When I try and load a dataset with rank scaling I get a message:
Invalid feature normalization: "Dataset" is not compatible with the "Rank" scaling.
What type of feature can't be used with Rank scaling?
This message comes up when loading the dataset if you have features where Step 2 is set to 'Dataset' and you change the Normalization of the dataset to Rank from Z-score. When adding features, 'Dataset' is never an option if Normalization is set to Rank. But you could add the features while Normalization is set to Z-Score and choose 'dataset' and then change the Normalization to Rank which makes those features with 'dataset' invalid. To resolve the error and keep Normalization = Rank, change any features that are using 'dataset' to use 'date'.
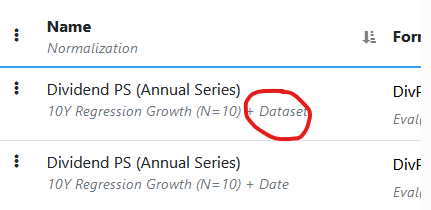
Thanks, that works. But I discovered that in the past I have always been choosing date. However when I go back and look at previous factor sets, the Target % Universe screen shows "Date" but the Features show Raw data + Dataset. How did the Dataset get there I have never selected this before?
A second question. The normalization says "Raw Value" when I selected Rank. Is this correct? Have the normalization options changed? If so how does one select the different methods?
In version 1.0 of AI Factor you only had one normalization option for BOTH target and features. It could either be
- Rank cross sectionally by date
- Z-score cross sectionally by date or entire dataset
(MinMax has been deprecated since you can achieve the same with Z-score and very large σ limit)
The new version (1.1?) is a lot more flexible for target and feature normalization, but both still share the choice scaler: either percentile rank or z-score. Once the scaler is chosen there are differences. I'll discuss them separately
Target
Targets can be normalized cross-sectionally vs. stocks on the same date, or vs. entire dataset when z-score is used. We had to allow this for backward compatibility, but it's confusing. Also not sure if we can tell you when should you use one or the other. Until we figure it out we leave it up to you (there are even more choices we left out for target, like normalizing cross-sectionally vs other stocks in the sector)
It's also bit strange that the scaling choice is done in the middle of the flow (see image below)
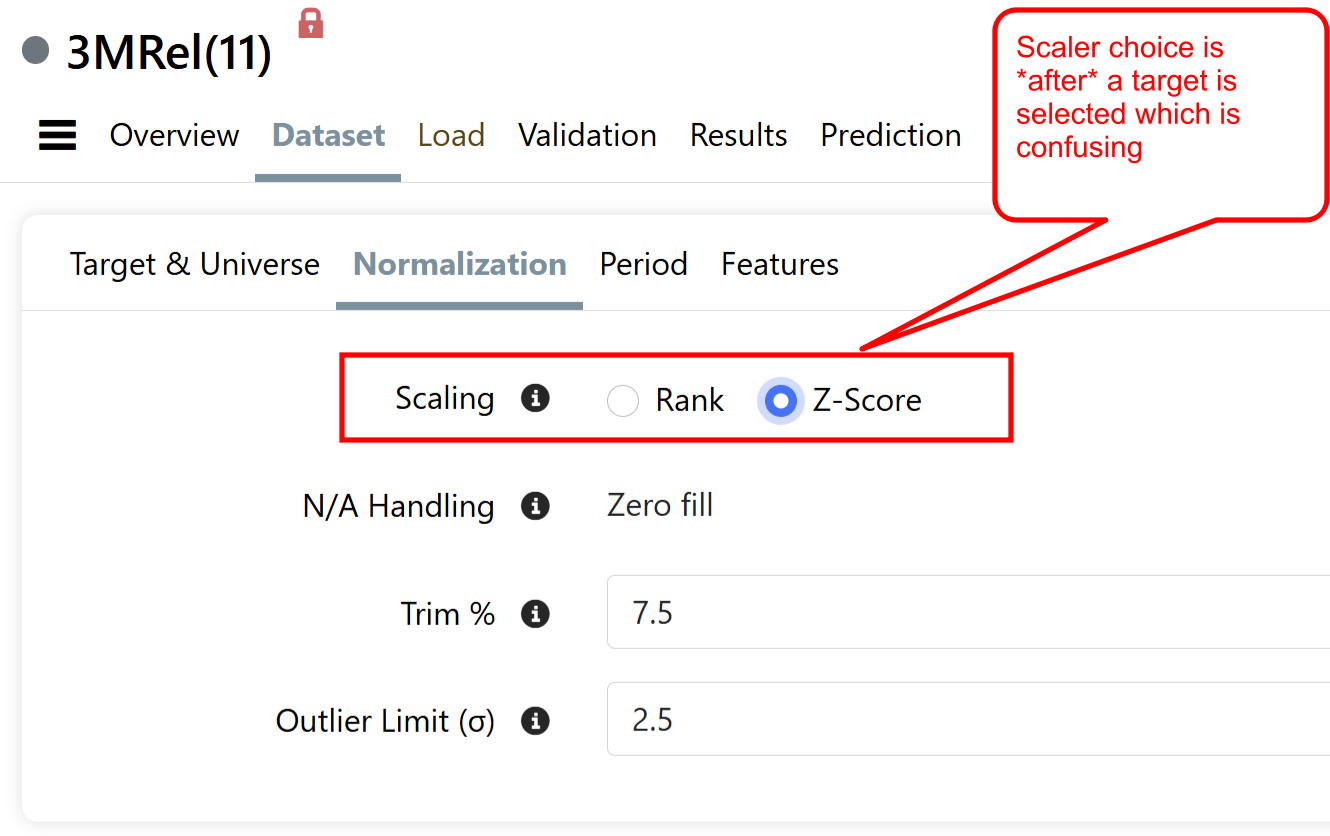
That's about it for Target. Features have a lot more options
Features
They are normalized in two steps:
Step 1 is the "local normalization" . In other words how you normalize the value against prior values. You can choose "Raw" which means don't do anything (we should rename this to "skip") or vs. values in the previous year, a regression, etc.
