Pitmaster and I have tested similar strategies for SPDR ETFs, TLT and GLD here: A Novel Way to Control Risks - #2 by pitmaster
Both strategies are rebalanced monthly and I wondered if there was a best day-of-the-month to trade the strategies. I was able to test this with my Python Strategy. It is likely Pitmaster's screen would have similar results, I think.
On backtest, one month (September 2001) has only 15 trading days due to September 11, 2001 market closings. The trading days were limited to the first 15 across all months for consistency.
Conclusion. The first of the month is fine for this Python strategy:
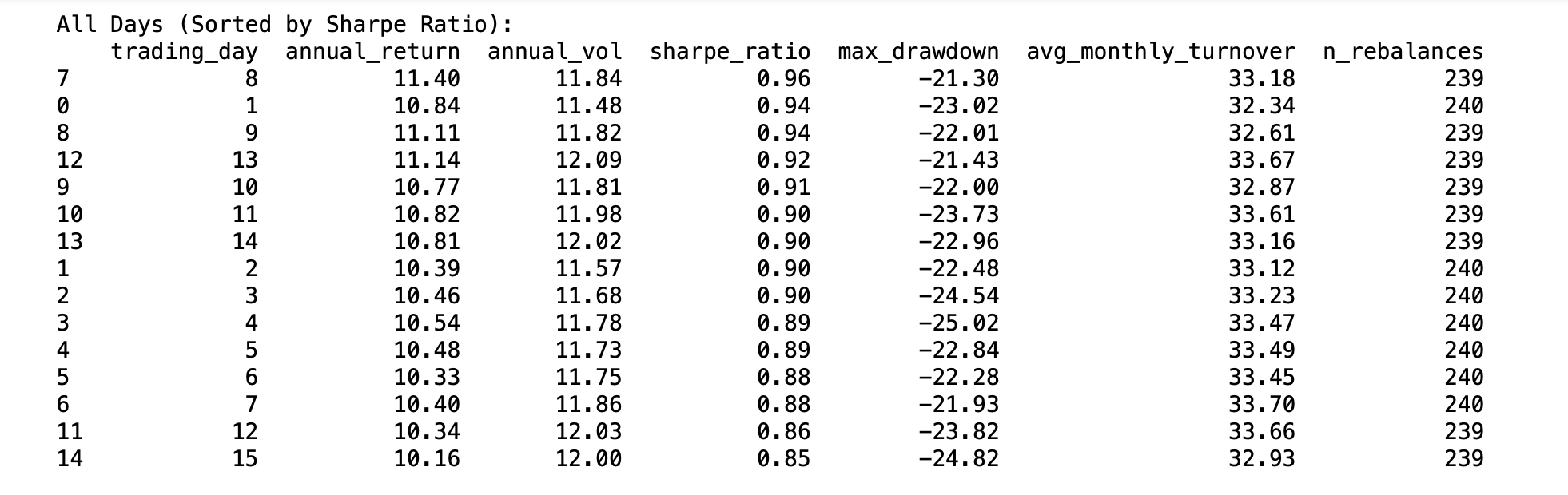
Edit: I later tried that last trading-day-of-the month and trading on the first day of the month is still reasonable for this strategy, it seems:

Code if you want to check my results or try this with a different set of ETFs or to see if these results generalize:
class DayPerformanceAnalyzer:
def __init__(self, stock_tickers: list, benchmark: str = "SPY",
n_bootstrap: int = 1000, window_size: int = 29):
self.stock_tickers = stock_tickers
self.benchmark = benchmark
self.n_bootstrap = n_bootstrap
self.window_size = window_size
def get_nth_trading_day_dates(self, data: pd.DataFrame, n: int) -> pd.DatetimeIndex:
"""Get dates of the nth trading day of each month"""
monthly_groups = data.groupby(pd.Grouper(freq='M'))
nth_dates = []
for _, group in monthly_groups:
if len(group) > n:
nth_dates.append(group.index[n])
return pd.DatetimeIndex(nth_dates)
def analyze_nth_day(self, data: pd.DataFrame, valid_stocks: list, n: int) -> dict:
"""Run strategy rebalancing on the nth trading day of each month"""
n_stocks = len(valid_stocks)
# Initialize weights and returns
stock_weights = pd.DataFrame(0.0, index=data.index, columns=valid_stocks)
portfolio_returns = pd.Series(0.0, index=data.index)
# Get rebalancing dates (nth trading day of each month)
rebalance_dates = self.get_nth_trading_day_dates(data, n)
# Initial setup
initial_periods = max(self.window_size, 4)
initial_weight = 1.0 / n_stocks
first_rebalance_idx = data.index.get_loc(rebalance_dates[0])
stock_weights.iloc[:first_rebalance_idx] = initial_weight
# Calculate initial returns
for t in range(first_rebalance_idx):
portfolio_returns.iloc[t] = (stock_weights.iloc[t] * data[valid_stocks].iloc[t]).sum()
# Main loop
current_weights = pd.Series(initial_weight, index=valid_stocks)
turnovers = []
for t in range(first_rebalance_idx, len(data)):
current_date = data.index[t]
if current_date in rebalance_dates and t >= initial_periods:
window_start = max(0, t - self.window_size)
# Calculate new weights
stock_metrics = []
for stock in valid_stocks:
stock_returns = data[stock].iloc[window_start:t]
historical_excess = stock_returns - data[self.benchmark].iloc[window_start:t]
values = historical_excess.values.flatten()
bootstrap_samples = np.random.choice(
values,
size=(self.n_bootstrap, len(values)),
replace=True
)
bootstrap_means = np.mean(bootstrap_samples, axis=1)
prob = float(np.mean(bootstrap_means > 0))
variance = stock_returns.var()
ratio = 0 if variance == 0 else prob / variance
stock_metrics.append({'stock': stock, 'ratio': ratio})
# Calculate normalized weights
metrics_df = pd.DataFrame(stock_metrics)
total_ratio = metrics_df['ratio'].sum()
if total_ratio > 0:
new_weights = pd.Series(
[metric['ratio'] / total_ratio for metric in stock_metrics],
index=valid_stocks
)
else:
new_weights = pd.Series(1.0 / n_stocks, index=valid_stocks)
# Calculate turnover
turnover = np.abs(new_weights - current_weights).sum() / 2
turnovers.append({'date': current_date, 'turnover': turnover})
current_weights = new_weights
stock_weights.iloc[t] = current_weights
portfolio_returns.iloc[t] = (current_weights * data[valid_stocks].iloc[t]).sum()
