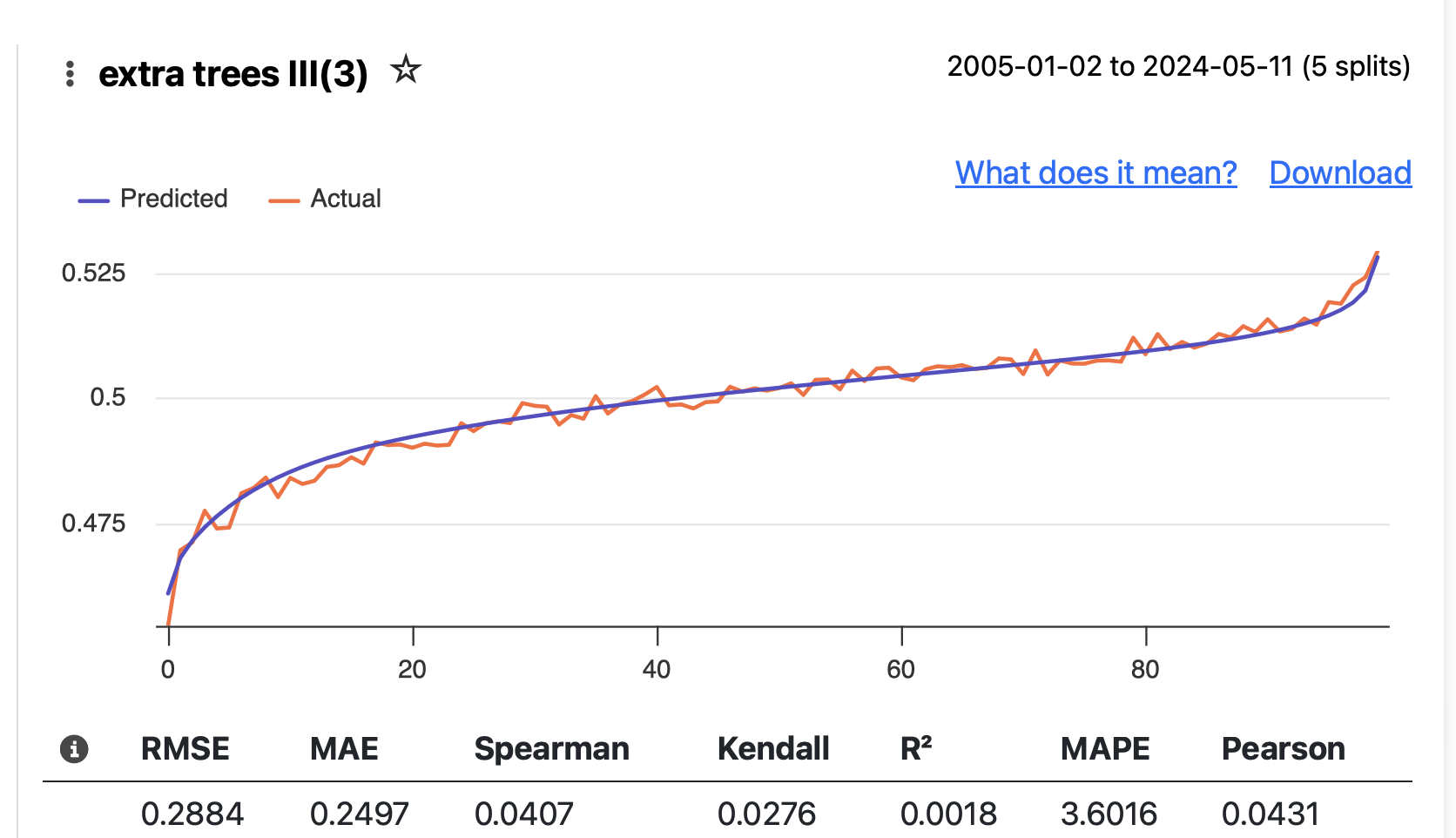
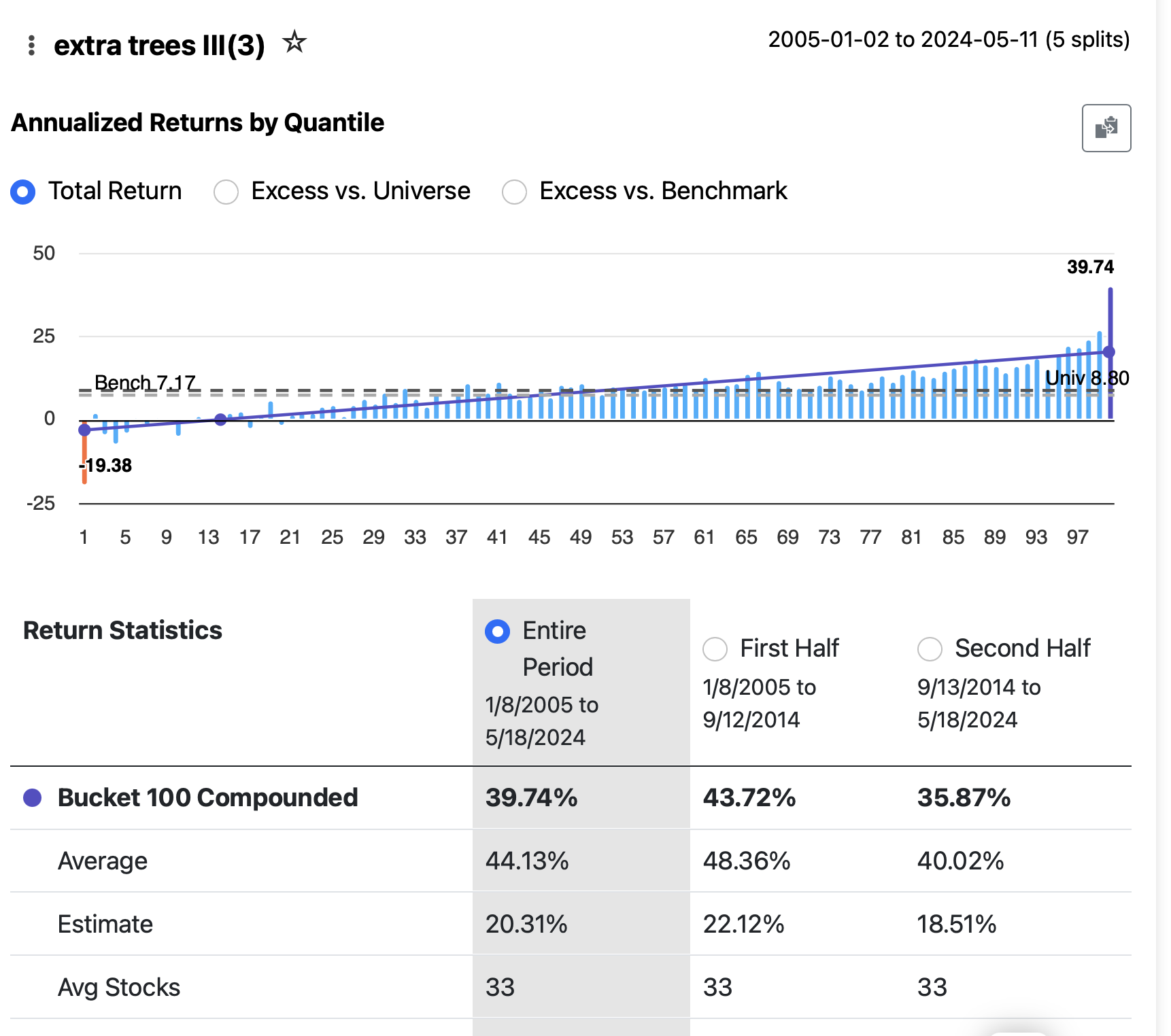
First try I left in Future 3 Month returns like I was used to doing for my offline runs which required me to separate the features and target after downloading.
For this system you select the target and then the features. Better but differet.
Well I managed to fumble the second try, poor results but I discovered I had somehow downloaded SP500 rather than S&P Mid caps. Don’t know how this happened.
3rd try, 20yr data using S&P MidCaps, Time Series CV 8 fold split 2yr hold, 1yr gap and 3 to 17 year training periods.
Model rankings; Random forest 100, Linear ridge 100, extra trees ii 100, xgb ii 40, gam ii 20.
But actual portfolio gains don’t correlate with the ranks. Every single one gave nice excess profits over the 16 years of portfolio validations. This is from 3/2008 including most of the ’08 bear market.
Top 5% of stocks in universe. Picked SPMidCap as I thought it would be a better test than
Extra Trees 19 stks 7.35 above BM
Rand Forest 20 stks 5.5 above
XGboost 20 stks 10.37
LinearRidg 20 stks 7.58
GAM 19 stks 9.58%
Unless I’m missing something, it appears that there is not yet an Ensemble’s Prediction method using the results of selected models built in. A simple majority vote should improve the results.
Aurelien Geron in “Hands On Machine Learning w/ Sciket-Learn” has pointed out that in an noisy environment an ensemble of week learners often give stronger results. RF, ET and XG boost are internally ensemble’s
of trees but Geron points out that “Ensemble methods work best when the predictors are as independent from one another as possible”. “One way is to train them using very different algorithms”. SVM and GAV are very different from decision trees.
