It is popular at P123 to use a spreadsheet to randomize the weights and put that into the optimizer. Or something like that.
@jlittleton has presented a method in the forum that is pretty much guaranteed to find the optimal solution sooner with les computer time. Probably less spreadsheet time.
You should probably talk to him and work with the AI/ML person to understand this, again if CPU cycles have any value.
TL;DR: Fewer CPU cycles guaranteed. Full stop. Maybe we do not have to wait for Yuval to invent this?
Not that I knew about this until just now or that Yuval should know everything but that just make my point that P123 is far behind Sklearn now and we have a lot to do to catch up. And the we need to welcome new ideas. Maybe implement a few of the good ones.
I have a question about this. Over-optimization produces curve-fit stuff that won't hold up out of sample. There are many techniques to avoid this, but "using a spreadsheet to randomize the weights and put that into the optimizer" certainly isn't one of them. Does the "guaranteed" method that you mention avoid over-optimization or encourage it? I honestly don't know the answer and am curious.
It is easiest to see what has happened at P123 by looking at this from the other direction. Why is mod() and subindustries the best P123 can offer?
Nothing could ever be better or you do not understand other methods? Seriously, which is it? You have constantly been critical of other methods, ignored them as feature request or said you do not understand them.
For a while you had some say in product development. We have mod() and subindustries now as something that is within the P123 platform to prevent overfitting.
You did not even bring us random_seed which might have been understood as being similar to mod() with some clear advantages.
I think P123 might take another direction with its Ai/ML offering. People still have the option of believing mod() is as good as it can possibly get, if they want.
For sure without cross validation/or hold out of some sort Bayesian optimization would be the ultimate over fitting method as it requires a lot less effort. But I tend to think the problem is more not using methods to combat over fitting than the ease of doing it.
If P123 Incorporated Bayesian optimization into the optimizer I think it would be very important to implement something like kfold cross validation and a hold out period at the same time. Make it so you have to intentionally turn it off.
For those who have a serious interest and are willing to go to Sklearn here is a sample:
Search for parameters of machine learning models that result in best cross-validation performance is necessary in almost all practical cases to get a model with best generalization estimate. A standard approach in scikit-learn is using sklearn.model_selection.GridSearchCV class, which takes a set of values for every parameter to try, and simply enumerates all combinations of parameter values. The complexity of such search grows exponentially with the addition of new parameters. A more scalable approach is using sklearn.model_selection.RandomizedSearchCV, which however does not take advantage of the structure of a search space.
"Scikit-optimize provides a drop-in replacement for sklearn.model_selection.GridSearchCV, which utilizes Bayesian Optimization where a predictive model referred to as “surrogate” is used to model the search space and utilized to arrive at good parameter values combination as soon as possible".
I do not think that is too hard for anyone interested and not trying to debate its usefulness. But in summary:
Sklearn thinks we should be using cross-validation to prevent overfitting and gives us some libraries to do that. Things that P123 does not provide now.
The Bayes Optimizer gets a quicker answer: Less CPU usage for P123 if they ever want to do this.
That is all I said. There is nothing difficult about that for someone who wants to bring modern ideas to P123.
I don’t think it is any serious controversy about whether Bayesian optimization can get a quicker answer or whether that is desirable.
So I certainly think being told machine leanring posts are off-topic in the forum was not in Marco’s best interest. Inappropriate and beyond rude for an employee to be undermining ML development at P123. There is an example in the forum (that was not a direct message). Duckruck was told that PCA might not be on-topic in a thread about regressions which shows an extreme lack of understanding and lack of interest in machine learning, at best. But I think Yuval reflexively saying that about a machine learning post in the forum reflects a deep dislike for anything machine learning. We don’t have to look at just one post or message to see that, however.
I do not believe he has ever implemented a single statistical measure or a machine learning method without Marco overriding him. The present AI/ML implementation to be released was Marco’s idea, I think. Something that is not being supported by Yuval in the forum to say the least.
