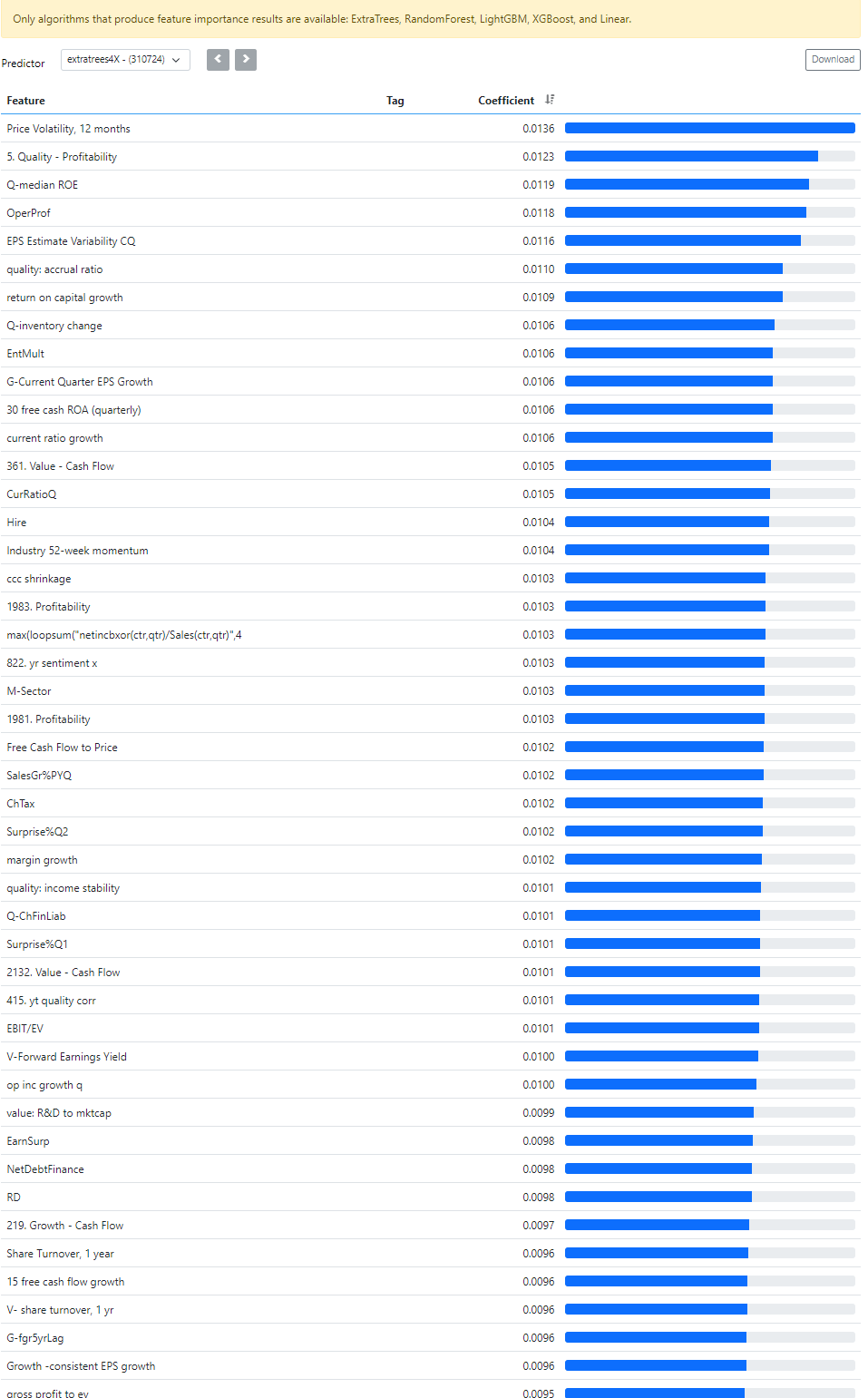
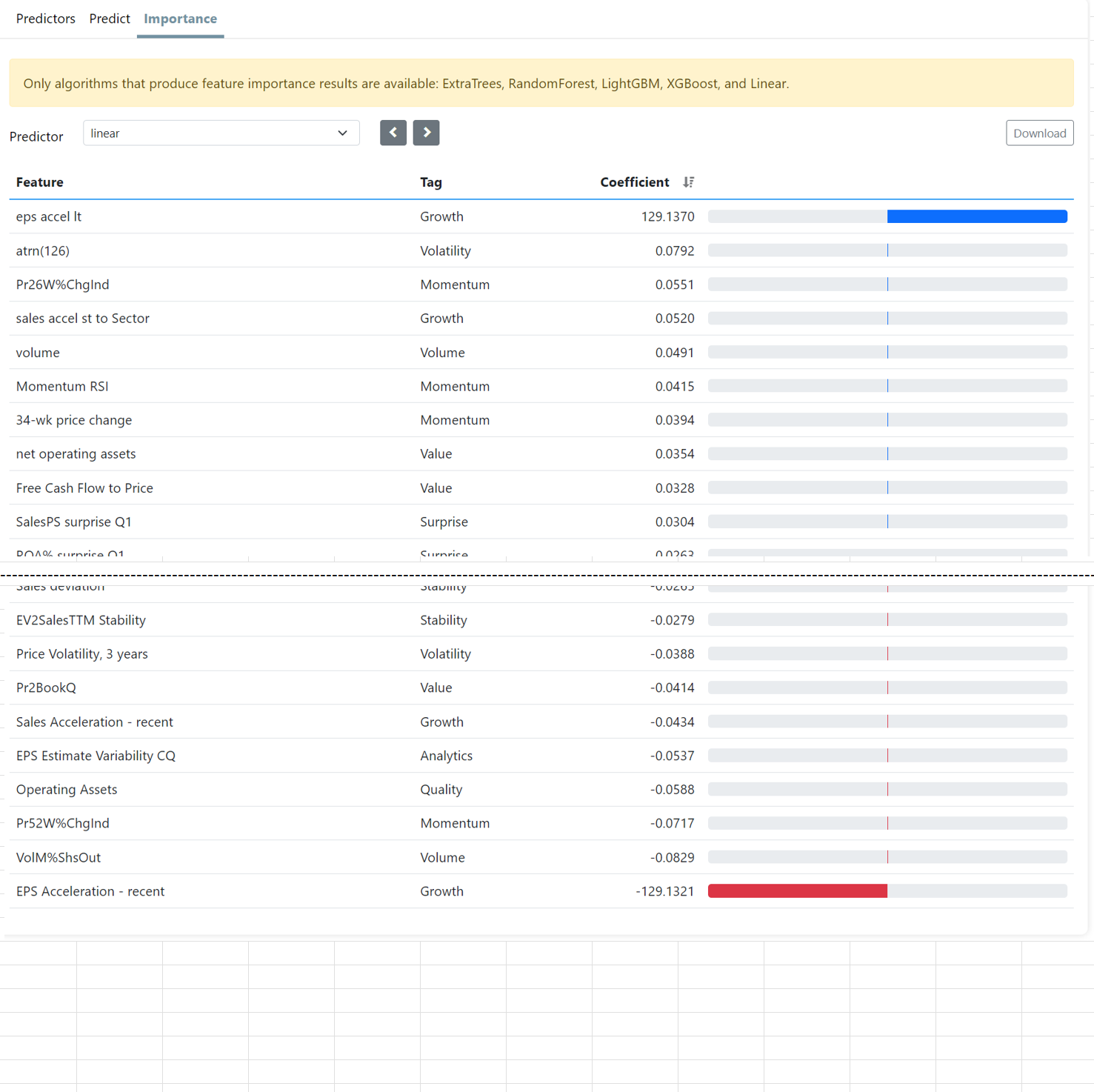
