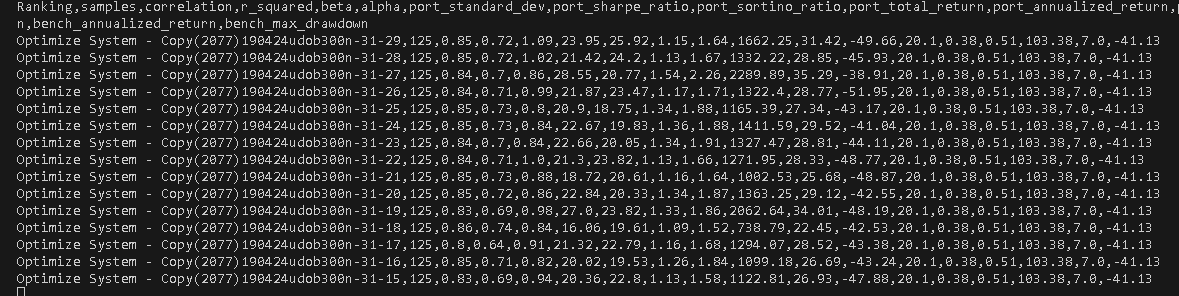
Maybe Im answering my own question.
But with something like this: "rankings = ['ranking1', 'ranking2', 'ranking3', 'ranking4', ..., 'ranking500'] #"
import p123api
try:
client = p123api.Client(api_id='xx', api_key='xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx') # Your ID and Key
rankings = [
"Optimize System - Copy(2078)190424udob300n-40-48",
"Optimize System - Copy(2078)190424udob300n-40-47",
"Optimize System - Copy(2078)190424udob300n-40-46",
"Optimize System - Copy(2078)190424udob300n-40-45",
"Optimize System - Copy(2078)190424udob300n-40-44",
"Optimize System - Copy(2078)190424udob300n-40-43",
"Optimize System - Copy(2078)190424udob300n-40-42",
"Optimize System - Copy(2078)190424udob300n-40-41",
"Optimize System - Copy(2078)190424udob300n-40-40",
"Optimize System - Copy(2078)190424udob300n-40-39",
"Optimize System - Copy(2078)190424udob300n-40-38",
"Optimize System - Copy(2078)190424udob300n-40-37",
"Optimize System - Copy(2078)190424udob300n-40-36",
"Optimize System - Copy(2078)190424udob300n-40-35",
"Optimize System - Copy(2078)190424udob300n-40-34",
"Optimize System - Copy(2078)190424udob300n-40-33",
"Optimize System - Copy(2078)190424udob300n-40-32",
"Optimize System - Copy(2078)190424udob300n-40-31",
"Optimize System - Copy(2078)190424udob300n-40-30",
"Optimize System - Copy(2078)190424udob300n-40-29",
"Optimize System - Copy(2078)190424udob300n-40-28",
"Optimize System - Copy(2078)190424udob300n-40-27",
"Optimize System - Copy(2078)190424udob300n-40-26",
"Optimize System - Copy(2078)190424udob300n-40-25",
"Optimize System - Copy(2078)190424udob300n-40-24",
"Optimize System - Copy(2078)190424udob300n-40-23",
"Optimize System - Copy(2078)190424udob300n-40-22",
"Optimize System - Copy(2078)190424udob300n-40-21",
"Optimize System - Copy(2078)190424udob300n-40-20",
"Optimize System - Copy(2078)190424udob300n-40-19",
"Optimize System - Copy(2078)190424udob300n-40-18",
"Optimize System - Copy(2078)190424udob300n-40-17",
"Optimize System - Copy(2078)190424udob300n-40-16",
"Optimize System - Copy(2078)190424udob300n-40-15",
"Optimize System - Copy(2078)190424udob300n-40-14",
"Optimize System - Copy(2078)190424udob300n-40-13",
"Optimize System - Copy(2078)190424udob300n-40-12",
"Optimize System - Copy(2078)190424udob300n-40-11",
"Optimize System - Copy(2078)190424udob300n-40-10",
"Optimize System - Copy(2078)190424udob300n-40-9",
"Optimize System - Copy(2078)190424udob300n-40-8",
"Optimize System - Copy(2078)190424udob300n-40-7",
"Optimize System - Copy(2078)190424udob300n-40-6",
"Optimize System - Copy(2078)190424udob300n-40-5",
"Optimize System - Copy(2078)190424udob300n-40-4",
"Optimize System - Copy(2078)190424udob300n-40-3",
"Optimize System - Copy(2078)190424udob300n-40-2",
"Optimize System - Copy(2078)190424udob300n-40-1",
"Optimize System - Copy(2078)190424udob300n-39-50",
"Optimize System - Copy(2078)190424udob300n-39-49",
"Optimize System - Copy(2078)190424udob300n-39-48",
"Optimize System - Copy(2078)190424udob300n-39-47",
"Optimize System - Copy(2078)190424udob300n-39-46",
"Optimize System - Copy(2078)190424udob300n-39-45",
"Optimize System - Copy(2078)190424udob300n-39-44",
"Optimize System - Copy(2078)190424udob300n-39-43",
"Optimize System - Copy(2078)190424udob300n-39-42",
"Optimize System - Copy(2078)190424udob300n-39-41",
"Optimize System - Copy(2078)190424udob300n-39-40",
"Optimize System - Copy(2078)190424udob300n-39-39"
] # Liste med dine rankingsystemer
for ranking in rankings:
result = client.screen_backtest(
{
'screen': {
'type': 'stock', # Stock or ETF
'universe': '1. Pareto - US CANADA volumfilter',
'maxNumHoldings': 25, # 0 for all
'method': 'long', # long, short, long/short, hedged
'currency': 'USD', # USD, CAD, CHF, EUR, GBP, NOK, PLN, SEK, TRY
'benchmark': 'iwm',
'ranking': ranking,
'startDt': '2010-01-01',
'endDt': '2024-05-30',
'pitMethod': 'Prelim', # Prelim or Complet
'precision': 2, # 2, 3, 4
'transPrice': 3, # 1 - Next Open, 4 - Next Close, 3 - Next Average of Hi and Low
'slippage': 0.25,
'longWeight': 100,
'rankTolerance': 5,
'rebalFreq': 'Every Week', # Every Week, Every Month
'riskStatsPeriod': "Monthly" # Monthly, Weekly, Daily
}
})
print(f"Ranking: {ranking}\nResult: {result}\n")
except p123api.ClientException as e:
print(e)