This is what I am trying to do with AI models myself. Better picks at the top. If one wanted better bottom picks I think the inverse should work too
5 Likes
Eurika! I spent many hours trying to find a way to put more weight on the highest ranks than the lower but came up short. You have made my day!
“An ElasticNet model with graduated sample weighting on the top 20% ranked data is designed to prioritize accuracy on high-impact observations, often used to improve out-of-sample (OOS) prediction in financial or high-dimensional data scenarios. By increasing the weights for top-performing samples (e.g., top 20% by rank), the model forces the L1/L2 penalties to focus on fitting those instances better.
Implementation Details
· Sample Weighting: Sample weights are applied to the fit method. For top-ranked data, these weights are typically increased linearly or exponentially to ensure the model prioritizes them.
· Graduated Approach: Instead of a binary "top 20% vs others," a graduated approach assigns a higher weight to the top 5%, a slightly lower weight to the next 15%, and base weights (1.0) to the rest.
· Implementation (Scikit-Learn/Python):
python
from sklearn.linear_model import ElasticNet
import numpy as np
# Example: Top 20% weighted 5x, others 1x
# Assuming 'y_pred' is ranked and we want top 20% of 'y'
weights = np.ones(len(y))
top_20_idx = y.argsort()[-int(0.2*len(y)):]
weights[top_20_idx] = 5.0 # Graduated weight
model = ElasticNet(alpha=0.1, l1_ratio=0.5)
model.fit(X, y, sample_weight=weights)
6 Likes
Tried to add an analysis of turnover contribution of a final model, I think it will add great value to understand what in a ranking system/simulation is contributing to turnover.
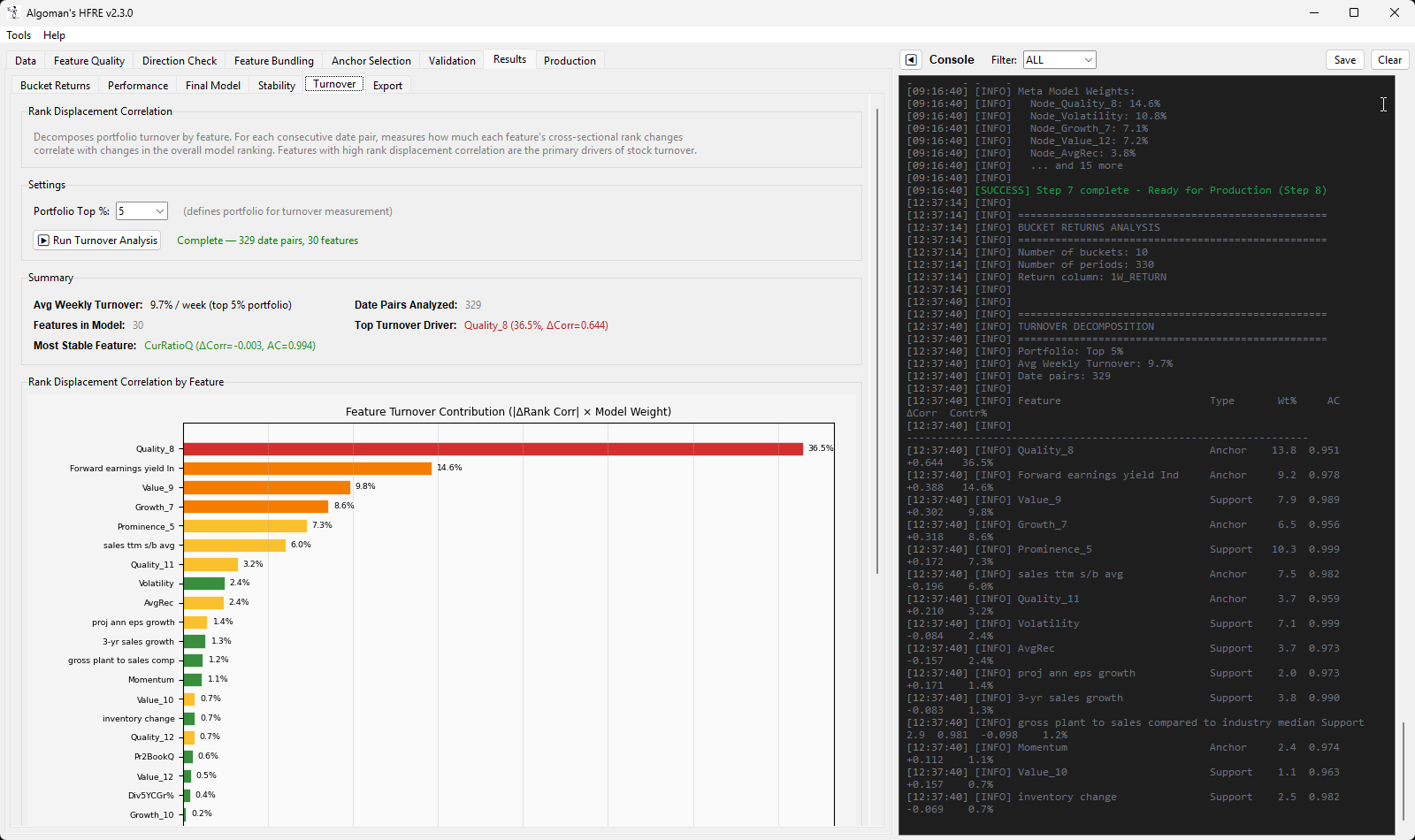
Doing some final touchup of the HFRE app now before I make it public, if not I will keep adding functionalities forever. Will post the "final" Beta app in a new thread, I hope it will be apricated, ended up spending too many hours on this.
