I used the universe mean vs my method and get the same result! Much more succinct. I assume the lambda function will also correctly subtract the universe gains from the stock gains to get the alpha, but I did not check it.
I am personally more interested in a CAGR or alpha as my success method than an R^2 score. Partially because r2 is not intuitive for me in the sense that my model may predict well, but I don’t know what that means in terms of return on investment haha.
This is actually my full code if you want to run it. I only know it works in colab, but probably should locally as well. Also I used a class so running the individual functions is a little different, but it makes adding the inputs easier. Also if you use a decent editor for python code it will give you prompts as you type in the input. Dan and Portfolio123 the doc strings would be a nice update for the python api if you are ever doing one!
Note you have to go to the bottom of the long post to see the examples. I tried an expanding section, but it messed up the code…
# NOTE: Google Colab uses Python 3.7
!pip install --upgrade p123api # Install p123api if missing
import p123api
import pandas as pd
from datetime import timedelta, datetime
class Portfolio123API:
def __init__(self, api_id, api_key):
self.client = p123api.Client(api_id=api_id, api_key=api_key)
def rank_update(self, xml_str, type='stock', method=4, currency='USD'):
"""
Update or create the ApiRankingSystem using provided XML string.
Parameters:
-----------
xml_str : str
XML data containing ranking information to be updated. Like from the ranking text editor.
type : str, optional
Type of ranking data, e.g., 'stock' or 'asset', default is 'stock'.
method : int, optional
Numeric code representing the ranking update method, default is 4. 2-Percentile NAs Negative, 4-Percentile NAs Neutral
currency : str, optional
Currency for monetary values, default is 'USD'.
Returns:
--------
bool
Returns True indicating the successful update of rankings.
"""
self.client.rank_update({
"type": type,
"rankingMethod": method,
"nodes": xml_str,
"currency": currency
})
return True
def download_rank(self, universe, ranking_name, date, add_data, pit='Prelim', precision=4, method=4, names=False, NACnt=True, finalStmt=True, node_type='factor', currency='USD'):
"""
Generate a ranking pandas DataFrame based on the provided inputs. Uses 1 api credit per 25,000 data points as of Aug 2023.
Parameters:
-----------
universe : str
Name of the universe on Portfolio123.
ranking_name : str
Name of the ranking system on Portfolio123.
date : str
Date for which the ranking is being generated. Format is 'YYYY-MM-DD'
add_data : list
Additional data to be considered for ranking. like 'Close(0)' which is fridays close. Note some things may require the PIT license.
pit : str, optional
Period in time, e.g., 'Prelim' or 'Complete', default is 'Prelim'.
precision : int, optional
Number of decimal places for ranking scores, default is 4.
method : int, optional
Numeric code representing the ranking method, default is 4 which is neutral, 2 is negative.
names : bool, optional
Flag indicating whether to include ticker names in the output, default is False.
NACnt : bool, optional
Flag indicating whether to include the count of missing values, default is True.
finalStmt : bool, optional
Flag indicating whether to include if the stock has a final statement, default is True.
node_type : str, optional
Type of node for ranking, e.g., 'factor' or 'composite', default is 'factor'.
currency : str, optional
Currency for monetary values, default is 'USD'. 'USD' | 'CAD' | 'EUR' | 'GBP' | 'CHF'
Returns:
--------
pandas.DataFrame
A DataFrame containing the generated ranking data. Added the date as a column
"""
ranking = self.client.rank_ranks({
'rankingSystem': ranking_name,
'asOfDt': date, # Formated as 'yyyy-mm-dd'
'universe': universe,
'pitMethod': pit,
'precision': precision,
'rankingMethod': method, # 2-Percentile NAs Negative, 4-Percentile NAs Neutral
'includeNames': names,
'includeNaCnt': NACnt,
'includeFinalStmt': finalStmt,
'nodeDetails': node_type, # 'factor', 'composite'
'currency': currency,
'additionalData': add_data # Example: ['Close(0)', 'mktcap', "ZScore(`Pr2SalesQ`,#All)"]
},True) # True - output to Pandas DataFrame | [False] to JSON.
