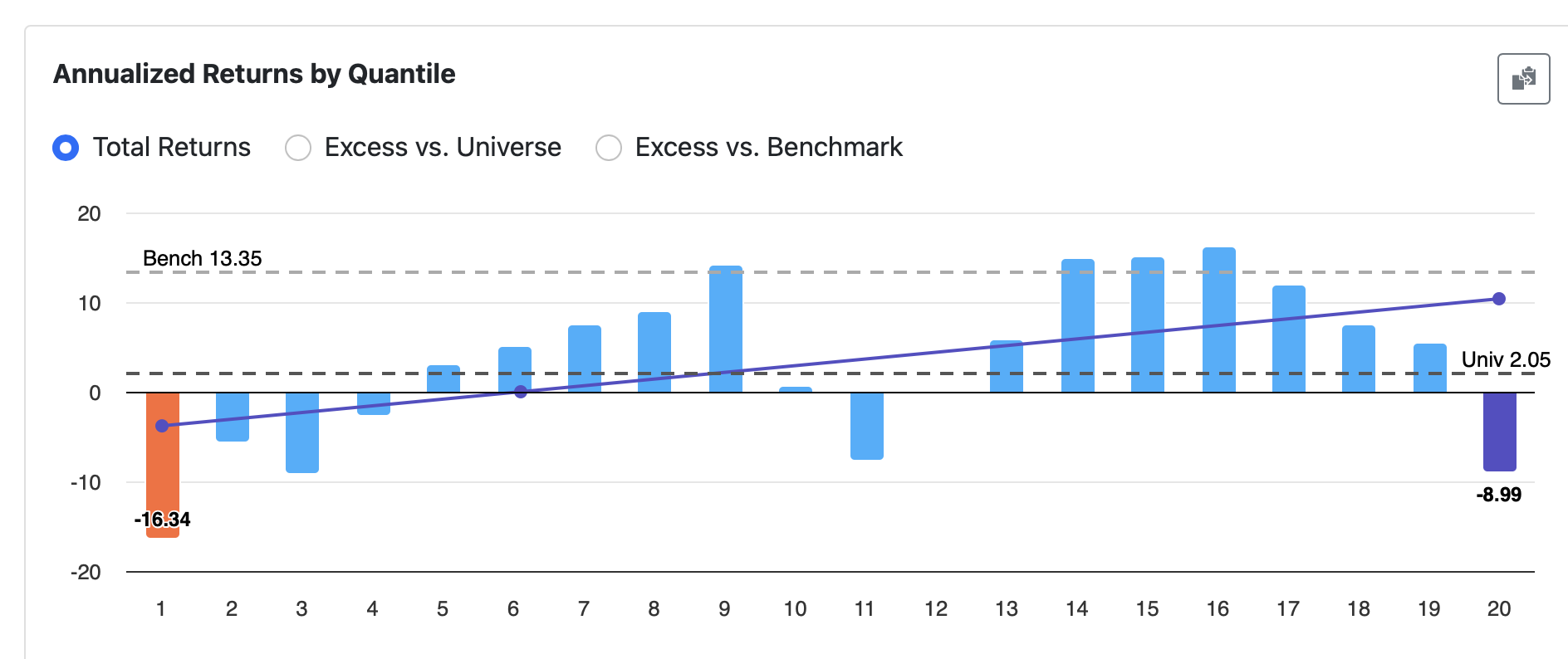
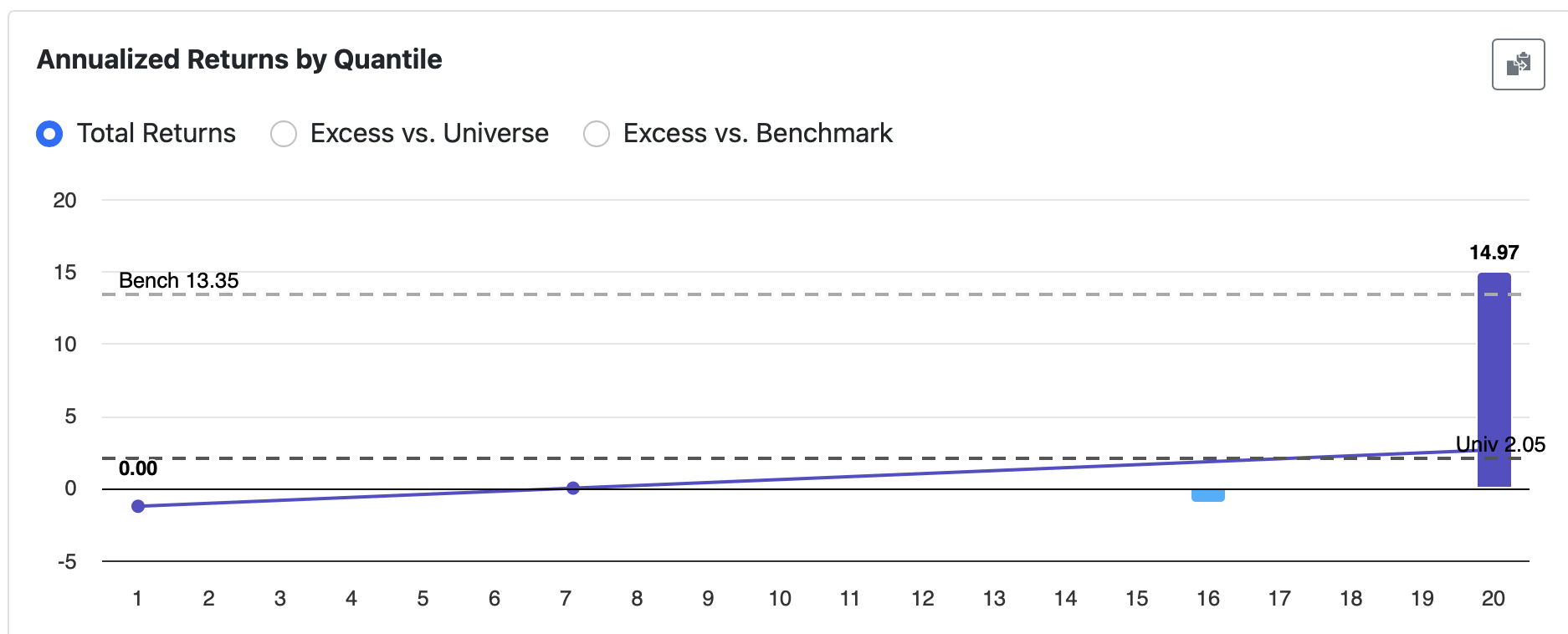
I have quite a few factors which seem quite noisy (see Formula 1: GMGn% below), and so I’m trying to rewrite the factor to select from the higher ranking buckets (see Formula 2 below, selecting from buckets 14-16).
Is this process correct? Is Formula 1’s signal too noisy to be included, or optimised? Is there a better way? I seek your wisdom.
Thanks in advance.
Formula 1: GMgn%(0,QTR) - GMgn%(4,QTR) [higher better]
Formula 1 might be good enough. The rest of your ranking system will probably reward things like stability (including in GM), thus the most extreme increases in GM will not end up with a high total rank anyway.
It could still be a good idea to optimize the FRank-function a bit more. I think formula 2 looks overoptimized, I’d prefer:
abs(frank("GMgn%(0,QTR) - GMgn%(4,QTR)")-80) (with “lower is better”)
(Which gives a maximimal value then FRank() is close to 80, but in a smoother way than using between()).
TL;DR: Tree models were specifically designed to handle features like this.
Nice. But isn’t this exactly the kind of situation tree-based models are built to handle—non-linear relationships like the one illustrated? It’s one of the reasons P123 added the AI/ML module in the first place. Marco has done a great job making ML and tree models accessible to everyone.
If you have a lot of features like that, I’d suggest just trying a tree model—see if it works for you.
Thanks Jrinne. I appreciate your response. I’ll have to build up the courage to look at tree-based models.
You mentioned in your initial post mutual info regression, which is a new concept for me. Is that a tool I can plug a bunch of factors into to assess the quality of their signal?
On a seperate note, Jrinne your many posts on this forum have been a great learning tool for me. Appreciate it!
You’ll notice I actually removed the mutual_info_regression reference from my post above (before your reply). On reflection, I do think it can be a useful tool, but I hesitated to give it an unqualified recommendation because of a key limitation:
mutual_info_regression works well for evaluating individual features, but it does not capture the value a feature might have as part of an interaction.
This is particularly important in the context of tree models, which not only capture non-linear relationships (as I kept in my post), but also naturally exploit interactions between features.
So in that sense, what I said earlier was only partially correct:
A feature with near-zero mutual information may still be useful in a tree model—not because it works alone, but because it interacts meaningfully with other features.
Thank you. And thanks for tolerating my tendency to revise my thinking as I write—and rewrite! Participating in the forum has taught me a lot too.