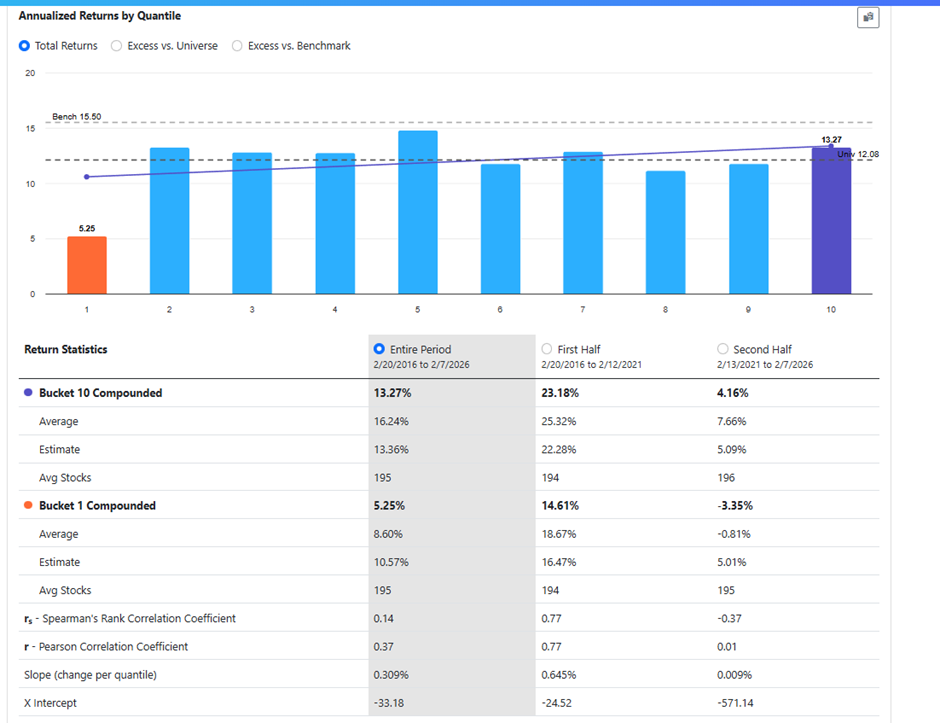
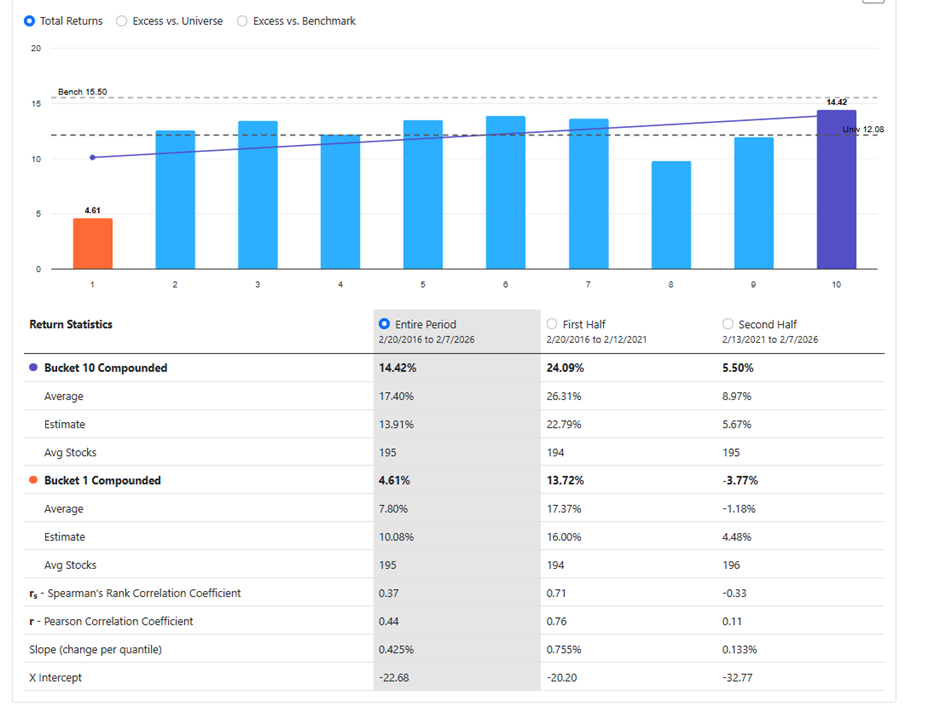
I get different results in my ranking system depending if I neutralize the subsector bias using the rank against using Frank which is not the intended behaviour.
By using FRank inside a ranking node, you prematurely convert an NA (a flag for missing data) into a hard numeric percentile (e.g., 40) before the main ranking engine processes it.
The classical ranking engine then sees the number "40" instead of recognizing missing data, which completely bypasses your global "Percentile NAs Negative" system setting. The engine treats your missing data as a legitimate tie between healthy companies, altering the final tie-breaking math and slightly shifting your bottom quantile boundaries.