Many top universities and MBA programs use Portfolio123 not only for teaching quantitative finance and portfolio management, but also for academic research, from testing factor models to exploring behavioral and market efficiency theories.
Some of the institutions that subscribe to Portfolio123 include:
- Stanford
- MIT
- Harvard
- Cornell
- Miami University
My Experiment: Testing CAPM
I decided to test one of the very first finance models I learned back in school, the Capital Asset Pricing Model (CAPM) and see how it performs when tested with real data..
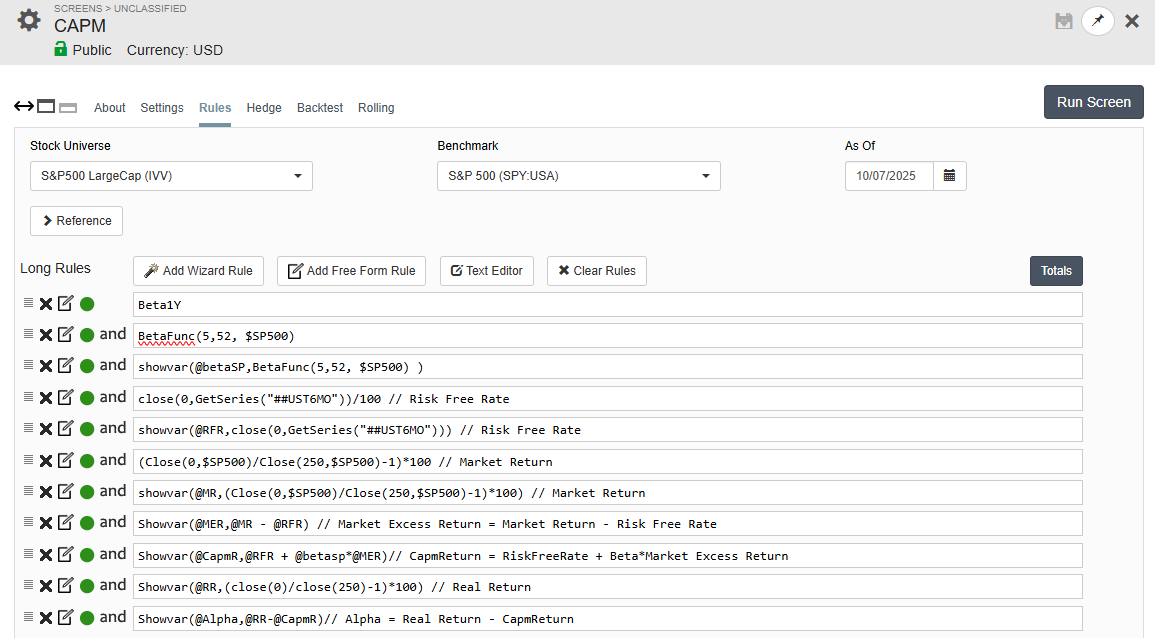
The screenshot below shows the CAPM screen, which calculates every component of the Capital Asset Pricing Model step by step. I have made the screen public so anyone can explore it
CAPM formula:
Expected Return = Risk-Free Rate + Beta × (Market Return – Risk-Free Rate)
In the screen’s variable format:
@CapmR = @RFR + @betaSP × (@MR – @RFR)
Here’s what each part of the screen does:
-
@betaSP – Calculates each stock’s beta versus the S&P 500 (SPY)
-
@RFR – Fetches the 6-month Treasury bill yield from
GetSeries("UST6MO") -
@MR – Measures the S&P 500’s 1-year price return
-
@MER – Computes the Market Excess Return = Market Return – Risk-Free Rate
