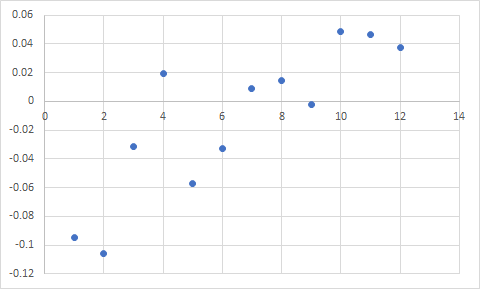
I think the most basic backtest should be to see if factor momentum even exists. To do that–and I’ve done it–you backtest 50 different strategies–some emphasizing value, some growth, some high volatility, some low volatility, some small caps, some large caps, etc.–over the past 22 years. Then you look at the correlation between returns over different periods. So, for example, I looked at the correlation between the returns of my 50 strategies over the nine months following a three-month gap (just to make sure I have new stocks) after 1 year, 2 years, 3 years, 4 years, 5 years, and so on. Here are my results, which reflect the average correlation measured on eight different starting dates. The X axis is the number of years looking back; the Y axis is the correlation with the returns of the nine-month out-of-sample period.
Of course, with correlations this low, there’s a lot of noise in the data. But the trend seems clear enough. You’re more likely to have factors work like they did in the past if you use a 10-year lookback period than a 1-year. If you use a 1-year period you’ll do better with a reversal than a continuation, since the correlation is quite negative. I’ve done this exercise with tons of different types of strategies, with tons of different OOS periods (I normally use 3 years instead of 9 months), over the last five years. The results are very consistent: anything less than eight or ten years has lower correlation.
Now, technically, using a 10-year lookback period is just as much “factor momentum” as a 1-year lookback period, and if so, I use factor momentum myself and strongly believe in it! It’s just the 12-month part that I find alarming.
All this presupposes that I’m understanding what is meant by “factor momentum.” But it might mean something entirely different, in which case all of this is entirely irrelevant. I have looked at all the papers that have been posted on this thread, but am no closer to really understanding what is meant by “factor momentum” than before.
By the way, our screens and simulations now allow you to use ten different ranking systems with the Rating and RatingPos commands. So backtesting a rotation strategy has never been easier. Not to say it couldn’t be even easier than that if we were to develop something along the lines you suggest, but choosing one out of ten ranking systems depending on certain conditions will give you a good sense of whether factor momentum (as I understand it) can work better than sticking with one ranking system. If your choice is purely portfolio-based, I suggest the following workaround: test 50 different portfolios with 50 different ranking systems, download the results into Excel, and choose the one with the best performance over the last X months for the next X months. That shouldn’t be too hard.
We have a ton of development work taking place over the next few months (which I’ll announce shortly). But after that, maybe we can look into rules-based books.
Lastly, our AI feature will be very adaptive and will change factor weights over time. It should be ready sometime this year.