If you are like me you mostly optimize the cross-validation by "Results" which has a maximum of 100 buckets.
Also, if you are like me you think LightGBM has too many, confusing hyperparameter choices.
But if you use P123's Easy to TradeUniverse and optimize with P123's "Results" you will be optimizing for 100 buckets with about 33 stocks in the upper bucket, I believe.
So as a simple approximation would you set "num_leaves": 100 (at least a little like the number of buckets) and min_child_samples": 33 (at least a little like the number of stocks in a bucket).
Maybe you could skip "Early Stopping" then? Just stick with what you have experience with and have looked at a thousand times while using P123 classic?
Am I making this too simple? Is that right? If so, does it make the choice of hyperparameters simpler? Maybe to all of those, I think.
And maybe you want to set it to "num_leaves": 200 and "min_child_samples": 20 or 15 if you are used to looking at 200 buckets and/or 15 or 20 stock models?
Maybe lower "num_leaves" (like buckets) or higher "min_child_samples" (like stocks per bucket) if you are overfitting. Anyway, two important hyperparameters may be something we already understand on an intuitive level. Or not, I guess, if I am oversimplifying.
For sure, I cannot get early stopping to work with LightGBM and think I need something else that is easy, and preferable intuitive to prevent overfitting.
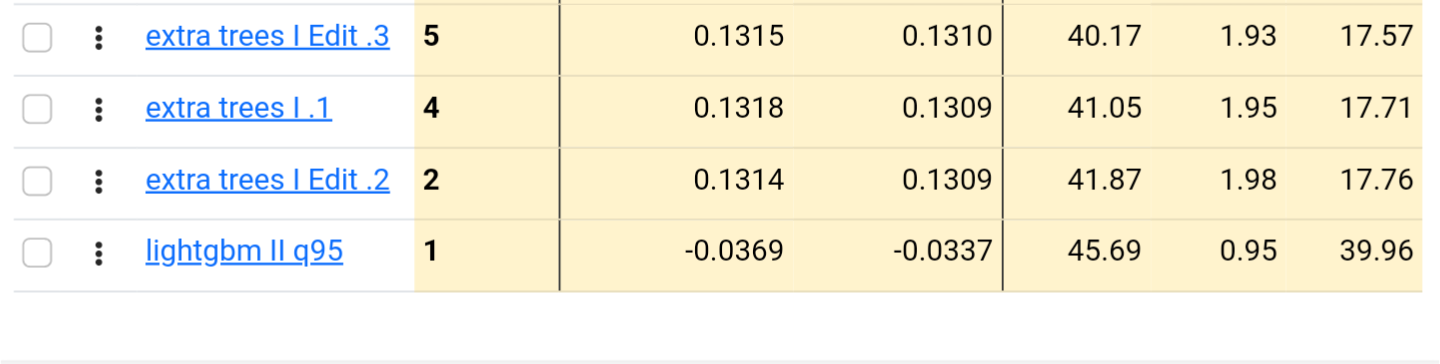
Speaking of LightGBM hyperparameters: LightGBM has a parameter for a quantile regression: Example: LGBMRegressor(objective = 'quantile', alpha = 0.95)
Using this the regressor places an emphisis on lowering the error of the upper 5% of predictions. For prediction results I'm not interested on how accuratly it predicts the losers, I'm trying to invest in the winners. I was unable to modify a LGBMRegressor. Can this be done or am I misunderstanding something.
The Huber objective, the MAE objective, and the quantile objective are all designed to reduce the impact of outliers, not to focus on optimizing the highest buckets.
I did small experiment with using very small number of features (10 popular ratios : value, growth, quality) and universe Russell 1000 and I found that the best models are highly regularised and constrained random forest or linear models.
Please note, that imposing monotonicity constraint is a some sort of look ahead bias because you know that some ratios were positively/negatively/neutrally associated with future returns in the past... but well...at least we should be aware of this.
Below is an example of regularised and constrained random forest and linear model that worked well for me for small number of features:
Right, the default model : 'linear ridge' seems to be not properly defined.
Parameter "l1_ratio" is not related to ridge regression.
