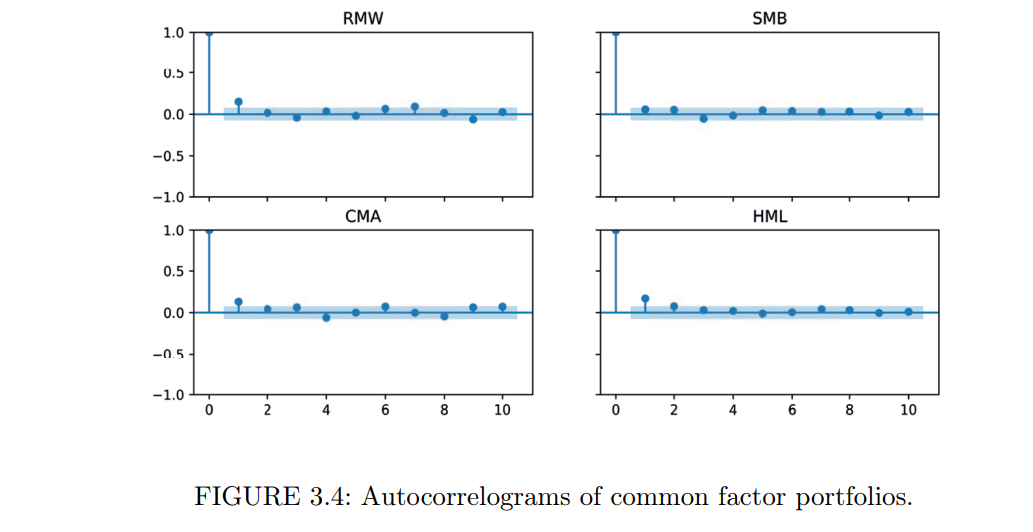
I was checking out the book mentioned here: Machine Learning for Factor Investing by Guillaume Coqueret and Tony Guida, referenced to by Marco here ML integration Update.
Chapter 3.4.1 and 3.4.2 give a short overview of some recent papers on the subject of factor momentum / factor timing, worth checking out. I've taken two short parts out below.