Step 2 is the "cross sectional normalization" or vs. other stocks. Lots of options here like by date, vs. other stocks in the sector, or entire dataset.
Conclusion
More flexibility = more power = more confusion (at first).
We'll be tweaking things to improve usability, figure out what makes a difference and what doesn't as we learn with you. We might also add other options like ability of passing NAs through to the algorithms that support them.
But bottom line is that, at them moment, we can't precisely tell you why you should do one vs. the other. What we do know is that version 1.0 was way too simple.
Hope this helps.
1 Like
Seems like we missed a step when we released the upgrades to retro-fit v1.0 of the AI Factor. Looking into this and implications. Sorry about this.
Problem with older AI Factors showing inconsistent normalization should be fixed.
The only problem this would have caused is if you copied the old AI Factor after the new release you would end up with a different normalization.
Thanks again
Can we include variables like Vix level, yield curve (10-2s), interest rate level, etc. into the AI factor module?
If so, can someone points us to how to do that?
Seems like this would be incredibly useful to understand either regimes (i.e. trees) or sensitives (regressions), or something in between (deep learning).
Thank you,
We have that data. Did you click on "Add Predefined" and check out the Macro features? Vix and interest rates are there, but not yield curve. What exactly do you want to tell the AI model? Normal, inverted or flat? or something more than that?
And we need to understand your use case better
You still want to predict each individual stock, correct? Like the future 3Mo relative performance of the stock. Then the only trick is to figure out how to normalize macro data. Current values like the Vix index and interest level should be ok as AI features since they are stationary (range bound), others are not (like gold price). The predefined vix feature is passed to the AI backend as raw value and it's then normalized using Min/Max, but you could also choose to leave it as a raw value.
Or are you trying to develop a market timing model. In other words a model to tell you things like "go to cash". There's a way to hack the current AI Factor to do this, but we do plan a cleaner way to do it.
1 Like
I want the AI model to determine my target return formula, when including the level of the those variables. This should help in the following scenario examples:
A higher Vix environment - all else equal, should lead to fundamentally weaker companies doing relatively worse than others. Also more volatile stocks will underperform less volatile stocks. When the VIX reverts from high levels, the opposite is true. When the VIX is low, well...we all have models that are premised on that.
ZIRP leads to higher relative returns for growth stocks (i.e. bad for low PE stocks).
Steeper yield curve will results in better excess returns for bank stocks.
Etc.
I'm not looking for market timing - no way. In effect, the AI will create models that include the macro climate.
Did I explain it well?
1 Like
Click on "Add Predefined" and add the following predefined features:
VIX index
10-Year T-Bill
10-2 Treasury Yield Spread
Your AI Factor features should look like the image below. Then proceed to add the rest of the features.