And remove intercept to false.
After modification the default model looks like this: {"fit_intercept": false, "alpha": 0.5}
The P123 system references the ENet function instead of the Ridge function to ensure generalization, because I can't use the "solver" parameter, but I can use the "selection" parameter.
Z: “The Huber objective, the MAE objective, and the quantile objective are all designed to reduce the impact of outliers, not to focus on optimizing the highest buckets.”
Yes, I agree. . .After looking at some example outputs I believe I misinterpreted how the upper bucket output was modified even I would say clamped. Thanks for correcting my misunderstanding.
I have noticed how often different ML models all have their goal to modify all values from low returns to the highest. The extreme upper and lower bands usually have the highest errors due to the extreme outliers. The only solution I’ve seen mentioned is eliminating some of the most probable lower performance data from what you feed the ML learner.
Pitmaster: You seem to have the magic touch, or perhaps an example of capabilities derived from a lot of hard working/learning. Thanks I appreciate your response!
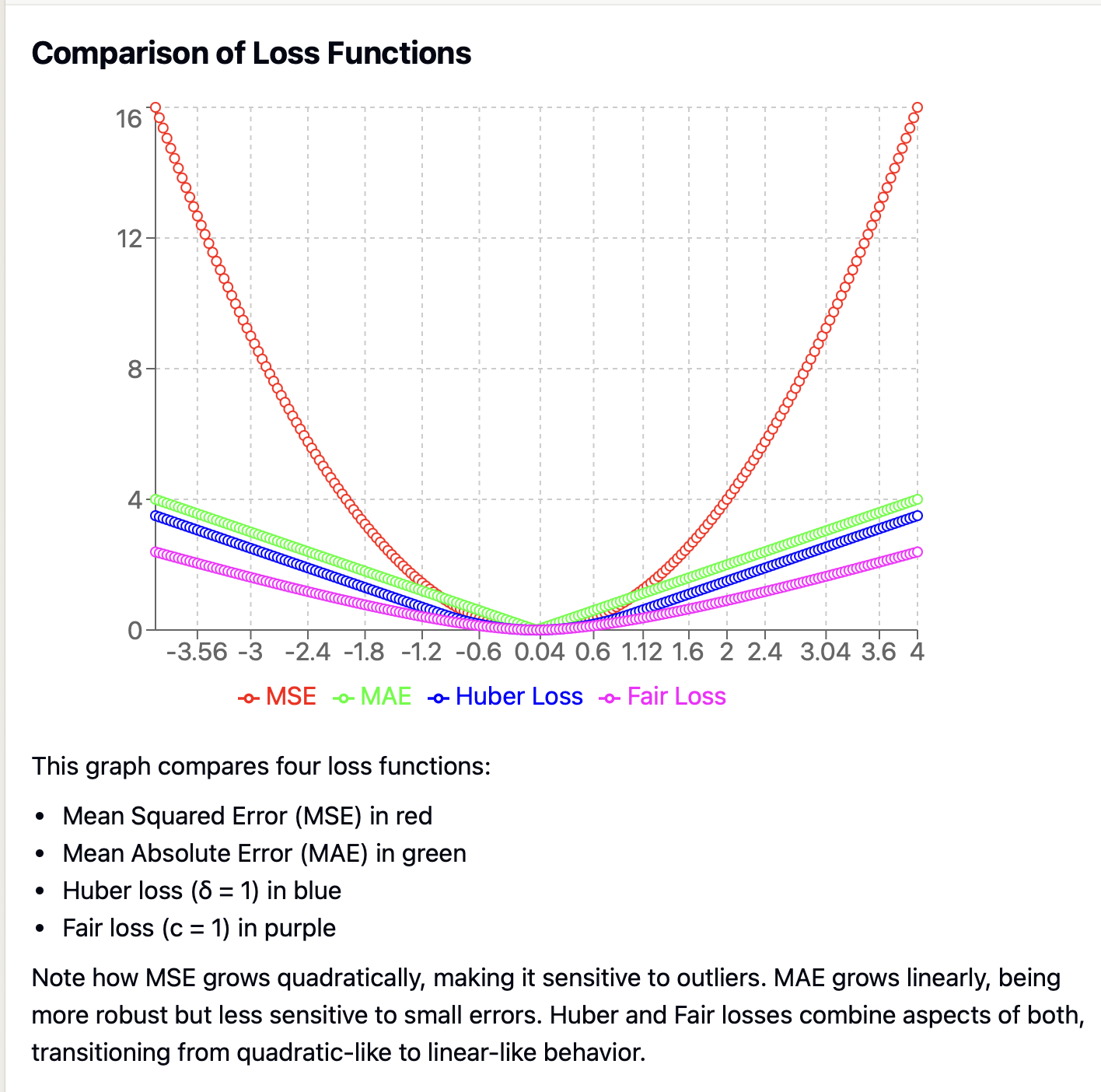
I would add "fair" to this list. Fair works better than mse, huber, mae or mape for me so far.