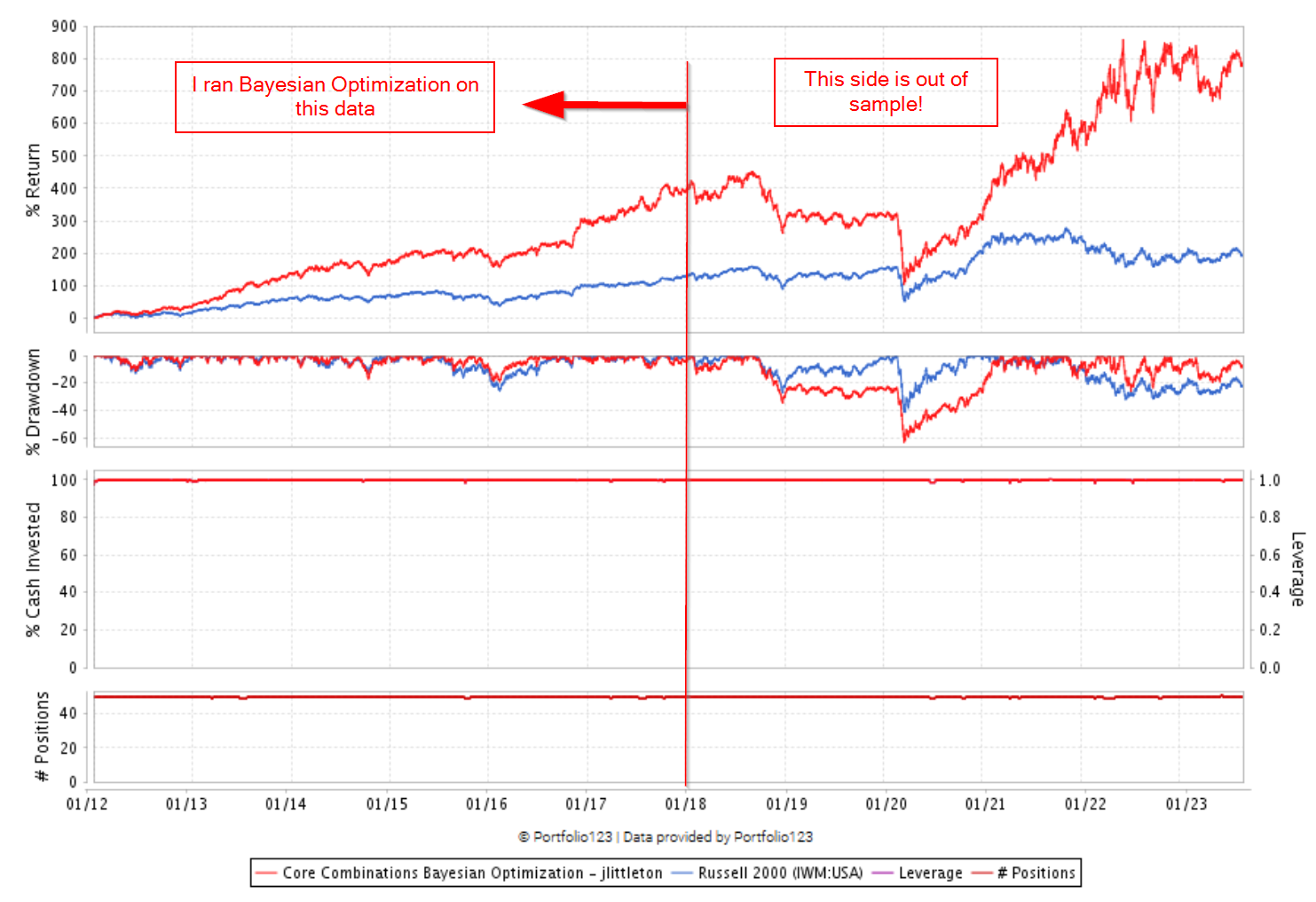
It may over fit way less than I thought it would (at least the python version I am using which is bayes_opt). I ran it on a subsection of the Core Combinations ranking system from around 2012-01-01 to 2018-01-01. I made two public ranking systems and two public simulations so show the effect of the optimization on the Prussel 2000 universe. The optimized version is impressive even out of sample. Granted 2018-2020 scares me too much to invest in it. I would like to point out that it actually set a lot of the weights to zero…
Now I will give a disclaimer that it is possible that I messed up my code and actually optimized on the entire timeframe as I did load in data from 2012-2023 and then split it and ran the optimizer on the 2012-2018 portion.