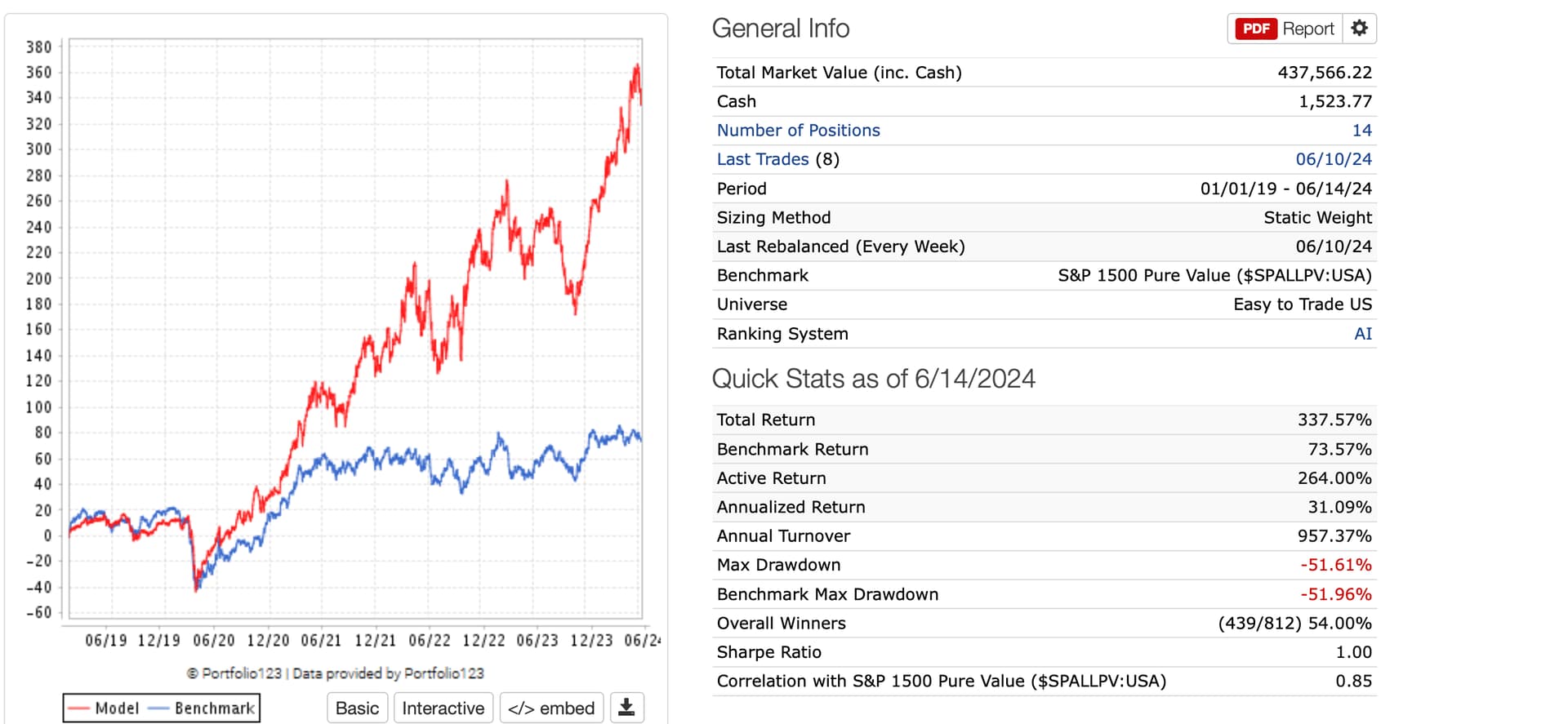
The next big question is. What is the turnover for a portfolio build on these predictions? Would love to do a simulation with a select on prediction, hold till prediction drops below some threshold.
Currently I see you can download all the predictions for each model into excel and build your own voting or even a weighted voting system in excel.
For a Beta ML product this one very nice piece of work. A few minor tweaks and anyone can use it regardless of their ML knowledge.
Biggest initial problems are the of the human interface with the software. How do I enter data, how do I change it after I notice too many missing values or too much noise, how do I select models . . . just the normal things I always run into when I first try a new package.
For the record I’m not an AI or ML professional, I did work in the field almost 30 years ago but my expertise was in designing computers and IC’s for ML not the software. Since then, I have tried to keep with the field by on line courses, a collection of books along with using AI/ML for my personal investment screening and backtest software.