dates = pd.to_datetime([date]*len(ranking))
dates = pd.to_datetime([date]*len(ranking))
ranking.insert(0, 'Date', dates)
return ranking
def rank_perf(self, universe, ranking_name, start_date, end_date, slippage, pit='Prelim', precision=4, trans_type='Long', method=4, num_buckets=10, minP=3, freq='Every Week', bench='SPY'):
"""
Calculate rankings and return relevant data.
Parameters:
-----------
universe : str
Universe name same as P123
ranking_name : str
Name of the ranking system to be used, should match P123 ranking sys
start_date : str
Start date for the calculation period in the format 'yyyy-mm-dd'
end_date : str
End date for the calculation period in the format 'yyyy-mm-dd'
slippage : float
Value representing slippage for transactions. 0-1
pit : str, optional
Period in time, e.g., 'Prelim' or 'Complete', default is 'Prelim'.
precision : int, optional
Number of decimal places for ranking scores, default is 4. 2-4
trans_type : str, optional
Type of transaction, e.g., 'Long' or 'Short', default is 'Long'.
method : int, optional
Numeric code representing the ranking method, default is 4. 2-Percentile NAs Negative, 4-Percentile NAs Neutral
num_buckets : int, optional
Number of buckets for ranking, default is 10.
minP : int, optional
Minimum stock price, default is 3.
freq : str, optional
Frequency of calculation, e.g., 'Every 4 Weeks' | 'Every Week' | 'Every N Weeks' (2,3,4,6,8,13,26,52), default is every week.
bench : str, optional
Benchmark for comparison, e.g. available benchmarks on P123, default is 'SPY'.
Returns:
--------
df : pandas.DataFrame
A DataFrame containing calculated ranking data.
quota : int
An integer with the remaining quota
"""
results = self.client.rank_perf({
'rankingSystem': ranking_name,
'startDt': start_date,
'endDt': end_date,
'pitMethod': pit,
'precision': precision,
'universe': universe,
'transType': trans_type,
'rankingMethod': method,
'numBuckets': num_buckets,
'minPrice': minP,
'rebalFreq': freq,
'slippage': slippage,
'benchmark': bench,
'outputType': 'perf'}) # only perf with this function
dates = results['dates']
benchmark = results['benchmarkSeries']
buckets = results['bucketSeries']
quota = results['quotaRemaining']
# Scale benchmark
scaled_benchmark = [100 * (value / benchmark[0]) for value in benchmark]
# Create DataFrame
data = {'dates': dates, 'benchmark': scaled_benchmark}
for i, bucket_values in enumerate(buckets, start=1):
data[f'bucket{i}'] = bucket_values
df = pd.DataFrame(data)
return [df, quota]
def download_universe(self, universe, date, formulas, pit='Prelim', precision=4, names=False, currency='USD'):
"""
Generate a pandas DataFrame based on the provided inputs. Uses 1 api credit per 25,000 data points as of Aug 2023.
Parameters:
-----------
universe : str
Name of the universe on Portfolio123.
date : str
Date for which the ranking is being generated. Format is 'YYYY-MM-DD'
formulas : list
Additional data to be considered for ranking. like 'Close(0)' which is fridays close. Note some things may require the PIT license.
pit : str, optional
Period in time, e.g., 'Prelim' or 'Complete', default is 'Prelim'.
precision : int, optional
Number of decimal places for ranking scores, default is 4.
names : bool, optional
Flag indicating whether to include ticker names in the output, default is False.