TL;DR: The Core System factors might still be working for someone using this model while the Core Ranking system in a classic port is having trouble and you are not done developing your final model.
Incredible stuff!!! I am happy to share my experience on min_child_weight and a few things. But this is way beyond my present capabilities. I hope to improve however. Maybe ML will continue to be welcome in the forum–making it a resource.
And you have just started right? Me too: I will have to wait for more API credits so I actually have not even started. Random forests are easier with regard to hyperparamerer so I will begin there (Elastic Net regression too). But I hope to move to XGBoost as you have done.
But you get this even without cross-validation. Wow. I am pretty sure you know how to slice data BTW. I think that is not a problem.
Maybe P123’s ML expert can go over to Sklearn to look at this at some point. Take the time to understand it. Consider making it part of P123’s AI/ML offering (if it isn’t offered on day one).
P123 will need a staff member who does understand this stuff, appreciates its value and who posts in the forum for AI/ML to succeed long-term, I believe.
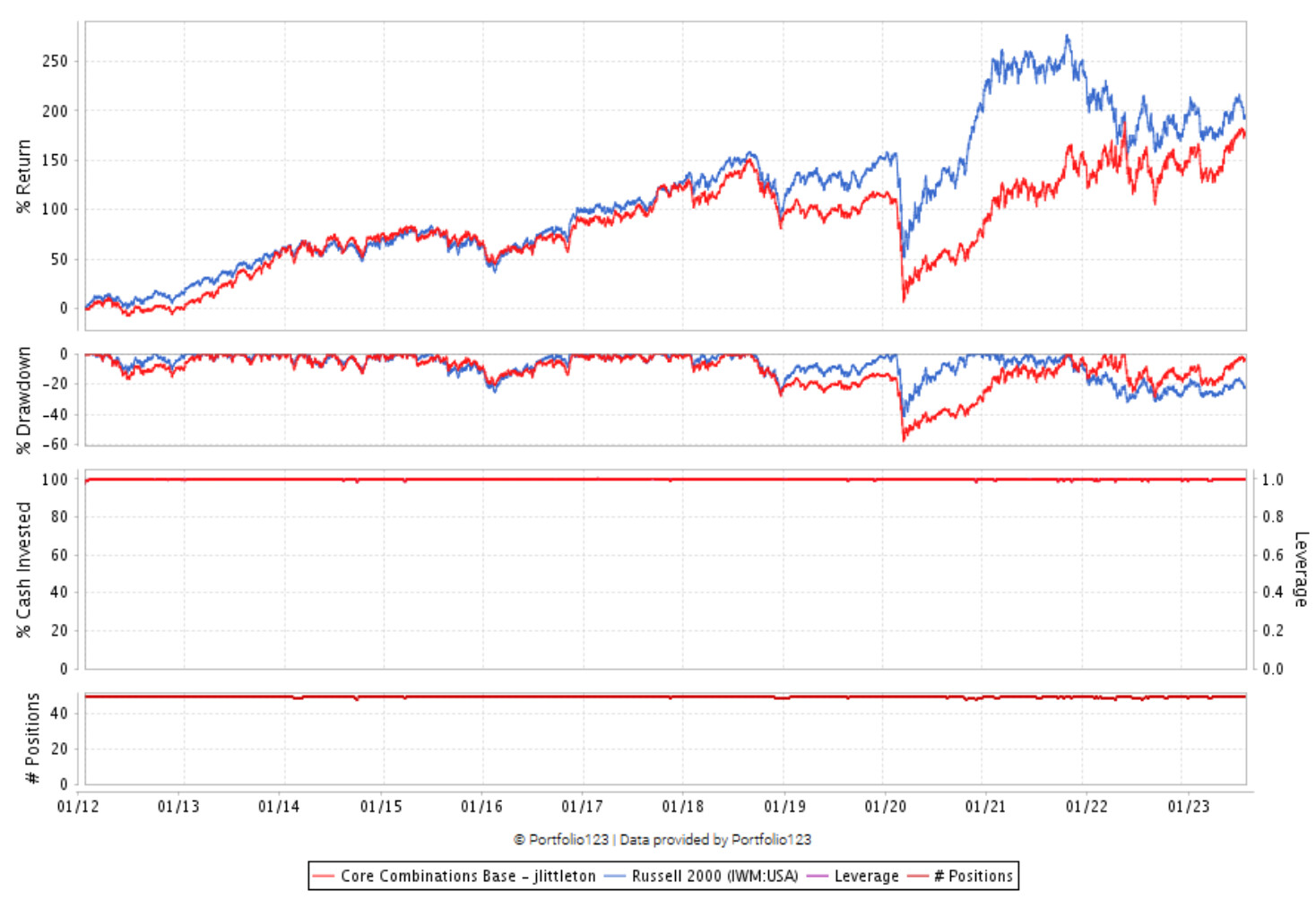
I want to follow up that while the Bayesian optimization did massively improve Core Combinations out of sample I am not seeing the same improvement in the Small Factor Focus system. First I optimized on the first half of my data in terms of years and then optimized on half of the universes stocks over the entire time period. The optimized universe had a marginally higher annual return, and