-
@CapmR – Calculates the CAPM-predicted return = Risk-Free Rate + Beta × Market Excess Return
-
@RR – Actual 1-year stock return
-
@Alpha – Difference between actual and predicted return = Real Return – CAPM Return
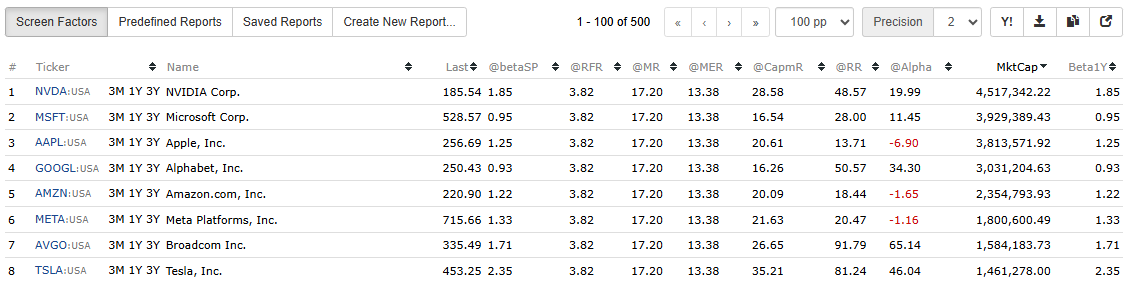
The function ShowVar(@name, expression) makes the screen interactive. It both stores each calculation in a variable and displays it as a column, allowing you to view (Screen Factors), compare, and export every CAPM component directly from the results table.
Visualizing the Results
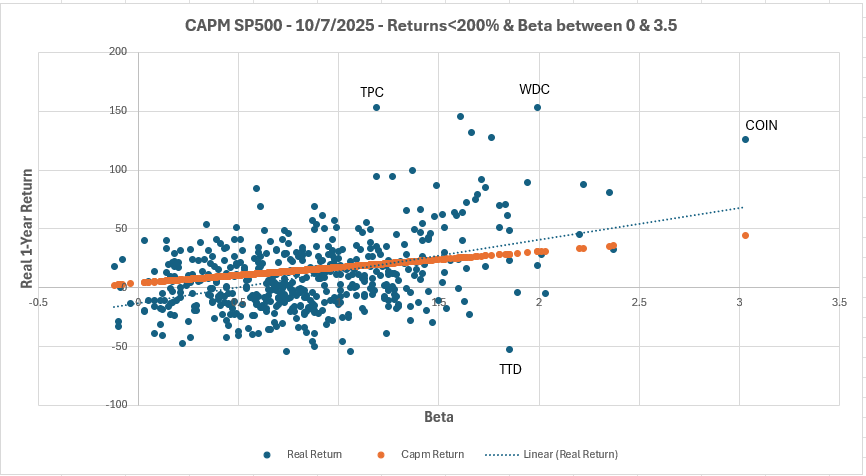
By running the screen and exporting the results to excel or google sheets, you can plot Beta vs. Actual Return to visualize how real-world performance compares to the theoretical CAPM line and see firsthand that the relationship is weak in practice.
Comparing CAPM-Predicted vs. Realized Returns for S&P 500 Stocks (as of Oct 7, 2025)
This chart shows how each stock’s actual 1-year return (blue dots) compares to its CAPM-expected return (orange).
If CAPM held perfectly, all points would lie on the orange line, but in reality, returns scatter widely, showing that beta explains little of actual performance.