currency : str, optional
Currency for monetary values, default is 'USD'. 'USD' | 'CAD' | 'EUR' | 'GBP' | 'CHF'
Returns:
--------
pandas.DataFrame
A DataFrame containing the generated ranking data. Added the date as a column
"""
ranking = self.client.data_universe({
'universe': universe,
'asOfDt': date, # 'yyyy-mm-dd'
'formulas': formulas, # ['Close(0)', 'mktcap']
'pitMethod': pit,
'precision': precision,
'includeNames': names,
'currency': currency
},True) # True - output to Pandas DataFrame | [False] to JSON.
dates = pd.to_datetime([date]*len(ranking))
ranking.insert(0, 'Date', dates)
return ranking
def download_weekly_ranks(self, universe, ranking_name, start_date, end_date, add_data, pit='Prelim', precision=4, method=4, names=False, NACnt=True, finalStmt=True, node_type='factor', currency='USD'):
"""
Download ranking from multiple dates. Note that to calculate some additional stats like alpha to the universe some additional date is required!
Uses 1 api credit per 25,000 data points as of Aug 2023.
Parameters:
-----------
universe : str
Name of the universe on Portfolio123.
ranking_name : str
Name of the ranking system on Portfolio123.
start_date : str
Start date to get data. Format is 'YYYY-MM-DD'. Note that the resulting dataframe will use the previous Saturday as the date
end_date : str
End date to get data. Format is 'YYYY-MM-DD'. Note that the resulting dataframe will use the previous SSaturday as the date
add_data : list
Additional data to be considered for ranking. like 'Close(0)' which is fridays close. Note some things may require the PIT license.
pit : str, optional
Period in time, e.g., 'Prelim' or 'Complete', default is 'Prelim'.
precision : int, optional
Number of decimal places for ranking scores, default is 4.
method : int, optional
Numeric code representing the ranking method, default is 4 which is neutral, 2 is negative.
names : bool, optional
Flag indicating whether to include ticker names in the output, default is False.
NACnt : bool, optional
Flag indicating whether to include the count of missing values, default is True.
finalStmt : bool, optional
Flag indicating whether to include if the stock has a final statement, default is True.
node_type : str, optional
Type of node for ranking, e.g., 'factor' or 'composite', default is 'factor'.
currency : str, optional
Currency for monetary values, default is 'USD'. 'USD' | 'CAD' | 'EUR' | 'GBP' | 'CHF'
Returns:
--------
pandas.DataFrame
A DataFrame containing the generated ranking data from one date to another
"""
current_date = datetime.strptime(start_date, '%Y-%m-%d')
end_date = datetime.strptime(end_date, '%Y-%m-%d')
combined_dataframe = pd.DataFrame()
required_data = ['(Open(-6)-Open(-1))/Open(-1)']# This gives a Monday to Monday open gain which is what I trade. Change if you trade another time
while current_date <= end_date:
previous_saturday = current_date - timedelta(days=(current_date.weekday() + 1) % 7) # This calculates a more accurate asofDate
previous_saturday_str = previous_saturday.strftime('%Y-%m-%d')
dataframe = self.download_rank(universe, ranking_name, previous_saturday_str, required_data+add_data, pit, precision, method, names, NACnt, finalStmt, node_type, currency)
dataframe.rename(columns={'formula1': 'MM_gain'}, inplace=True)
# Calculate the universe gain and then each stocks alpha!
univ_gain_percentage = dataframe['MM_gain'].mean() # Calculate the universe return
dataframe['univ_alpha'] = dataframe['MM_gain']-univ_gain_percentage # Calculate the alpha and add to the dataframe
combined_dataframe = pd.concat([combined_dataframe, dataframe], ignore_index=True) # Add it to the dataframe
current_date += timedelta(weeks=1)
return combined_dataframe
Here are the examples for each api function: Make sure to only run the one you want and not all of them or you will burn your credits. Also I did not add them all, just the rank related ones for now.