the non-optimized universe was significantly worse. I think this is a great example of why hold out data and periods are so important! Without it I would probably think the optimized system was “better”. Now I just get to wonder why its so bad out of sample instead of putting my money in it haha. Maybe the optimizer has a hard time since I think the annualized alpha (my optimize target) is probably very rough in that little changes in weights can have a big effect on the alpha.
Also I mis-understood how to use kfold validation when tuning hyper parameters. I originally was only using it to evaluate a models robustness and not during parameter tuning. My new understanding is that the folds can be used to tune the parameters across multiple “folds” of data to help the model be more generalized. The “goodness” metric of each fold can be combined to get a total score. So the best parameters mean that the model performs well across all of the test data in the folds. But you still need a final test period after the kfold validation that you can evaluate on to see how it works out of the train/test period in case the fit “leaks” into nearby data. I think this page describes the idea for cross validation well: 3.1. Cross-validation: evaluating estimator performance — scikit-learn 1.3.0 documentation
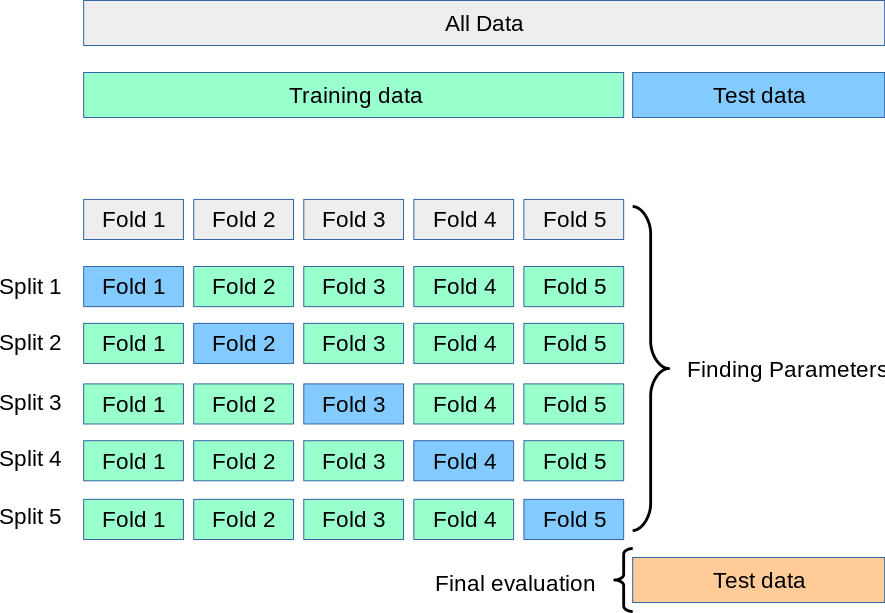
That being said I think kfold cross validation would need to be adapted to be used on a linear ranking system. In ML you need training data to build the model with. You do not need that with the linear ranking system as you just assign the weights and the model is “built”.