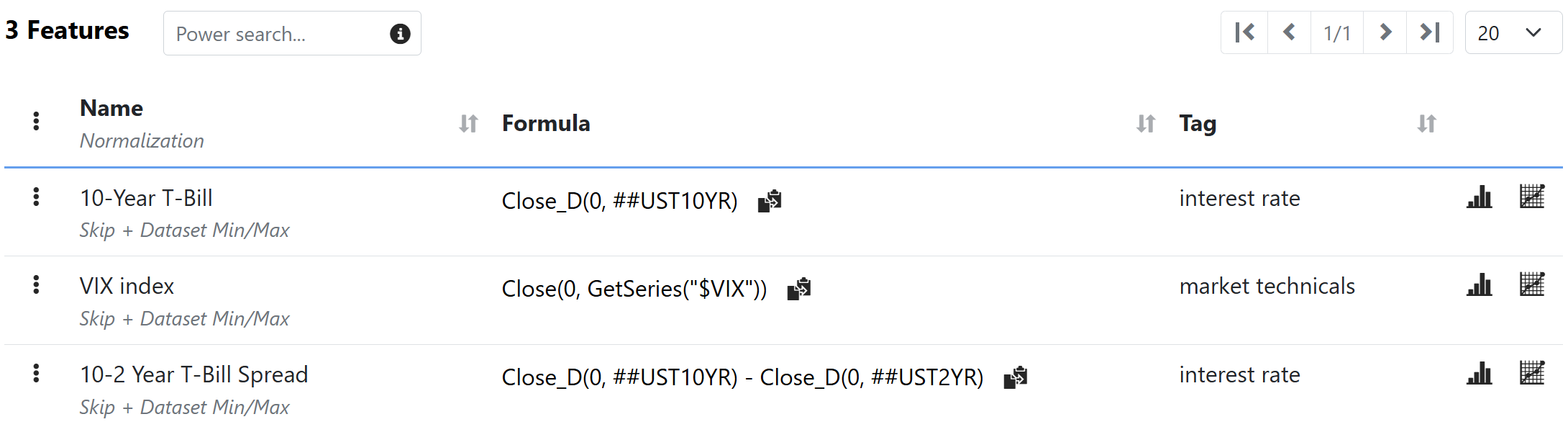
Notice the macro features use a special 2nd step cross normalization "DataSet Min/Max" which should work well with macro data (normalization is very nuanced and we will be providing more guidance soon).
Lastly you can click on the chart icon to visualize your features in the Fundamental Chart. With some fiddling I produced this:
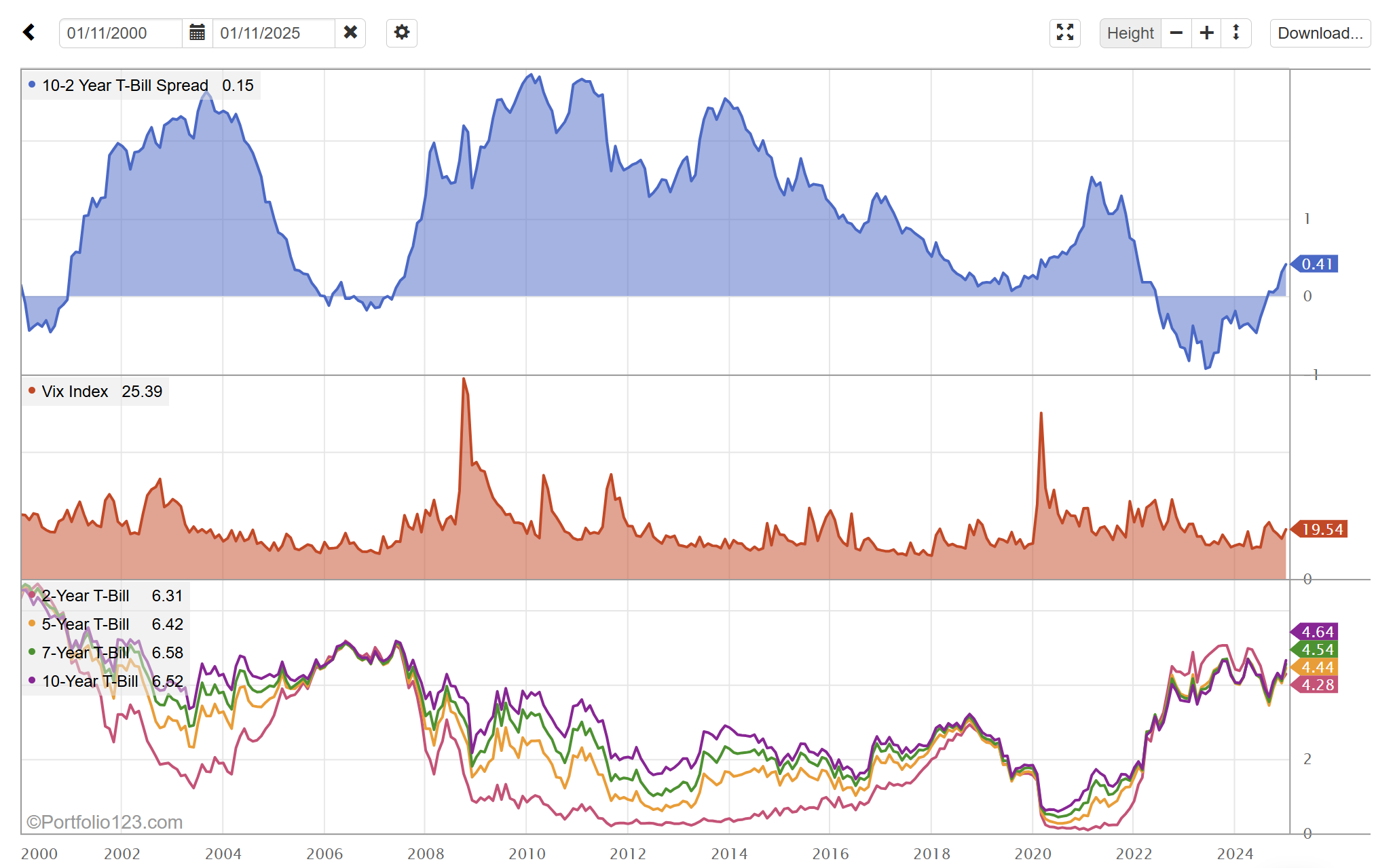
Hope this helps.