# Calculate performance metrics
cum_returns = (1 + portfolio_returns/100).cumprod()
rolling_max = cum_returns.expanding().max()
drawdowns = (cum_returns - rolling_max) / rolling_max * 100
ann_return = (1 + portfolio_returns.mean()/100)**252 - 1
ann_vol = (portfolio_returns/100).std() * np.sqrt(252)
sharpe = ann_return / ann_vol if ann_vol != 0 else 0
avg_turnover = np.mean([t['turnover'] for t in turnovers]) * 100 if turnovers else 0
return {
'trading_day': n + 1, # Add 1 so day 0 becomes day 1 for clarity
'annual_return': ann_return * 100,
'annual_vol': ann_vol * 100,
'sharpe_ratio': sharpe,
'max_drawdown': drawdowns.min(),
'avg_monthly_turnover': avg_turnover,
'n_rebalances': len(rebalance_dates),
'returns': portfolio_returns
}
def analyze_all_days(self, start_date: str, end_date: str, max_days: int = 15):
"""Analyze performance for each trading day of the month"""
# Prepare data
data, valid_stocks = MultiStockBPW(self.stock_tickers).prepare_data(start_date, end_date)
# Analyze each trading day
day_results = []
day_returns = {}
for day in tqdm(range(max_days), desc="Analyzing different trading days"):
result = self.analyze_nth_day(data, valid_stocks, day)
day_results.append({k: v for k, v in result.items() if k != 'returns'})
day_returns[day] = result['returns']
# Convert to DataFrame for easier analysis
results_df = pd.DataFrame(day_results)
results_df = results_df.sort_values('sharpe_ratio', ascending=False)
# Print detailed results
print("\n=== Performance by Trading Day ===")
print("\nAll Days (Sorted by Sharpe Ratio):")
print(results_df.to_string(float_format=lambda x: '{:.2f}'.format(x)))
# Calculate statistics
print("\n=== Statistical Analysis ===")
print("Average across all days:")
print(f"Annual Return: {results_df['annual_return'].mean():.2f}% (±{results_df['annual_return'].std():.2f}%)")
print(f"Annual Volatility: {results_df['annual_vol'].mean():.2f}% (±{results_df['annual_vol'].std():.2f}%)")
print(f"Sharpe Ratio: {results_df['sharpe_ratio'].mean():.2f} (±{results_df['sharpe_ratio'].std():.2f})")
print(f"Max Drawdown: {results_df['max_drawdown'].mean():.2f}% (±{results_df['max_drawdown'].std():.2f}%)")
print(f"Monthly Turnover: {results_df['avg_monthly_turnover'].mean():.2f}% (±{results_df['avg_monthly_turnover'].std():.2f}%)")
# Plotting
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(2, 2, figsize=(15, 12))
fig.suptitle('Performance Metrics by Trading Day')
# Plot metrics
ax1.bar(results_df['trading_day'], results_df['sharpe_ratio'])
ax1.set_title('Sharpe Ratio')
ax1.set_xlabel('Trading Day of Month')
ax1.grid(True)
ax2.bar(results_df['trading_day'], results_df['annual_return'])
ax2.set_title('Annual Return (%)')
ax2.set_xlabel('Trading Day of Month')
ax2.grid(True)
ax3.bar(results_df['trading_day'], results_df['annual_vol'])
ax3.set_title('Annual Volatility (%)')
ax3.set_xlabel('Trading Day of Month')
ax3.grid(True)
ax4.bar(results_df['trading_day'], results_df['max_drawdown'])
ax4.set_title('Maximum Drawdown (%)')
ax4.set_xlabel('Trading Day of Month')
ax4.grid(True)
plt.tight_layout()
plt.show()
# Plot cumulative returns for best and worst days
best_day = results_df.iloc[0]['trading_day'] - 1
worst_day = results_df.iloc[-1]['trading_day'] - 1
plt.figure(figsize=(15, 6))
(1 + day_returns[best_day]/100).cumprod().plot(
label=f'Best (Day {int(best_day + 1)})', linewidth=2)
(1 + day_returns[worst_day]/100).cumprod().plot(
label=f'Worst (Day {int(worst_day + 1)})', linewidth=2)
plt.title('Cumulative Returns: Best vs Worst Trading Days')
plt.grid(True)
plt.legend()
plt.show()
return results_df, day_returns
# Run the analysis
stocks = ["XLE", "XLU", "XLK", "XLB", "XLP",
"XLY", "XLI", "XLV", "XLF", "TLT", "GLD"]
analyzer = DayPerformanceAnalyzer(stocks)
results_df, day_returns = analyzer.analyze_all_days("2001-01-01", "2024-11-01")