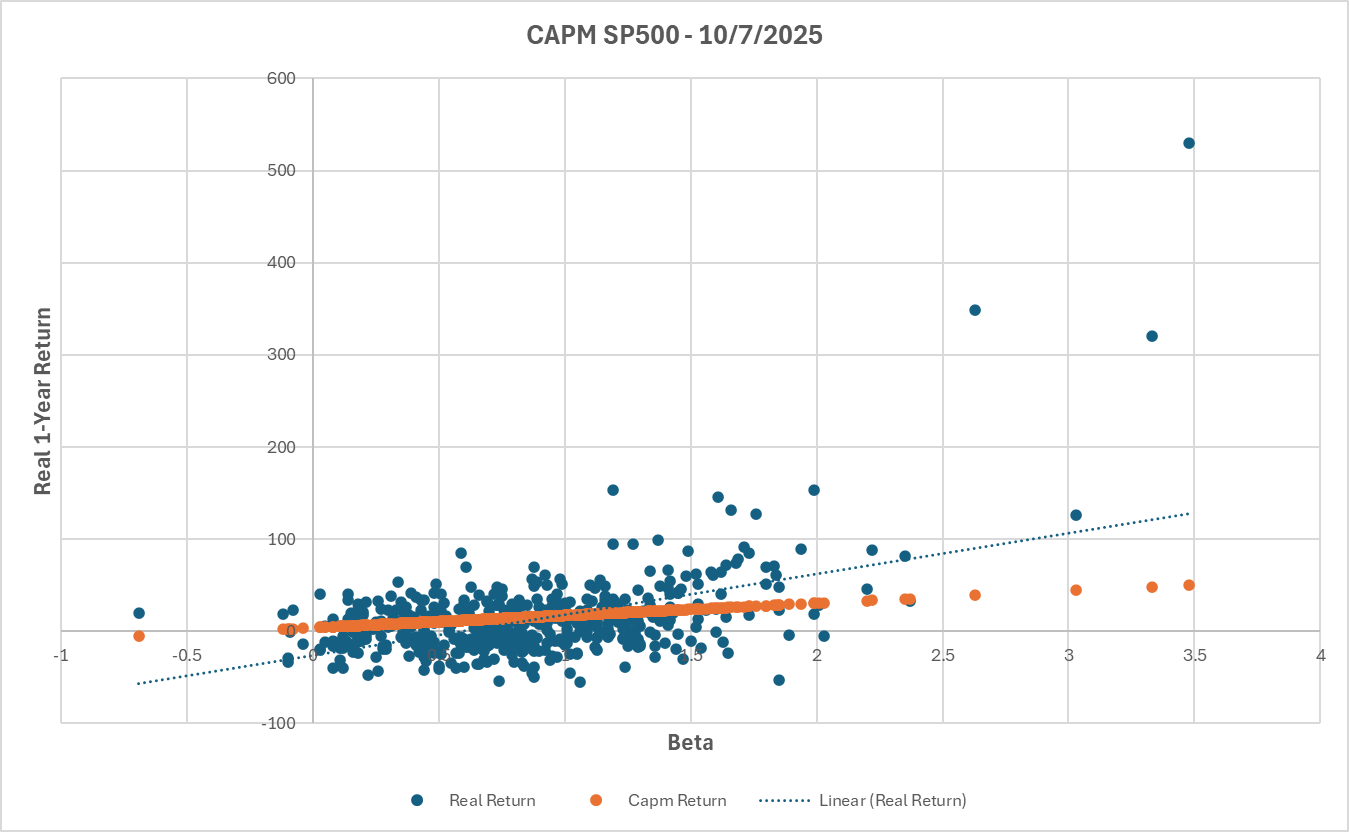
The CAPM model predicts a clean linear link between beta and expected return, but real data tells a different story. Using the screener, you can break down each component of the model and test it with live market data, turning textbook theory into real quantitative insight.
The dot at around 530% return and 3.48 beta represents Robinhood (HOOD), one of several clear examples where actual performance diverges dramatically from what CAPM would predict.
What’s Next?
For students, researchers, or professors exploring quantitative finance, the next step is to extend this test beyond CAPM. Try adding Fama–French 3- or 5-factor models to capture size, value, and profitability effects, or run statistical regressions to measure how much of return variation each model explains (R², t-stats, alpha significance). Portfolio123 gives you the flexibility to replicate academic studies and see which theories still hold up in modern markets.
Join the Discussion
I love to hear from the broader community of academics, quants, and finance enthusiasts. What other financial theories have you tested with Portfolio123. Market efficiency, risk premia, idiosyncratic risk, investor sentiment, or adaptive markets? Share your insights, experiments, or ideas for exploring the next generation of investment theory through data-driven testing.