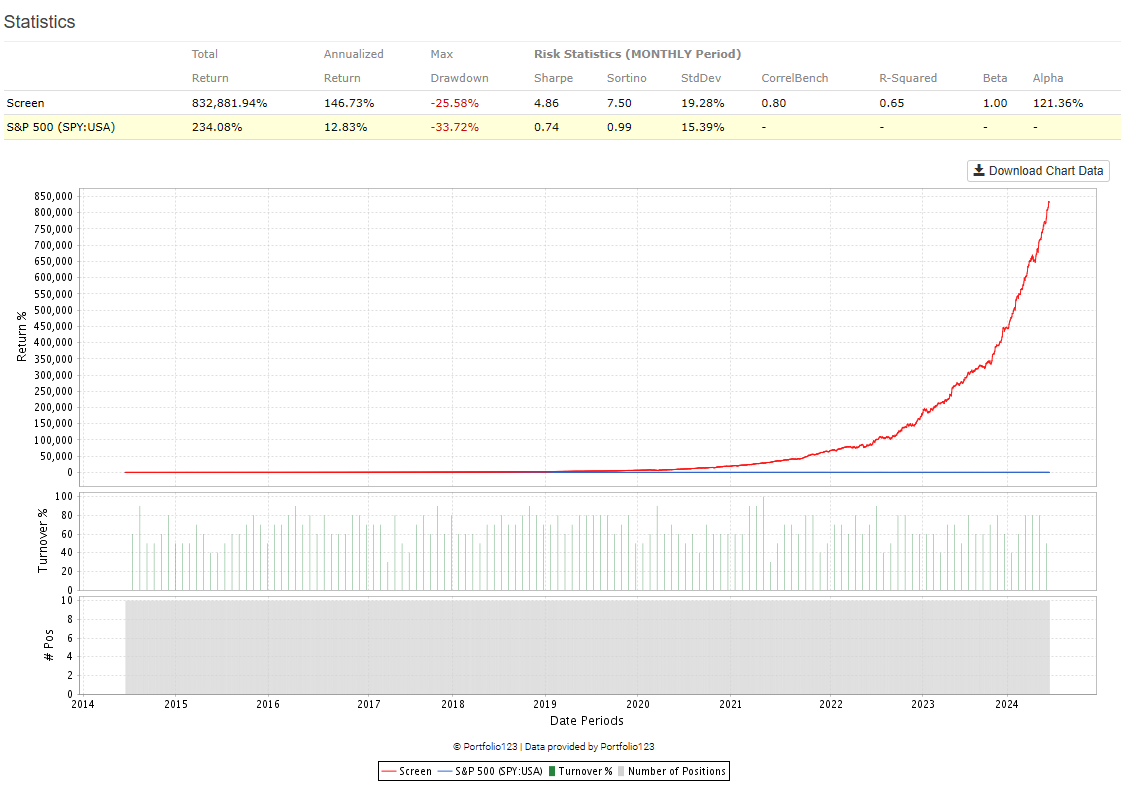
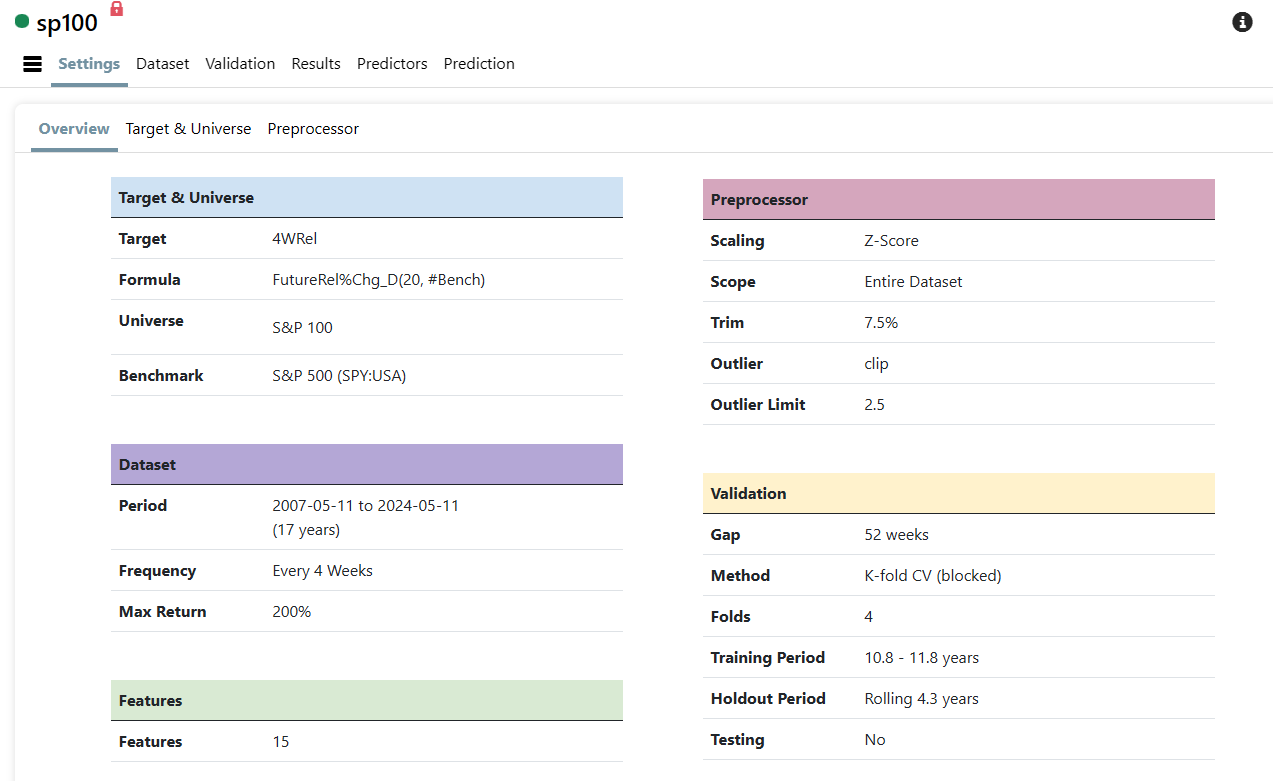
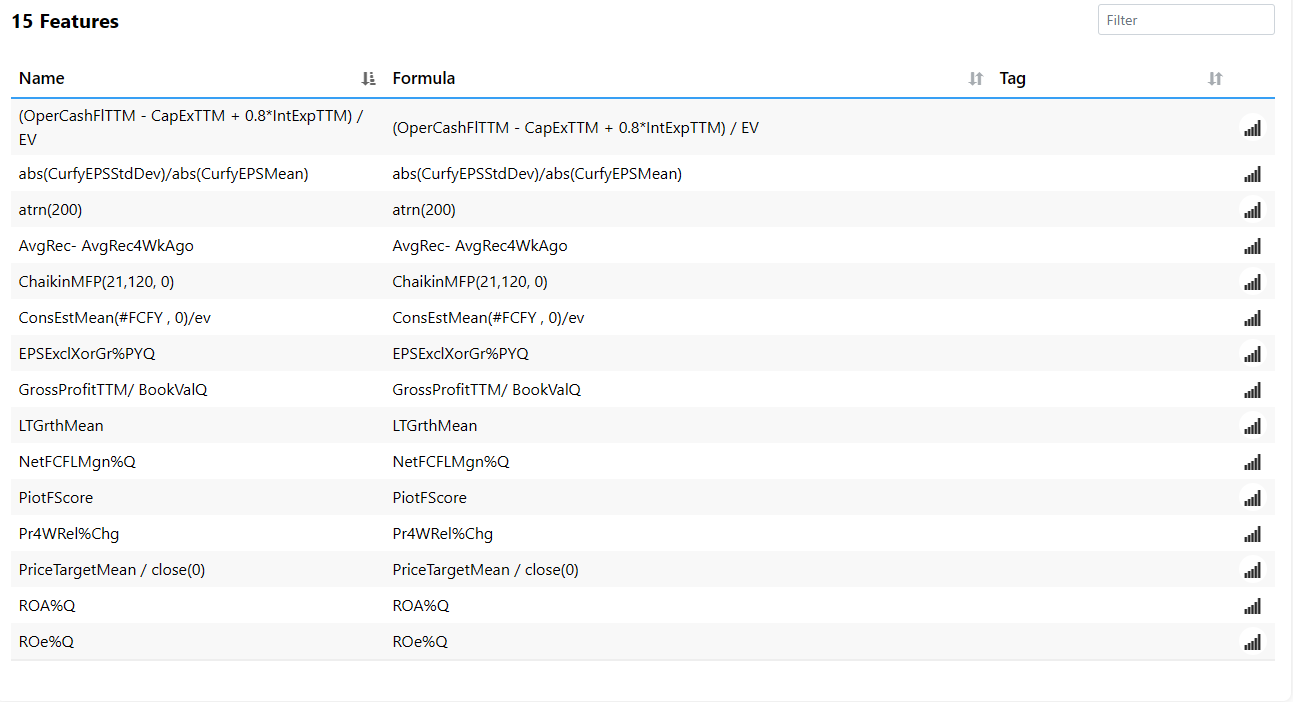
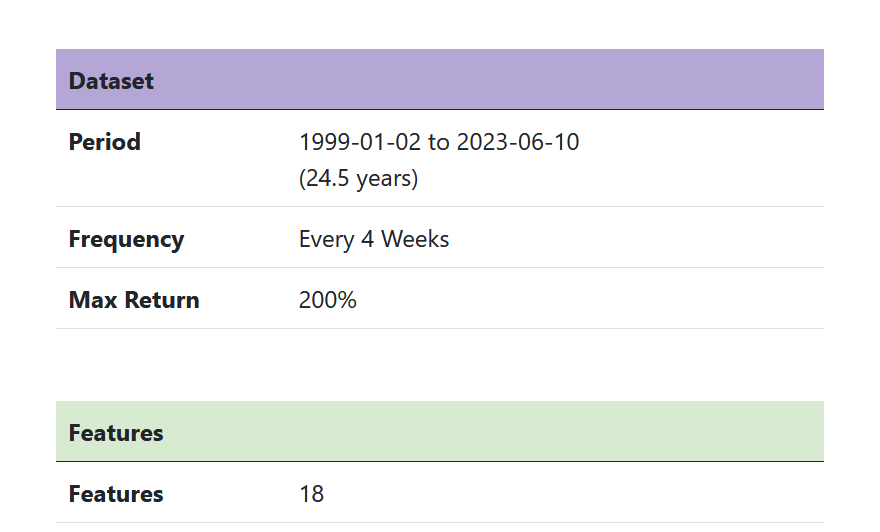
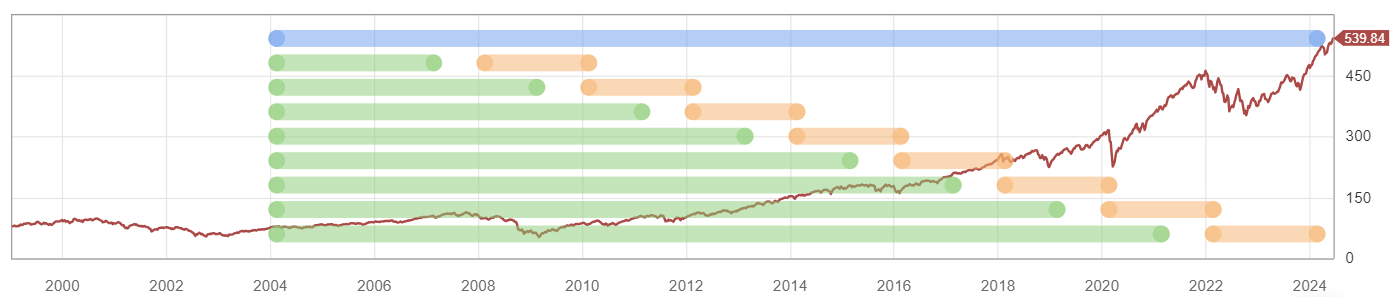
I must have done something wrong and created a look-ahead bias. Not sure how. This is an S&P 100 system. I have a ranking system that works okay. I loaded it into the AI factor. I will include the settings and the 10 stock chart. I don't know much but I do know getting 146% annual return in the biggest 100 stocks would make me a trillionaire soon.
Maybe someone can take a look and see what I did wrong.
What is the training period of the predictor? If you use training data in a backtest you will get fantastic curve fitted results.
BTW, this is routinely what users do with classic P123. Weights and factors of a ranking system are manipulated to produce great rank performance results over 20y, then the ranking system is used in a backtest.
We will likely add logic to prevent you from using a predictor in a backtest period that overlaps with training data, or something to that end.