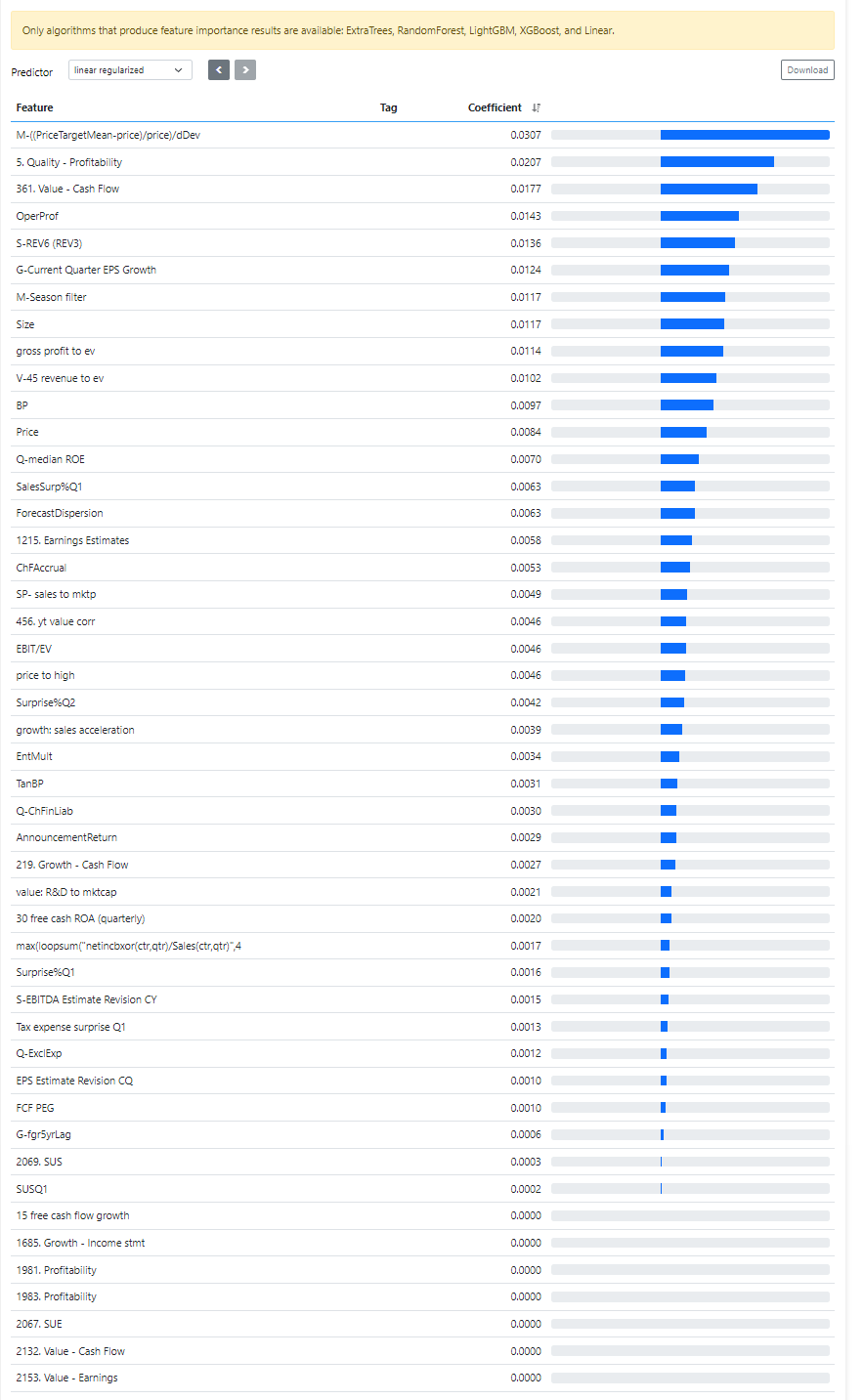
I thought that ML models not only weighted each individual feature based on training but could also completely remove certain features if they did not provide better results.
