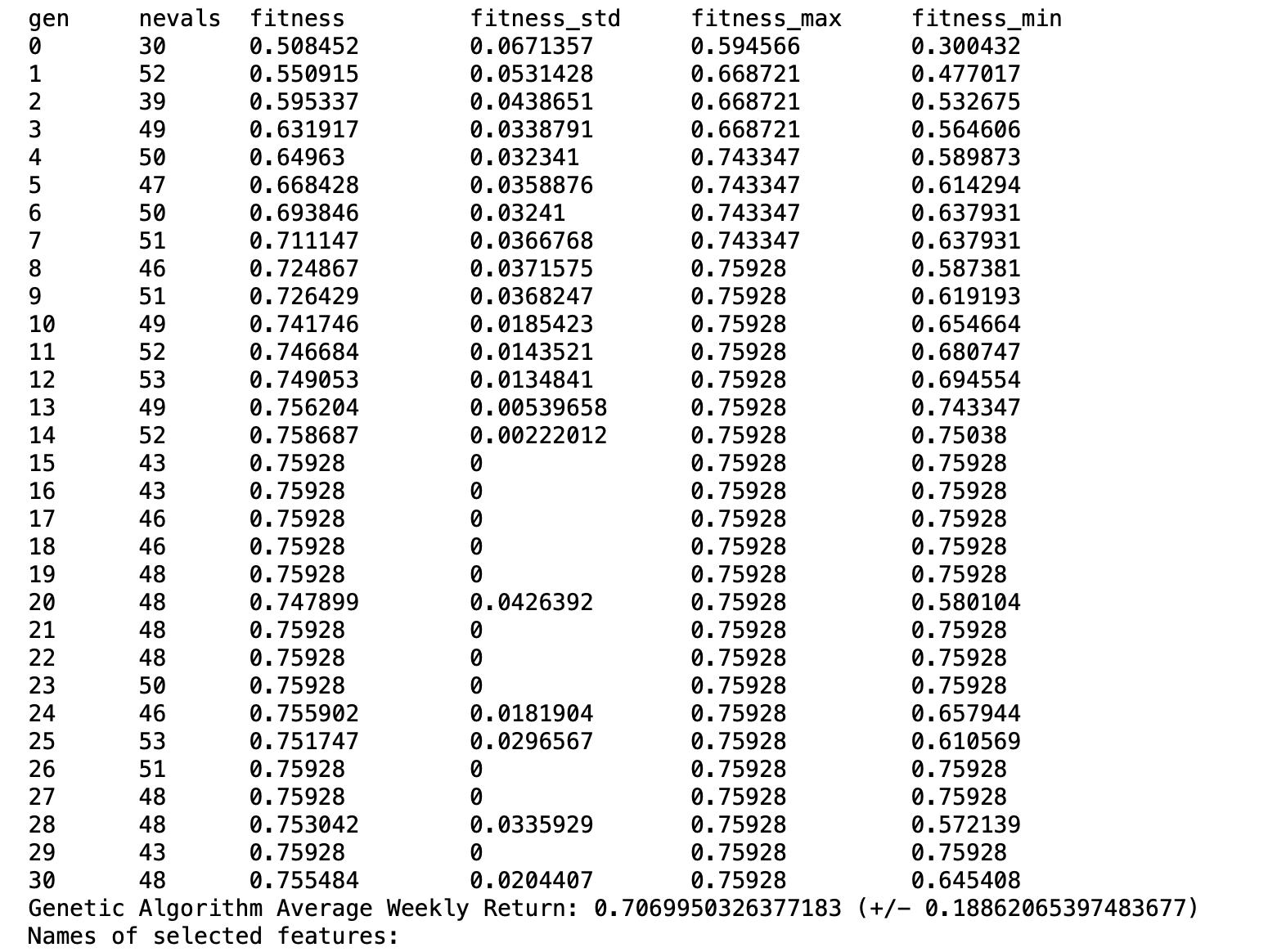
My very first trial of a Genetic Algorithm (GA). Ran some code that also generated some data and compared it to a ridge regression.:
BTW you may need this code (probably in the terminal for Anaconda at least) as GA is not a standard module for Sklearn: pip install sklearn-genetic-opt
import numpy as np
from sklearn.linear_model import ElasticNet
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn_genetic import GAFeatureSelectionCV
from sklearn.preprocessing import StandardScaler
# Generate sample data
X, y = make_regression(n_samples=1000, n_features=20, noise=0.1, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Standardize features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# ElasticNet approach
elasticnet = ElasticNet(alpha=1.0, l1_ratio=0.5, max_iter=1000, random_state=42)
elasticnet.fit(X_train_scaled, y_train)
y_pred_elasticnet = elasticnet.predict(X_test_scaled)
mse_elasticnet = mean_squared_error(y_test, y_pred_elasticnet)
# Genetic Algorithm approach
evolved_estimator = GAFeatureSelectionCV(
estimator=ElasticNet(random_state=42),
cv=5,
scoring="neg_mean_squared_error",
population_size=50,
generations=20,
n_jobs=-1,
verbose=True
)
# Set random state for reproducibility
np.random.seed(42)
evolved_estimator.fit(X_train_scaled, y_train)
y_pred_genetic = evolved_estimator.predict(X_test_scaled)
mse_genetic = mean_squared_error(y_test, y_pred_genetic)
print(f"ElasticNet MSE: {mse_elasticnet}")
print(f"Genetic Algorithm MSE: {mse_genetic}")
print(f"Selected features: {evolved_estimator.support_}")
Interesting. I can see that the scoring is MSE ... computed over the whole sample....
Did you consider to create a custom scorer that select features which maximise sortino/sharpe based on selecting X stocks with highest predicted return for each period... ?
I agree the result would be interesting (important). I already have the code to find "sharpe based on selecting X stocks" as well as the returns (for ML models). I can adapt the code (scorer) for this method.
Question to Claude 3: So, one of 2 things will happen with multiple runs. The results will be stable with the genetic algorithm selecting the same features each time. Or there will be some variance with different features being selected each time.
If it is that latter, model averaging could be used and it may actually be a good thing that reduces variance?
Answer: "This strategy aligns with ensemble methods in machine learning, which often outperform individual models. ...This approach could indeed lead to a more robust and generalizable model, especially in a domain as complex as stock market prediction…."
It is what it is, but I am not sure which to hope for: completely deterministic solutions or some variance in the feature selection that might be utilized for model averaging.
I continue to explore this with a Jupyter notebook running a genetic algorithm as i write this. So far there is some variance but not a lot (with one particular set of features). And I am still not sure which to wish for or what might be useful going forward. For all I know, I might end up adding features to create more variance in the genetic algorithm runs to better utilize the ensemble-method approach.