Thanks Jim, If I better understood the methodology, I would bang the drum, too. I think I need to join some ML meetups to kick start this process.
Walter,
Thank you. Full stop.
A rhetorical question that I will just keep asking myself. This is all over at Sklearn. Literally everything I say is in code over there,
How can a coding illiterate like myself get it over at Sklearn, while my writings about it in the forum can seem like Sanskrit–with the best coders in the world here.
I honestly do not get it. Sometimes I think if I put enough words in a post it will look like english rather than an impenetrable wall of Sanskrit. ![]() Hmm, a confused emoji would be better.
Hmm, a confused emoji would be better.
Jim
Just to clarify: I don’t know anything about “the message that machine learning was not a topic for the forum.” Unless my memory is very bad (which is certainly possible) it wasn’t me who said that, and I can’t imagine why anyone would, but if you say someone did I believe you. Second, I am not hostile toward machine learning. My entire approach to investing is based on algorithms. Machine learning is another way of coming up with algorithms. I am skeptical about many of the claims made for machine learning, and believe that some of the assumptions behind it may be incorrect. But I am open to changing my mind, and skepticism is not hostility. Third, I have never and would never discourage the higher-ups at Portfolio123 to do anything with machine learning. I believe it’s a logical next step, and everything I’ve seen that’s in the works encourages me in that belief. Fourth, I am not in a position to make any decisions about the future of Portfolio123.
So going forward, whether you become a champion of machine learning or not……
Is there going to be a P123 staff member that can explain some of the new features? How regression could be used for example?
Maybe how some of the features available in the models can duplicate what you have been doing with mod()?
Explain cross-validation? Why you really cannot do XGBoost or a neural net without a couple of kinds of cross-validation (e.g., k-fold and early stopping). You can call early stopping a type of regularization, if you prefer but someone will have to explain it to members whatever you call it.
Or else their models will fail spectacularly.!!!
I am just saying the forum is not ready by any stretch of the imagination for machine learning. There will have to be a sharp and total change for it to work.
Have you been following what Jonpaul has been doing with XGBoost?
Without some advice on min_child_weight and k-fold validation shuffle = False it would have been a total fail for him.
He is still trying to figure out how to use mod() and subindustries with that. Are you going to tell him you started using mod() after reading an article by O’Shaughnessy about bootstrapping and that bootstrapping or subsampling in XGBoost might work as well? That mod)() was just a way to sort of do what O’Shaughnessy was talking about in his podcast about machine learing?
I think you have not done that so far.
There will be feature requests from any advanced members. Walter uses Time-series validation. Will his request be taken seriously?
Are you going to start doing that for people in the forum? Will you have someone better than I am answering questions and taking feature requests seriously? If you do, I would actually hope to learn from that staff member about some of this when she is hired.
Maybe not have her think cross-validation and train/test split is a brand-new very controversial idea.
Seriously, AI/ML will be a total fail for the members and for P123 as a business investment if the forum does not change. And change in a big way.
When is the release? @Marco, the present forum cannot do it, I think. Without a rapid change in the forum—discussing some of the established methods in an informed manner–it will be a spectacular fail.
Jim
I think you make an excellent point here, Jim. I’ll certainly try to make sure that the forum is fully ML/AI-friendly by the time of release. At the moment, as I’m fully aware, members interested in ML/AI have some ideas about what P123 is planning, but not enough. Also, since you ask, I have been avidly following Jon-Paul’s activity and was planning to be in touch with him about bootstrapping and other things. Thanks for prodding me.
Yuval,
Thank you.
Jim
Going back to talking about Bayesian optimization here is a plot of convergence for a ranking system where the y-axis is my optimization metric. In this case it is the negative of alpha/10 (as a %) - beta. So it is a bit meaningless, but I want to have high alpha and low beta. I take the negative of the metric as this algorithm minimizes the optimization metric. For context I am running my optimization metric on 5 different sub-universes and then taking the average. The optimization algorithm first runs an equal weight system. After this it ran 150 random points, and finally it uses the estimation function on another 150 runs.