During training a model is supervised by labels (future returns, model knows what happened in the future)
During testing the rules from a trained model are used to infer predictions (model does not know what happened in the future)
I assume there is no validation part (out-of-sample testing of different models)
I'm not sure if this is what you asked but anyway, the chart is a great example of how powerful are these models (when supervised by labels)
As a practical question at P123, the "Predictor" training is used to create a ranking system to be used in a screener, sim or port. With the best model being determined by cross-validation usually.
But as you have seen, the predictions should not be trained over the same period as the screen or sim when you do this.
Ideally your work-flow, might have a "hold-out set" that covers the last X number of years. Cross-valdidate over the period before the hold-out set. Find the best model with cross-validation. Then use that model for "P123 Prediction" to train over the same period as the cross-validation (not training the "prediction" over the holdout set period). Then use this ranking system in a sim or screen only over the holdout period.
This should give you a decent idea of how your model will do out-of-sample.
The caveat is that there may be some look-ahead bias in the factors you chose. For example, if you include EBITDA/EV as a factor because it has done very well over the last 5 years and you test over a holdout set of the last 5 years there is some look-ahead bias in your factor selection.
But this is better that a backtest and you can select factors using an algorithm with data that does not include the last 5 years and mitigate some of this look-ahead bias (data leakage) from knowing what features have done well recently.
But doing any training over the period you are testing, predicting or validating at any time in this process will look great as Pitmaster says. Look great but guaranteed not to do as well out-of-sample.
This is not the final step, however. As the final step you train over all of the data using the model you find to be best with cross-validation, updating your features using your algorithm on all of the data (including recent data) and start making predictions in your port going forward (out-of-sample).
I am still not 100% sure on the difference between model training and predictor training. I thought they were the same.
Suppose I take just one model - random forest 1. I use K-fold cross-validation training with 1 year hold-out period. What exactly is this doing? And how would this be different than taking my random forest 1 model and doing predictor training?
Seems like I am training my model twice?
Sorry if these are simple questions but I do not fully understand the process despite reading up on it.
I think you are right. Maybe I am missing a fine point myself but they are pretty much the same thing as you suggest.
The k-fold cross-validation has the purpose of finding the best model using something pretty similar to a rank performance test. But you cannot make a screen or Sim out of that information for now.
You can make a Sim or screen by making an AI factor which requires "Predict" for now.
But I think you are 100% right. This last is just another way to do cross-validation and the only differences are practical—especially if you want to make a Sim out of the data.
Pitmaster has made your same point in a different way (as have I). The k-fold validation data could be made into a screen. Pitmaster asked for a set number of stocks in a post which would act like a screen. I think you could also use that data for a Sim.
So I think you are 100% correct in your impression. They serve the same purpose. But you cannot make a screen or sim out of the k-fold validation method for now and that is just a practical difference.
Creating models and running the validation for each model is done to find the optimal combination from the available P123 algorithms (and custom algorithms you create) and other variables including the universe, target, preprocessor settings, features, training period length, etc.
You are looking for the combination that gives you the best results where 'results' could be % returns for the top bucket, top bucket minus bottom bucket, etc. Once you find that optimal combination (ie the best model), you would then use those same settings to create the predictor. If your testing has shown that training with the maximum years of data is the best, they you could create a predictor that is trained using all the data available based on your subscription level. You would then use that predictor in the AIFactor() function in your live screen, ranking system and or live strategy buy/sell rules. At some point in the future you would train a new predictor (using the same settings) that includes the recent data which is was not available when you initially trained it.
Another optional additional step in the workflow is to create that predictor with an end date in the past so that you could run simulations (or screen backtests) using those predictions in the AIFactor() function. The reasons you might want to do this would be 1) if your system will have additional buy/sell rules that were not in the universe used in the AI validation or testing. 2) To see the turnover and slippage since we have not incorporated those in the AI pages yet. 3) As a confirmation that the AI validation results were correct.
For example, you could create a predictor with a training start date of 1/1/04 and an end date of 1/1/19. Then run a simulation that starts 1/1/20 and ends today. Noticed there is a 1 year gap between the end of the predictor training to the simulation start date. This is needed to prevent data leakage. If you start the simulation on 1/1/19 you will most likely see a big spike in the returns for at least the first quarter of 2019.
great post @danp
do you have any theory/examples that explain why/when the gap should be 1 year, rather than 0.5 year or 1.5 year ? I think the users may be confused with this feature.
