Thank your explanation. I was getting tripped up on, now what I believe to be, fact that training is set to end date of our features, not the target. I think that is wrong; it should be set to end date of the target so that there is no data leakage. Otherwise, the parameter needs to be coded to match the target? Why would we have each user lookup the target in the database to ensure there's no overlap with validation holdout? Seems like alot of wasted human hours prone with error. This should parameter should be automatically completed by the AI Feature, imo.
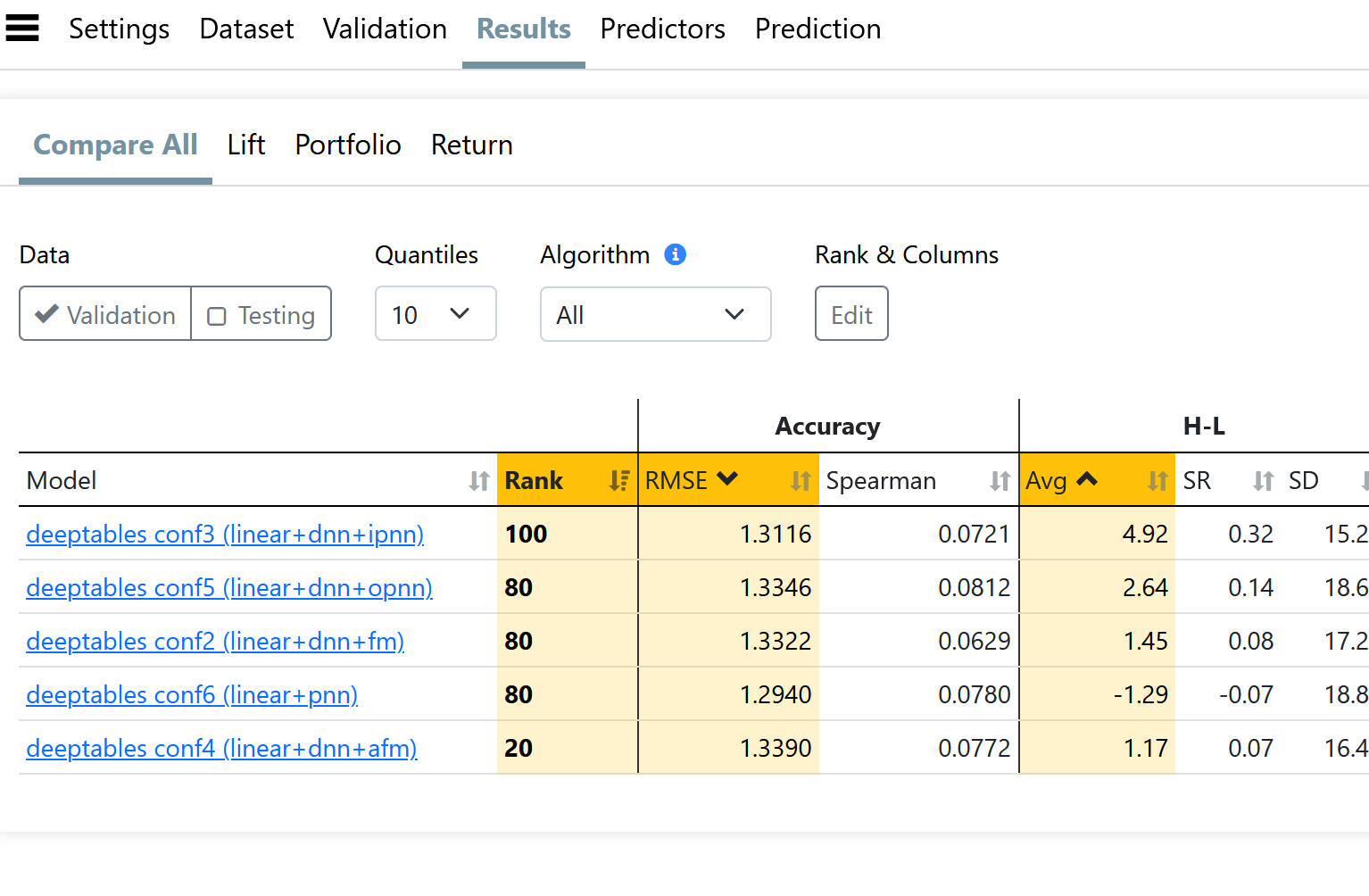
@danparquette What is "Validation" and what is "Testing"? Is Validation the holdout or the training? And is testing only the available when we toggle the "test" feature on "unseen" data? I can reason to show Validation training performance, holdout performance, and test performance.
To all: How do people think about the delta between the testing performance and the validation holdout performance? In theory, the purpose in validation holdout is see how good the predictor is (this is your OOS). So I think we need more metrics to test for statistical significance between the two performance measures so we can make informed decisions.
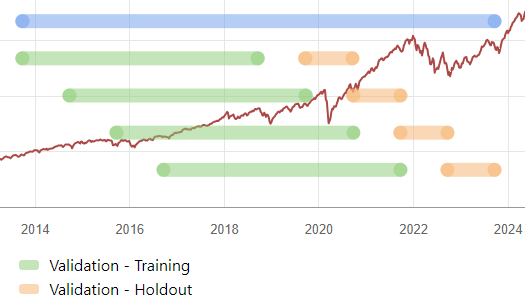
@danHow / Why does the predictor not default to the type of training? In other words, if we do rolling time series cross validation, don't we want a predictor that trains and behaves the same way (train for x lookback and then predicts, rinse and repeat)? Otherwise, we don't have predictor that matches the research process. Am I correct here? Like, we'd want to run a simulation with a predictor that matches the validation holdout period and right now we cannot have a single simulation that does that, right?
