Hi All, I’m posting this in General rather than AI Factor because these NA issues likely affect anyone creating standard ranking systems for Canadian universes. not just AI workflows.
After testing and a full factor audit using ChatGPT-5, here’s what I’ve discovered so far about building Portfolio123 AI Factors for Canadian stocks:
Heavy fundamentals (EPS, EBITDA, margins) = high NA risk, especially pre-2012.Analyst estimates, ownership, and short interest? Often ≥30% NA.
So I pivoted to low-NA families, examples:
Momentum (Pr26W%Chg, Pr52W%Chg/PctDev(52,5))Pullback (RSI(10), Close(0)/SMA(20))Technical breadth (UpDownRatio(20,0), ATRN(20,0)/ATRN(20,20))Liquidity & execution (MktCap, (LoopAvg("Spread(CTR)",20)/Price)*-100)If fundamentals are needed, I gate them with Eval() to avoid NA blowups.
I attached a list of factors and several spreadsheets from my AI Factor builds that had high NA rates. Based on that, ChatGPT-5 generated this infographic comparing factor families by coverage vs NA risk:
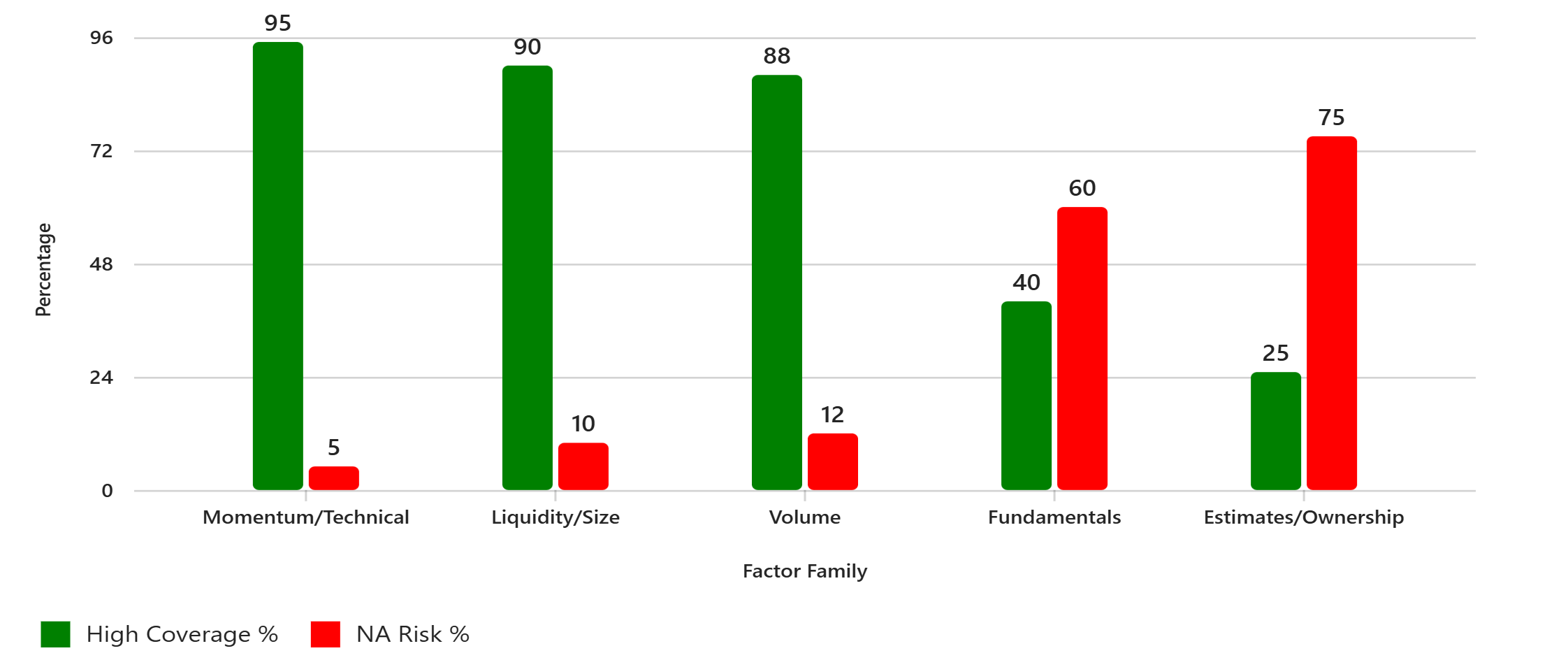
Question to the community:
Does this approach make sense for Canadian universes?
Are there other factor families or syntax tricks you’ve found effective for reducing MAX NA?
Any best practices for mixing technicals with fundamentals post 2012?
Looking forward to your thoughts!