However, when I look at the Importance - Coefficient, it seems that all the features I had in this test are assigned a weight. If the model always chooses to use all features, I understand why it doesn’t always help to simply add as many features as possible.
As far as i am understanding it, its just curve fitting the best performing stocks to your features. More features = more possibilities for the ML algo to do this.
But that doesn't mean your out of sample performance will be better. The more noise you add, the worse your long term out of sample performance will be.
I was going to posting this idea before I noticed that ZGWZ said it first. I think this is spot -on. If you don't want to use a "normal OLS model" which you probably do not, you might try Ridge Regression, LASSO regression or if you are using the API, Elastic Net regression.
Each of these provide regularization and help with collinearity. Just to expand on ZGWZ's excellent point.
If I were to try a different approach to the entire ML model, how can I best transfer the findings from an ML model to create a ranking system based on it? What would that entail?
What about taking the nodes in the ranking system (the features in the ML models) that score highest on the Coefficient and assigning them weights in a ranking system? What is the best way to do that?, and will it work?
Train the ML model with rank (not z-score or min/max) and just use the coefficients of a LINEAR ML MODEL as weights in the ranking system.
Should be the same as if you chose to use "predict" with the AI and pay for the rebalance. This is called rank regression which works nicely with the fact that P123 uses a ranking system.
This turns out to be just another way to optimize P123 classic. Possibly replacing the optimization method you use now which is an evolutionary algorithm. Not necessarily better than what you do now BTW except you have an easier way to cross-validate with the P123 AI. Easier than some methods done a few months ago with P123, IMHO
P123 classic is nice and evolutionary algorithms (regression as well) to optimize it WORK WELL. I think the main addition @marco has provided with the AI is the excellent methods of cross-validation to reduce overfitting.
Skip the $100 per month rebalance charge.
@marco might consider redoing some of this with the idea of minimizing his computer resources overhead and passing some of the savings onto the user where possible.
I note that the above will use vastly fewer resources than many of the present optimization strategies. Regression has few memory -storage issues (just the coefficients).
Or not. But as outlined the AI/ML with a rebalance is not a trivial cost and there are trivial ways to get around the cost. Trivial for the user and trivial for P123 if they want to reduce their computer-resource costs—passing some of the savings to members..
But if I want to use rank regression, why would I pay for the AI.ML? While being a big fan of AI.ML and being part of the reason it was adopted according to @marco. Advanced users to not really need it at that cost, perhaps.
I do like what P123 has done and I am still looking for something to justify the cost but my present ML models perform well.
I sometimes use OLS models with a maximum number of iterations of 10 to minimize this problem. But if you use the default settings, the problem is worse.
The default linear regularized method is actually the E-NET algorithm. Its name is confusing.
Ridge + Very Early Stop is always better than the default E-NET algorithm. And I always use the absolute values of its coefficients as feature importance.
They use the ElasticNet function instead of the ElasticNetCV function or the SGDRegressor function. However, you still can't test different max_iter in the later.
"Number of iterations run by the coordinate descent solver to reach the specified tolerance."
NOT a type of gradient descent it seems but a standard optimization method for sure. I plan on trying a different method for optimization of the features using Sklearn-genetic-opt
Of course, I do not know if this will be better or worse. But think it will pick up interactions of variables better. Not sure the this is necessarily a good thing as it will be more prone to overfitting or changes in non-stationary markets.
Thank you. Very informative!!!
Claude 3 generated some code for making a comparison of the 2 optimization methods above. It was straight-forward and most members can do it themselves with or without ChatGPT (if interested) so not included here. It has this to say about a long discussion about interactions: "Overall, your intuition about the GA picking up on interactions is correct,….."
And the answer to the question "Does a ridge regression pick up on interactions (if there are no interaction variables?)": "No, a standard ridge regression does not pick up on interactions between variables if interaction terms are not explicitly included in the model."