Please let me know if I'm right or wrong on these as I still don't really know what I'm looking at. TY
For #1: Validation has both a training period and a holdout period. The help bubble explains the difference: "The Holdout Period specifies the duration (in years) of the data set aside after the training period for model validation. This period evaluates the model's performance on unseen data."
Testing is optional and only enabled if you turn on the Testing toggle as you stated. If enabled, Testing also has a training period and a validation period. My opinion would be that Testing is most useful when using KFold because in KFold the data for every date has been 'seen' in multiple folds when training. Testing sets aside a Testing Holdout period that has not been seen earlier.
For #3: Rolling Time Series CV would match up with your live system if that live system was going to always use a set # of years of data and the model was to be retrained every x months (or years) in the future. Using the image below as an example, these settings would represent a live system where my predictor uses rolling 5 years of data and I plan to retrain the predictor each year using the most current 5 years of data.
If I was planning for my live system to always use all available data for training, then I would choose Time Series CV or K-fold when developing the system. Or maybe Basic Holdout if a user didnt have access to enough historical data to utilize folds.
So if I want to use fundamentals that uses 3Y of data, I should use a 3 year Gap between the Training and Holdout to avoid data leak in to the Holdout period?
AlgoMan,
I couldn't tell you what the right gap is with features that cover 3 years. There doesnt seem to be a way to apply rules to this. ChatGPT4 only gave one item that seemed quantifiable = "Conduct empirical testing by backtesting your model with different embargo periods and evaluating performance metrics." So I did a test that seems to prove the gaps do not need to be this large.
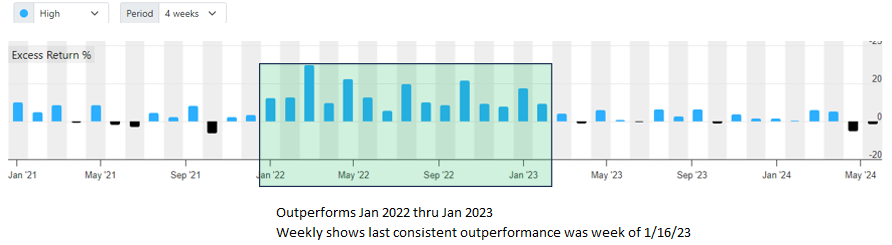
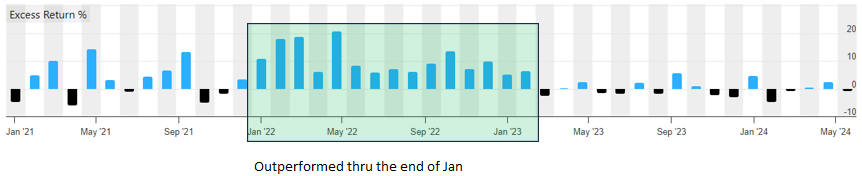
The test was to train predictors using one 1 year of data since that should make any out-performance returns very specific to the dates affected by the training overlap.
Used Extra Trees II as the predictor. Predictor training period was 1/2/22 to 12/31/22.
Created a ranking system which had only 1 factor which was the predictor being tested.
Ran rank performance tests for 1/2/21 thru today. Rebal freq=1 week. A small cap universe.
First AIFactor had 2MRel as the target and features were a mix of 75 quarterly and ttm factors.
Based on this experiment, a longer target period seems to require a slightly larger gap. But using 3Y fundamental features didn't require a larger gap then qtr and ttm features.
I ran the same test with an XGB and Random Forest II predictors and saw similar results to Extra Trees.
This test seems logical, but if anybody sees reasons why it is flawed, please speak up. And this was not a through test since it only covered one period. It should probably be done for at least 3 or 4 more distinct periods given how imprecise the method is of determining which periods outperformed. For example, it is possible my model did so poorly in the start of 2023 that it is hiding the outperformance due to data leakage in Feb, March and April of 2023.
Personally, I will still use at least a 3 month gap because losing a few months of data to extend the gap for each fold is meaningless but having any overlap can have a major impact.
Wow I have read this over twice and I'm confused as heck. If the algos have a look ahead bias with the 3 year and 5 year ratios my impression is with a 12 month gap you basically cant use any of the 3 year or 5 year factors which would make some sense because my models AI returns are typically around 10% more than the benchmark but when I run a screen or simulation Im getting some too good to be true results. It makes no sense to me to train the model on data from say 1999 to 2006 and then do a simulation from 2007 to present built on factors that performed well in the far past. I think we need some consensus on what are the best practices here. Im going to try taking out all of the 3 year and 5 year ratios and see what returns look like with a 12 month gap. Alternatively using a 3 year or 5 year gap is not ideal either.
Because your training data and your predictor data are exactly the same, choosing the best model out of all the ones you've trained and then running a predictor to arrive at simulated results is going to have data leakage no matter how long a gap you have, at least in my (very uninformed) opinion. I would argue that the only way to avoid data leakage in a simulation based on an AI model would be to do all the training on a limited dataset (e.g. Europe only or pre-2015 stocks) and then run the predictor on an entirely different dataset (e.g. Canada only or post-2015 stocks). And then you run into data compatability issues. I am coming at this from a very uninformed POV, and may be entirely incorrect in my assumptions. But it just doesn't make any sense to me to expect anything but crazily stellar results if you're running the predictor on the same data that you used to choose your system, no matter how many gaps you use.