My original post on a different topic that happened to include the use of "objective": "fair" in the discussion:
LightGBM can be made to to act like a random forest if you set "boosting": "rf".
You can get it to act like an Extra Trees Regressor by adding the setting setting "extra_trees": true to this.
Why do that and not just use Sklearn's Extra Trees Regressor (what P123 provides)? Because LightGBM has some hyperparameters not available in Sklearn's Extra Trees Regressor.
For example, "objective": "fair" which reduces the effect of outliers. The reduced effect of outliers can be controlled with "fair_c". I.E."objective": "fair" defaults to "fair_c": 1.0 but can be changed to increase or decrease the effect of outliers (lower numbers reducing there effect of outliers more).
I think that is probably just one example of additional hyperparameters LightGBM makes available that could be useful.
Resources:
This only covers MSE, MAE and Huber Loss (not fair loss): Understanding the 3 most common loss functions for Machine Learning Regression But like Huber loss, fair loss is a combination of MAE and MSE. Both Huber loss and Fair loss are types of M-estimators, a class of robust statistical techniques introduced by Peter J. Huber in 1964.
If we can customize the loss function, we can weight data points with higher prediction accuracy more highly. These data points tend to predict higher future returns.
A simpler approach would be, as you say, to screen out the worse stocks from the universe first. In fact, this means it would be better to define the universe in terms of the results of the ranking system.
Or you can use a simple filter like: FRank("$PctToPTLo")+FRank("WCapPS2PrQ")+FRank("Price")-FRank("SharesFDQ")+FRank("Close(21)/Close(252)")+FRank("BookValQ/MktCap")-FRank("TRSD5YD")-FRank("AstTotQ/AstTotPYQ")+FRank("GMgn%3YAvg")+FRank("ROA%Q-ROA%PYQ")-FRank("SI%ShsOut")-FRank("AvgDailytot(200)")>100
However, after adjusting the universe in this way, the model became less effective. The lack of negative samples seems to reduce rather than increase the generalization ability of the models
When I use this on Z-score models, it does not work well, but with Rank models it works well. However, I have tried "positive": false, but I get the exact same results as with true?
You have probably already selected features that are monotonically increasing for P123 classic.
So with Pitmaster’s post using ridge regression you should not expect a difference for an existing ranking system. They will all be mostly positive (with or without specifying positive) although you can get some very small negative coefficients due to regularization if you do not specify "positive" in the hyperparametrs.
Monotonic_constraints with LightGBM is more complex. LightGBM seems to behave differently than HistGradientBoosing with regard to monotonic_constraints for reasons I do not understand at this point.
No, I noticed that something was wrong when checking Importance of the features, all features with a negative slope got 0 weight, like vollatility etc.
I tried now to inverse all those features on a new model, suddenly features like vollatility has the highest weight.
So I would have tried that too. Seems like you were probably using "positive" in both instances maybe? Did it help to inverse volatility? Volatility might be an important factor and " vollatility has the highest weight" might not be an error. Rather it could be what you want, if I understand correctly.
I do not have access to the AI. The default is false so i would just remove that from the code to make sure there is not a coding error or unusual syntax with P123's JSON.