So instead of the type of cross validation shown in the image with train and test splits in each fold you would just have all splits be tests. You would keep the splits as they can be used to see how the model performs on different periods of time like a rolling test. Then you would average your performance metric for all of the test splits and folds and maximize that. Of course this would mean that you just optimized to the entire “training” data set, so you would need a final test to evaluate against and make sure you did not overfit like the image above. You could even split the final hold out test data into a few folds to see how it performs with subsamples of stocks.
Yes. And IMHO that is the most important concept in machine learning. You would use this with a regression model and could be used with the way people are optimizing using P123 optimizer, too. Whatever you are doing a person needs this.
So you can see why shuffle = True and Shuffle = False can be very different with stock market data. I.e., mixing time periods (or not).
The holdout test sample is meant to give you a true I idea of how your model will do out of sample. If you are very strict in how you do that, it can. The holdout test sample is meant to be used just once when you are done. It is not optimized, no multiple comparison problem.
It is, as you have shown the “Final evaluation.” Basically, the holdout test sample is to be used after you have done everything else. Selected the features, tested the different models (with k-fold) validation, identified the best hyper-parameters (with k-fold validation) etc.
Literally, run the holdout test sample at the end and if the returns are good enough then fund it the next day. The very last thing you do.
So just to reiterate. Here are the most important things about machine learn in order:
Cross-validation (with k-fold being a good way to do it).
Cross-validation (with k-fold being a good way to do it).
Cross-validation (with k-fold being a good way to do it).
Hold-out test sample if you want some idea of how your system will perform out-of-sample.
The rest.
Linear models are a little different as they are less prone to over-optimization, but you might still use k-fold cross-validation. For example, I would probably use k-fold cross validation for recursive feature elimination at a minimum.
And for the hyperparameters for ridge regression say (if you want to regularize your data). Or use it to help select the number of components for PCA regression (PCA regression is perhaps a favorite method for duckruck).
I hope you take this in the positive way I mean it. Can you stop trying to censor the topic of machine learning in the forum and debating the usefulness of anything involving machine learning as your default if you find this valuable? I do get that my posts are too long and I will take that as positive feedback and take that in the positive way you mean that also……uh, and stop there for brevity.
Also I get that P123 is not going to run out and immediately adopt every method I post. The vast majority of my ideas are not ready for prime-time and many are just pure BS. Often something I just read about and I don’t fully understand yet. I get excited by this stuff and I can be aggressive in promoting it. My wife keeps telling me that this is not grand rounds (life and death with the implication, at times, that you made a mistake that just killed a person). So I do get it and I am working on it. But I do, to some extent, respond in kind with people. I think Marc deserved the debate he got (and I used fewer c&ss words when doing it). I make no apologies for that.
You are an extremely intelligent person. I use you feature engineering every single day.
But Bayesian optimization, k-fold validation etc is just the beginning of what people like Jonpaul have to offer. Maybe they can soon lead the way. I think they will. I am not the best, the brightest. I do not even have any formal education in programming, statistic or machine learning. When I got my math degree I took one course in statistics. It was all proofs. I was required to audited a so called master’s course for medical training. No coding, all fluff.
TL;DR: Jonpaul and the others that follow are P123’s target audience for new members and for contributions in the forum, IMHO. I can and will step back a little. Its not like I will be able to keep up anyway.
My recommendations:
Sometimes P123 will want to incorporate things like Bayesian optimization if it makes sense from an efficient computer algorithm and/or business perspective.
It is not a debate.
We do not have to convince you anymore to get a feature. We can do it on our own with the downloads if we have to. Things like k-fold validation will simply have to be included in the AI/ML release if it is to be properly called ML, however.
You could consider learning some of this on your own without expecting us to explain everything or convince you in the forum. If you like Bayesian optimization you could consider making it one of your special projects at P123. Bringing that back to us. If used with you present optimization methods it would allow you to go through more factors quicker. I.e., more factors tested in you trading career.
Anyway, I have perceived you as hostile toward machine learning. I think the message that machine learning was not a topic for the forum makes that a not unreasonable conclusion. But we would like to work with you on whatever ideas you find helpful for you. And maybe we can all ead the way on a few of the good ideas. Whichever ones any of us are interested in for whatever reason.