The key takeaway I have is that out of 150 random tries only the first 50 runs resulted in a better performance. The next 100 runs produced the same or worse performance. However, the optimization function which starts at “number of calls”=151 almost immediately has a performance improvement and we see this improve every 20-50 calls.
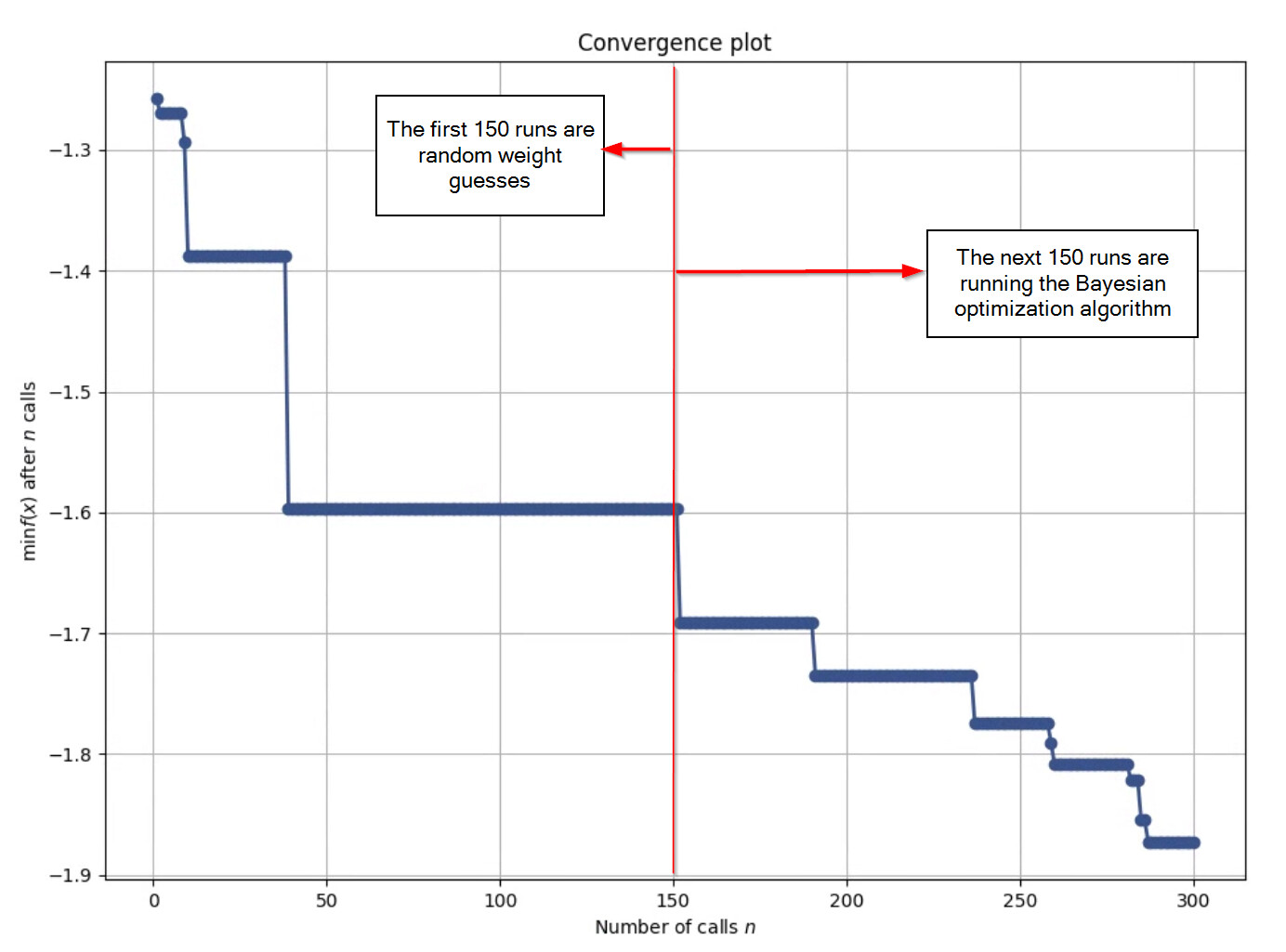
While this optimization did not result in better performance on the entire universe it does result in better performance on my sub-universes (about 6% increase from 16% average to 22% average alpha). So I believe this to be a more robust ranking system. But I am still investigating the best way to verify robustness since I did optimize on similar sub-universes.