I think the reasoning is that you want all the data that has been 'seen' during training to no longer be included in the data when the simulation starts. If that is true then if ALL your features were quarterly factors then using a 3 month gap (or maybe 4 since companies dont report at exactly 3 months intervals) should be sufficient. But if you have TTM and annual factors, then a 12 month gap is needed. It is best to be conservative with your gap since allowing any data leakage will artificially inflate your returns. I noticed this when I ran simulations containing predictors for many different model and the sim for every model did very well in the first 4-5 months even though I had used a 3 month gap.
I am still very much an amateur, so any comments from this group are appreciated.
My question is about creating the predictor, which from my understanding, is the final model that you use in simulations, ranks, screeners, etc.
To create this predictor, the training period seems to be fixed to match the initial dataset.
The issue here is that we have all these tests of in sample and out of sample (i.e. your Time Series CV (cross validation?).
But then we have our predictor and our predictor we use in simulation has look ahead bias because it's trained in the entire dataset. The predictor has seen the future and cannot be used in the simulations, rankings, etc.
The training period for the predictor can be a subset of the date range available in the dataset. In my earlier post I mention that if you wanted to also run a simulation or screen backtest then you would need to create another predictor that had an end date of 1/1/19 (for example) so I could run a simulation with a start date in 2020 and not have any overlap between the training period and the simulation period.
I'd like a little understanding of the data leakage thing @danparquette.
Can you provide an example of how data leaks? I think I'm observing results where this is playing a role yet I don't know how to adjust this parameter in a way that is proper.
My understanding is that you do not want any of the same data to be in both your training set and your validation set. Since most fundamental data is released quarterly, features like quarterly eps growth would be the same for about 3 months. That would mean that you need about 3 months gap (aka embargo period) between those datasets. And if you are using annual factors, then you would need a 1 year gap. Personally I will always use a gap that is larger than what I think I need because I want to be sure my results are valid.
The first test in my limited testing with sims had no gap between the predictor training end date and the simulation start date. The features in those models were a mix of quarterly and TTM factors. There was a very obvious over performance in the sims for most models in the first few months with returns over 100%. When I redid the test using a 3 month gap between the training end date and the sim start date, that drastic spike mostly disappeared but some the sims for some models still had a questionable jump at the start. So it seems a 4 month gap might have been okay but I would do at least 6 months to be safer and 12 months if I wanted to be sure the TTM factors were not having an undesirable effect.
Sorry, I understand the concept but not how this is actually working.
If you have a target of 3 month relative return and use the feature of quarterly eps growth, why don't we have the following scenario type with a dataset that loads as follows:
I don't think there's look ahead bias this way, is there? At every observation we take the features that exist at that time and then more into the future the distance required by the target.
Is the dataset load pulling the target at the same date as the features?
Apologies for the math notation but faster than latex.
I think you have to look at the way the training data and test or validation data is split (i.e., the "train/test split).
Suppose you are training up until December 31, 1999. And like in your example you are predicting the next quarter. So you are predicting and training into early 2000 if you do not have a gap. There is an overlap there.
If you have set the test period starting at January 1, 2000 you are using information in the training period about the test period that you could not possibly have know at the time. When you are training with this train/test split your are about to see if you can predict something you already know. You might find you are pretty good at predicting what you already know if you have a good memory.
Obviously, you could do that even without a neural-net. But neural-nets have great memories of even little details.So you want your gap to be as long as (or slightly longer than) your "Training Lookahead" to make it fair for that neural net. To make sure it isn't using memory of future events. Or you want to avoid using information you could not possibly know at the time to make any predictions in a test period.
The gap AFTER the test data is more complex. I think Dan has a nice discussion on that. But it is a complex discussion which also deals with autocorrelation, persistence of markets and other things..
Dan has a good rule of thumb for the minimum gap, I think. If you use TTM or trailing 12 months you should make ithe gap 12 months at a minimum. After all, you are using information in the training that is in the test data—although it is more subtle and not always sure to give you an advantage.
You could make it longer based on how long you think market trends persist in general. This would be the autocorrelation consideration that is difficult to quantitate and may be different for different markets..
The gap afterward is necessary only for k-fold validation. If you use time-series cross-validation then you just need to make the gap as long as (or slightly longer than) the Target Lookahead you are using..
Bottom line: you should not be using information that you could not have known at the time for predictions.. Like the FUTURE returns in the test period you are predicting.. You would not have know something called "future returns" at that time. You cannot use future data that is in the test period for predictions.