I will be a better poster myself as long as—at the end of the day—I have the option of just doing it with the downloads and tell myself that I do not have to convince anyone else. I can just do it myself now—without having to wait for someone else to be convinced of its usefulness. That makes a big difference.
BTW, did I mention I use your features every day and they are making me money?
So the splits are across time? Wouldn’t splits that divvy up the universe also work? That is, each fold within a split would hold a subset of the universe.
If the universe has 12 stocks - (adbe, pfe, lly, csv, met, tap, adsk, lyb, dow, ibm, csco, aapl) - then the folds could be;
So split1 = fold2+fold3+fold4 for training with fold1 held out for validation and each split would cover the same time period, say 2000-2012. Rinse and repeat.
I think I mixed up the naming. It looks like the folds divide the time and the splits divide the universe, at least in the image I posted. The two terms are very similar in meaning. Also python calls each run of the cross validation a fold… Anyway I think the idea is that you split your training data by both time and stock id such that you have a range of data to train and validate. That way you have some insurance that your results are robust to different sub-universes and time periods.
I will note that kfold cross validation may not be the best method for time series data as you can get “leakage” from your training data set into the validation set. As duckruck posted there are potentially better methods like a rolling validation.
I have not tested a rolling validation vs kfold yet, so I cannot personally speak to this paper. But I can say that if you shuffle the data (in time) and train with ML it your validation data is almost meaningless.
The simplest way to put it that is complete is: Shuffle = False will keep the order of the rows in you csv file or DataFrame. With 5-folds, divide it into 5 equal pieces. 5 different time-periods if you have sorted the csv file in time order. You can sort by whatever you want, of course.
Shuffle = True will shuffle it making it all random. Mixing the order, including mixing the dates if you have sorted by date.
It is also not that hard to define your own Train/Test split and get exactly what you want with Python. You just have to know how to use split.
My personal preference is sort the rows in order of date and set shuffle = False. But a programmer like you can literally do anything.
TL;DR: With all the options, the most important thing you will ever use, IMHO.
If you are using XGBoost and wanting different universes turn on “subsampling.” Full stop. Set it to 0.5 to start with.
I can justify or explain that if wish.
But you will be doing stochastic gradient boosting with this. Here is the original paper: Stochastic Gradient Boosting. It will tell you about whether 0.5 is optimal or not but I think you will never want less than 0.5.
I hate to have to keep saying this but it has a few advantages over mod() for me personally. I will be grateful to have my downloads and I will stop saying that if P123 does not want to hear it.
K-fold Shuffle = False with data sorted by date is the my preferred way to do cross-validation. Cross-validation is actually a different way to avoid overfitting. It is a little hard to see the difference at first, however. Took me only 5 or 6 years. So, you will have it by next week I am guessing
Yuval is actually doing subsampling when he does mod() which is a very good thing. You can do this cool thing a bazillion times in XGBoost if you turn on subsample. Even better, IMHO.
So Mod() does subsampling that has limitations. You can ALSO cross-validate which is different.
You said you can have a cup of coffee and a snack and it is all done in 20 minutes?
BTW, turning on subsampling makes it run faster!!!
From the provided reference, forward chaining looks interresting.
"Time-series (or other intrinsically ordered data) can be problematic for cross-validation. If some pattern emerges in year 3 and stays for years 4-6, then your model can pick up on it, even though it wasn’t part of years 1 & 2.
An approach that’s sometimes more principled for time series is forward chaining, where your procedure would be something like this:
fold 1 : training [1], test [2]
fold 2 : training [1 2], test [3]
fold 3 : training [1 2 3], test [4]
fold 4 : training [1 2 3 4], test [5]
fold 5 : training [1 2 3 4 5], test [6]
That more accurately models the situation you’ll see at prediction time, where you’ll model on past data and predict on forward-looking data. It also will give you a sense of the dependence of your modeling on data size."
Also called walk-forward validation. The cool thing is that regressions run fast enought that P123 could clearly do that with a regression model and it would probably take less resources that a lot of what they do now.
I can show you are feature request for that. Yuval was not a fan at the time.