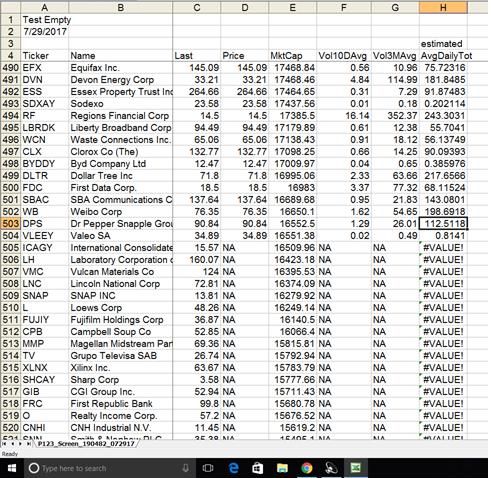
Hi, I don’t know if this is a basic limitation on data exports, but I’m trying to get a better feel for liquidity in various parts of the market, however when I export the data, i’m getting NA in the columns. Example is attached.
All I’ve done is run a screen called “Test Empty” and am exporting the data to excel. I’m trying to get daily average total dollar volume for each ticker, so in excel am trying to calculate lastprice*(3 month avg volume/21) to generate an estimate of average daily dollar volume traded. In excel I’m able to see the first 500 rows, but below that I start getting NA for volume data. Is there a way I can get this data to work with visibly? thanks,
In the attachment, note how data changes in the download after the 500th row. thanks
OK, thanks everybody for the info. I’ve had the same issue previously w/ other data I was exporting, so I was expecting that might be the case instead of a bug, but thanks for confirm.
Do most of you use an external database for better understanding the underlying data itself that makes up your ranking systems, or do you stay in p123? I admit I’m struggling a bit when I’m trying to understand the range of data underlying the ranking systems.
For example, I’m working with financial strength data currently, and it’s the type of data where “more” is not always better from a return standpoint, so I’m trying to better understand and link the rank percentiles with the values of the underlying range of calculations used to create the ranks - to understand for instance, about where does debt become too much, where is it too little, in what cases is a certain amount of debt ok, when is it not (coverage, cashflow to debt), why does the ranking system fall apart at the very top and experience diminishing returns at the positive extreme of the rank, can I identify extreme values of the underlying data to exclude rather than limiting by FRank which seems iffy approach to me, why do these low/no debt companies perform so poorly, are some of my calcs just freaking at the extremes for some reason I can correct, etc…
If I could get the data out and into excel, I think I could link it together to better see what is happening. But admit I’m having trouble inside of p123 trying to address the above types of questions.
To better understand the distribution and range of factor values, data->data views->factor distribution graphs is sometime useful. Unfortunately, there’s no way to limit the charts to a particular universe.
Hi Walter, thanks. That’s sortof what I’m looking for, and can be helpful.
Ideally, I think what I’d like is something like the stock rank report in the ranking system, but instead of showing the rank for each factor like it does, have it show the underlying calculation or value for each factor that makes up the rank, to see the combination of factors occurring at extremes.
We’re preparing to announce an “Expanded Access” license that will not have any download limits, and other things like additional Compustat line items and an API. It will however require a license with S&P.
On the other hand having the ability to quickly plot a histogram on any formula is in the todo list.
As I think about it, the ability to see the actual data next to the ranks is really what I’m going for and is main reason presently why I’d like to get data into excel. If I could see it together in a table I probably wouldn’t need to download, but I understand how that would be the most straightforward solution.
For example, in the rank report, currently shows something like this (edit: I apologize for my lousy formatting below).
Current Rank Report showing percentiles (rough made-up example)
…I think that’d help me better see what’s going on at extremes of the ranking distributions where I can view odd outliers or perhaps where calcs have gone wrong and need to be controlled or reconsidered, or understand thematically, in broad strokes, what’s happening at very extreme. (I find myself often wondering what a calc in a ranking system is doing at the extremes where my buys will be happening). I think glancing at a table like that would help me understand quickly what’s happening.
Anyhow, I’ll leave the thought at that. I know you’re busy and have lots going on, but I wanted to throw that out there. Thanks for the support. Appreciated.
I really like Michael’s suggestion above (a toggle to provide the actual numbers rather than the ranks). I would love to be able to get this information at a glance instead of having to look it up for each stock.
Marco, I know you’re very busy, but just to let you know - being able to view/toggle the actuals on screen aside the rank (even without download, or only for latest non-historical) would be “super helpful” from my perspective when building a ranking system, especially when trying to make sure a ranking calc is doing what is expected, or in understanding where it’s producing unexpected results
MARCO, +1 for expanded download license! You know my position about this… However, over the last few years, thanks to the many improved functionalities added, I’ve been able to replicate most of my Excel work into screener. The download would be nice but it doesn’t help when getting a Designer Model operating.
Now, I’d pay handsomely for the ability to have Dynamic Weightings in Ranker… Or even a function 'WEIGHT(“formula”,[scope, etc])
That’s all that’s missing in my work here.
Oh yeah…and “Rating” in custom universe. That would be nice!
Expanded access requires a data license with vendor.
What we can do in screen reports is to allow technical columns since that data is not from Factset or S&P. We did this for Tools>Download Factors tool . If you create a Factor List you will be able to download technical factors in the raw form.
Much of the time raw data is not needed for machine learning.
So, could ranks of features also be expanded? This is an old question and the answer has always has been that ranks of features could be expanded if it were a priority.
Downloads make that less of a necessity for me personally now. Maybe I don't need it at all anymore. I appreciate P123 making the array necessary for machine learning (features in rank form and target indexed by date) available in some form already.
Also downloads could be expanded to include overnight updates--on Wednesday say--generating some revenue and covering the cost of providing this to SpacemanJones and anyone else interested.
Some are doing the last with the API, I think, and I could probably learn to do that so too, So not necessarily a priority, but I might occasionally use an updated Wednesday or Friday download as I have not started using the API to rebalance yet.
I actually was using data from DataMiner to test models. I updated my data today with the Download Tool.
I agree: "useful." I will be starting a new port as early as Monday based on the new data. And a reasonable price, I think. A change since DataMiner? Reasonable in any case.