I’m still working on this time-consuming and annoying optimisation process of ranking systems, just to learn of the prosess on how to best put RS together.
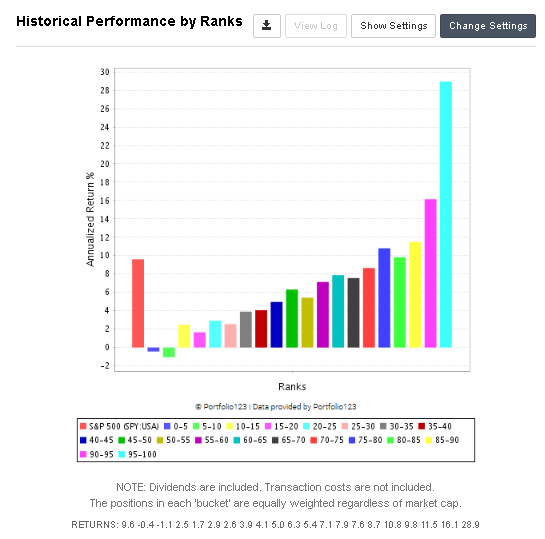
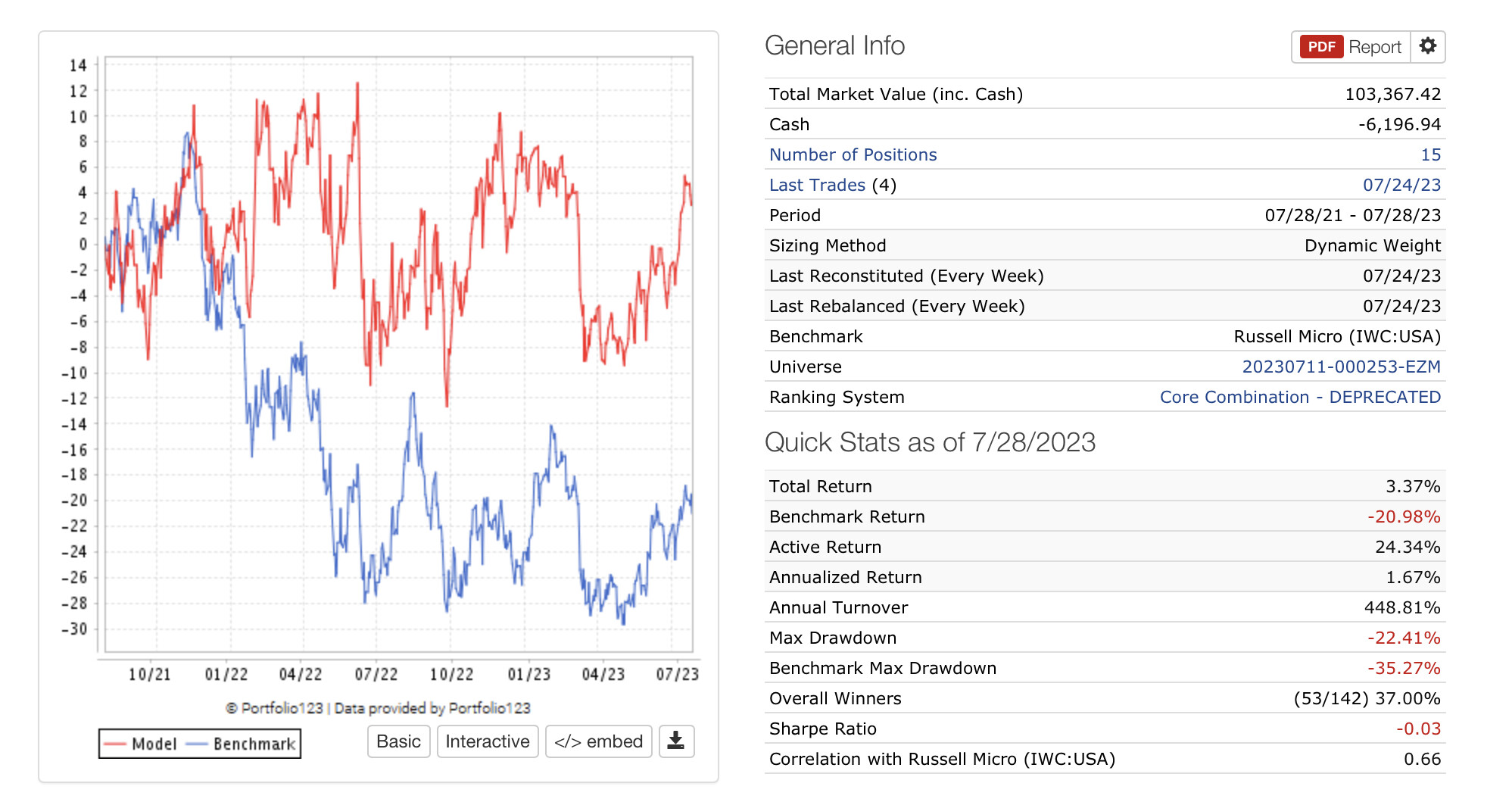
I did a test with 150 nodes, which I believe in, where I started the RS without any composite nodes and just the Small Cap Focus RS. Then I added one and one of my own nodes. And I ran the simulator on the full US Canada universe (with a liquidity rule). If it did better, I kept the node, and if it did worse, I set it to 0%. I ran it with the full history, and with 25 stocks. And each new node should at least weigh more than 1%.
Then I did the opposite. I added all 150 to the 39 that are already in the Focus RS. Here I equally weighted each of the 150, so that, in total, that part of the RS did not have more than 50%, and each node got around 0.35%. Then I set each to 0%, ran the simulator, and kept only the ones that made the performance better.
And Yes, I know, this is overfitting. And the performance difference could be something of a coincidence.
The surprising thing is still that the last method did far better than the first one. Not just in total performance but also in the performance increase through the process. Anyone who has a good explanation of why the difference?
It seems that a large part of building a RS is not only finding nodes that make sense but also understanding how factors interact with each other.