2 Likes
This is great! Can’t wait to try it. Will you put the code on github? (even private) - I would not mind contributing.
@AlgoMan great work!
The turnover contribution analysis is a great addition, it really helps pinpoint what’s actually driving (often expensive) turnover in a ranking system/sim.
Thanks for putting in the hours and sharing this with the community. I’m honestly having a hard time keeping up with the pace of improvements, but it’s very appreciated.
Looking forward to the “final” beta thread. ![]()
Yes, I had to redo the analysis, makes more sense now.
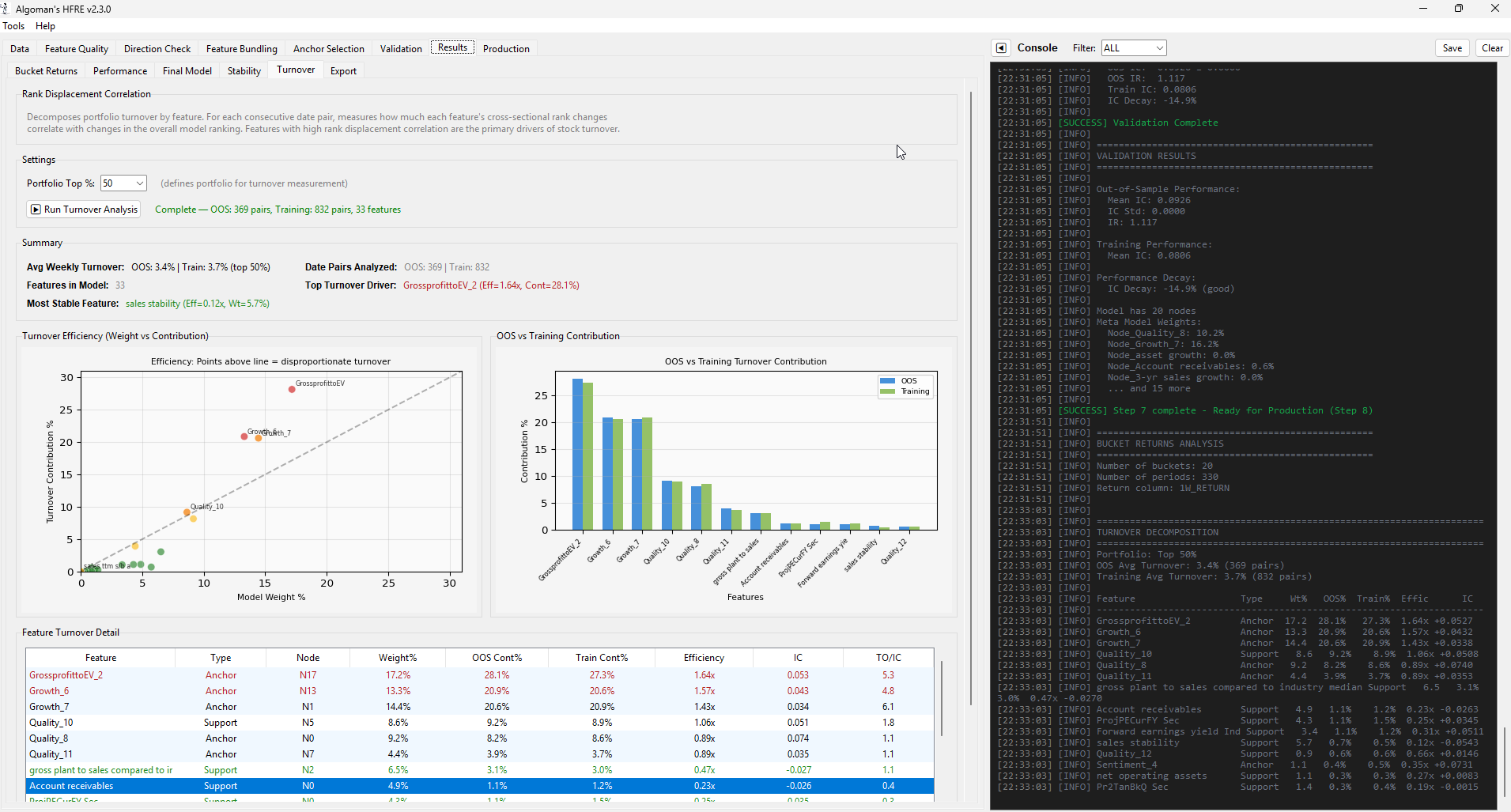
I added an "Autocorrelation" limit in the Anchor selection too, stops high turnover features to become anchors (when using auto selection), might actually been one of the best improvements I done. Lowered the turnover by 50% in the final models. Limiting turnover is otherwise one of the hardest problems to tackle when building AI models.
But now this programming session is done for the evening, got a 7-month that will keep me awake for the rest of the night ![]()
3 Likes
Another kudo for the outstanding and logical methodology your approach to feature selection / engineering. I spent a considerable amount of time last year selecting features trying out different feature selection tools and ensembles of linear and tree results. Truthfully your approach is as through as some of the better textbook or Kaggle examples. Like sraby above I too would like access to the code and would not mind contributing.
3 Likes