It also did this while setting 9 out of 32 ranking weights to 0 which I think should reduce the chance of overfitting…
One more plot with 50 random and 250 optimize for the same total number of optimization calls:
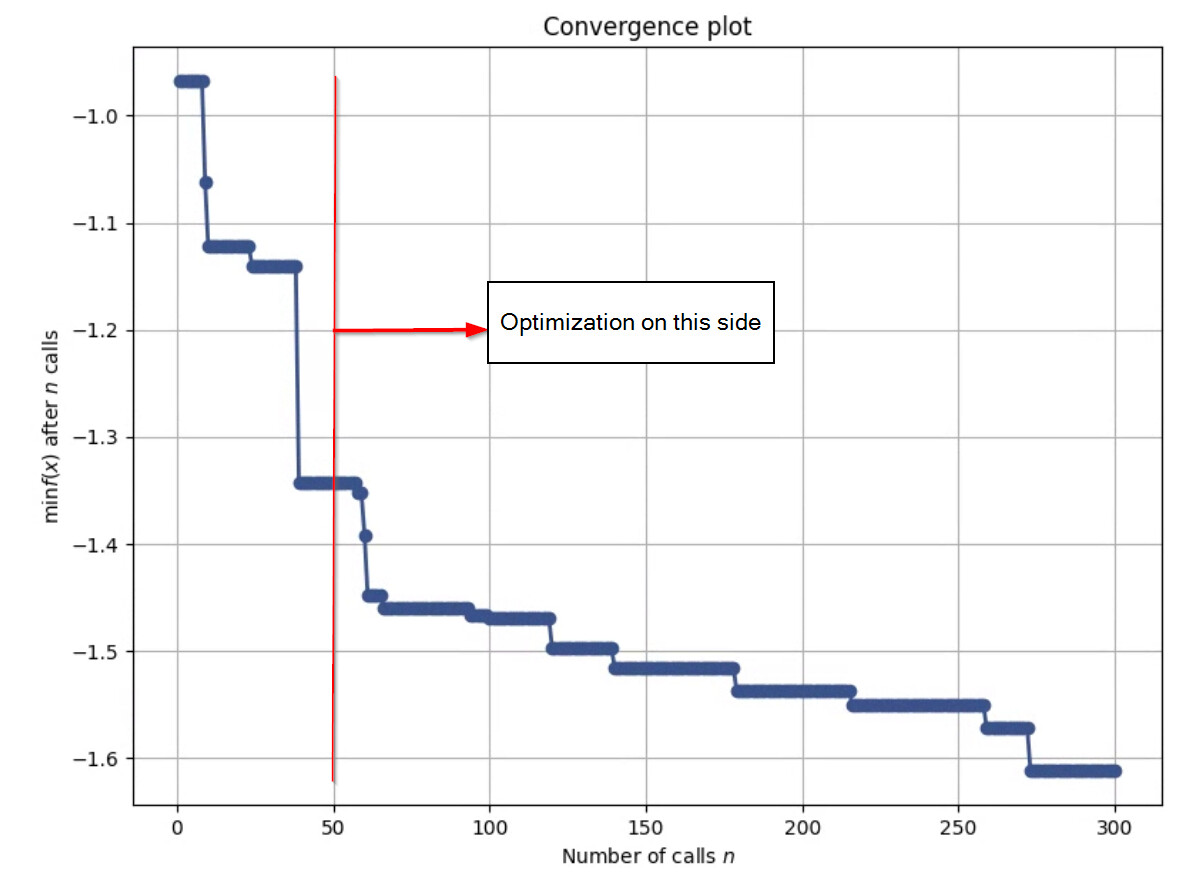
Note the optimization metric is not nearly as low (-1.6 vs -1.9) but the 5 sub-universe average performance is very similar. Around 22% alpha for both… Maybe one has better beta then. My take away is that if you are optimizing a lot of weights you need a good balance of random guesses and optimization.
1 Like
Thank you for sharing some of your method Jonpaul.