# Initialize the api class
api_id = 'Your api id'
api_key = 'Your api key'
api = Portfolio123API(api_id, api_key)
#-------------- Examples for each function below -------------------------------
# Update a ranking system ------------------------------------
xml_str = '''
<RankingSystem RankType="Higher">
<StockFormula Weight="0" RankType="Higher" Name="Factor" Description="" Scope="Universe">
<Formula>PEExclXorQ</Formula>
</StockFormula>
</RankingSystem>
''' # this string needs to match the format of the xml string in portfolio123 ranking system
api.rank_update(xml_str, 'stock') # note it will return True if it completes, but otherwise gives no indication it completed
print("API Ranking system updated!")
# Download ranks from a ranking system ------------------------------------
ranks = api.download_rank('Easy to Trade US', 'All-Stars: Greenblatt', '2023-05-04', ['Close(-1)'])
# Note that the (0) date is always the friday before the date given. (-1) is a Monday or the day after the Friday. The date you give does not matter!
print("Ranks from ranking system are:\n")
print(ranks)
# Download data from a universe ------------------------------------
universe_data = api.download_universe('Easy to Trade US', '2023-05-04', ['Close(-1)'])
# Note that the (0) date is always the friday before the date given. (-1) is a Monday or the day after the Friday. The date you give does not matter!
print("Universe data is as follows:\n")
print(universe_data)
# Calculate rank performance ------------------------------------
[perf, quota] = api.rank_perf('Easy to Trade US', 'All-Stars: Greenblatt', '2013-01-01', '2023-01-01', 0.25)
print("Remaining quota is: " + str(quota))
print("Performance plot below:")
perf.plot()
# Download ranks over multiple dates! Includes universe alpha calculated column
# Note that this function adds a universe alpha column that is based on Monday open to Monday open future returns!
weekly_ranks = api.download_weekly_ranks('Large Cap', 'All-Stars: Greenblatt', '2023-07-01', '2023-07-31', ['Close(-6)/Close(-1)-1'])
# Save to a pickle which is very fast to load, but not human readable
weekly_ranks.to_pickle('data.pkl') # This saves the data as a pickle. You can load it using: weekly_ranks = pd.read_pickle('data.pkl')
# Save to a csv, slow to load, but human readable
weekly_ranks.to_csv('data.csv', index=False) # To load it again use: weekly_ranks = pd.read_csv('data.csv')
print("Ranks from ranking system are:\n")
print(weekly_ranks)
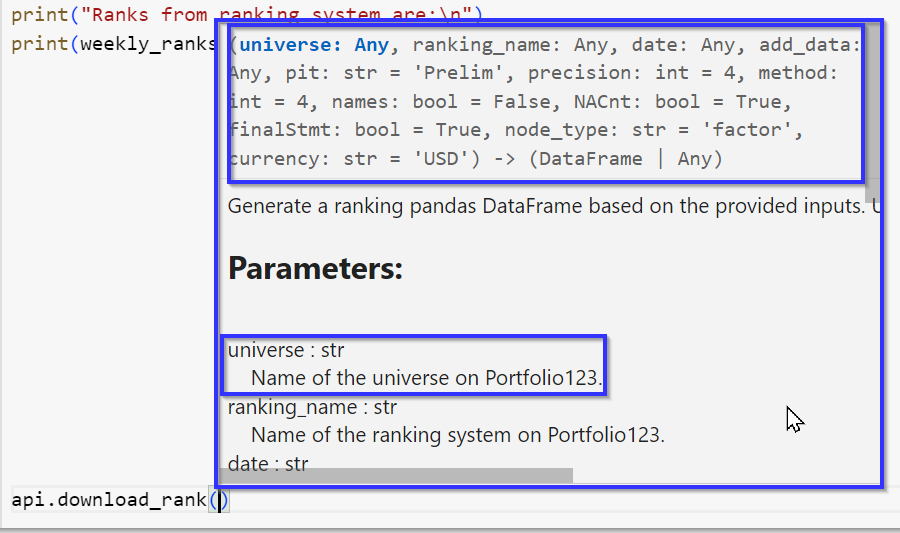
Example of the prompts as you type (from the doc strings):
Thanks,
Jonpaul