1 Like
Thank you for the reply, Marco!
I have two important questions:
-
How does min/max normalization transform the data? I’ve always avoided using it cause it's less clear than a z-score or rank, but I’d love to see a simple spreadsheet that demonstrates how normalization works across different methods.
-
I’ve also steered clear of “entire dataset” normalization methods due to concerns about potential lookahead bias. On any given date, we should only rely on current date values (e.g., rank) or backward-looking loop functions. To state the obvious, I know you're aware of this principle. I also avoid any approaches like k-factor folds that involve looking ahead and then testing on past data—just my methodology.
Could you provide an example of how “entire dataset” normalization is applied to ensure it avoids any data on a future data upon which a model is trained?
Thank you again!
There's not much to it. It's the standard min/max normalization but we're subtracting 0.5 and multiplying by 2 so it's centered around 0 and ranges from -1 to 1 so it's more uniform with other normalizations you might use in other features. This is important now since we've opened up the ability to normalize each feature differently.
We are specifically using a Min Max Normalization for macro ratios because it does the following:
- Sets any NAs to 0 which causes problems for certain algorithms
- Preserves the magnitude of the differences
- The multiple identical values on each date do not affect the normalized values
So for macro features is the safest, and the rescaling doesn't matter to the algorithm. The algorithm (whether a tree or what not) doesn't care whether it sees 7% or 14% or 0.45 and 0.90. Both are 2x the previous value.
We think it's generally ok for stationary data, that is data whose statistical properties do not change over time. Things like 1 Mo % returns will always have mean a little to the right of zero, or 10Y Treasury Rate will always be range bound... at least in the US ![]()
In fact, for stationary data, a dataset normalization might even be preferable. But, as always, it all depends on what you are trying to communicate to the AI model, and your training period.
Best
PS. A potential future enhancement, instead of calculating the mean and standard deviation from your dataset, is to always use the same statistics. These statistics would be computed for each feature/formula a-priori, from a fixed universe, and stored. You could then use them to normalize those same features/formulas regardless of what universe or period your AI factor uses.
1 Like
The biggest issue is we don't even test the data for stationality- so it's folly to build systems knowing which feature is stationary.
That being said:
- Future events, like the VIX spike during COVID-19 (~80), distort past risk estimates, creating an inaccurate view of historical volatility. This is particularly dangerous with non linear modelling.
- Financial data often changes over time (e.g., post-2008 returns or rate shifts during COVID), invalidating assumptions of stable statistical properties.
- Risk and return assessments become even more unreliable, as extreme future events misrepresent past conditions.
- Simulations fail when future-normalized data alters pre-crisis distributions, like during Black Monday or 2008.
Normalization should only use data available at the time, ensuring unbiased, realistic analysis. Strange, imo.
What normalization would you want for the VIX then? Normalize it vs the previous 3 years? You can do that with:
Step 1: 3Y Relative Hist (N=20)
Step 2: Skip
This normalizes the VIX vs. previous 3Y values using z-score sampled 20 times (every 8 weeks). Should look like this

1 Like
Marco, you said "Or are you trying to develop a market timing model. In other words a model to tell you things like "go to cash". There's a way to hack the current AI Factor to do this, but we do plan a cleaner way to do it.". I would be interested in what this consists of. I thought of ranking a two symbol universe consisting of SPY and SHY but P123 doesnt support ETF's for AI.. at least i could not find a way to do so. What is your hack?
My understanding is that it means no normalisation at all (raw values).
That's correct. Raw values are passed to the algo which causes problems for most algos. Also I believe NAs are not set to 0, which causes most algos to quit with errors.
Until we make it robust, and clearly present use-cases, we should probably hide it since it requires deep understanding.
NA is zero filled with Skip. This may seem an odd option as the features have an arbitrary distribution, but filling with zero served our needs as all other normalization in place centers features around zero.