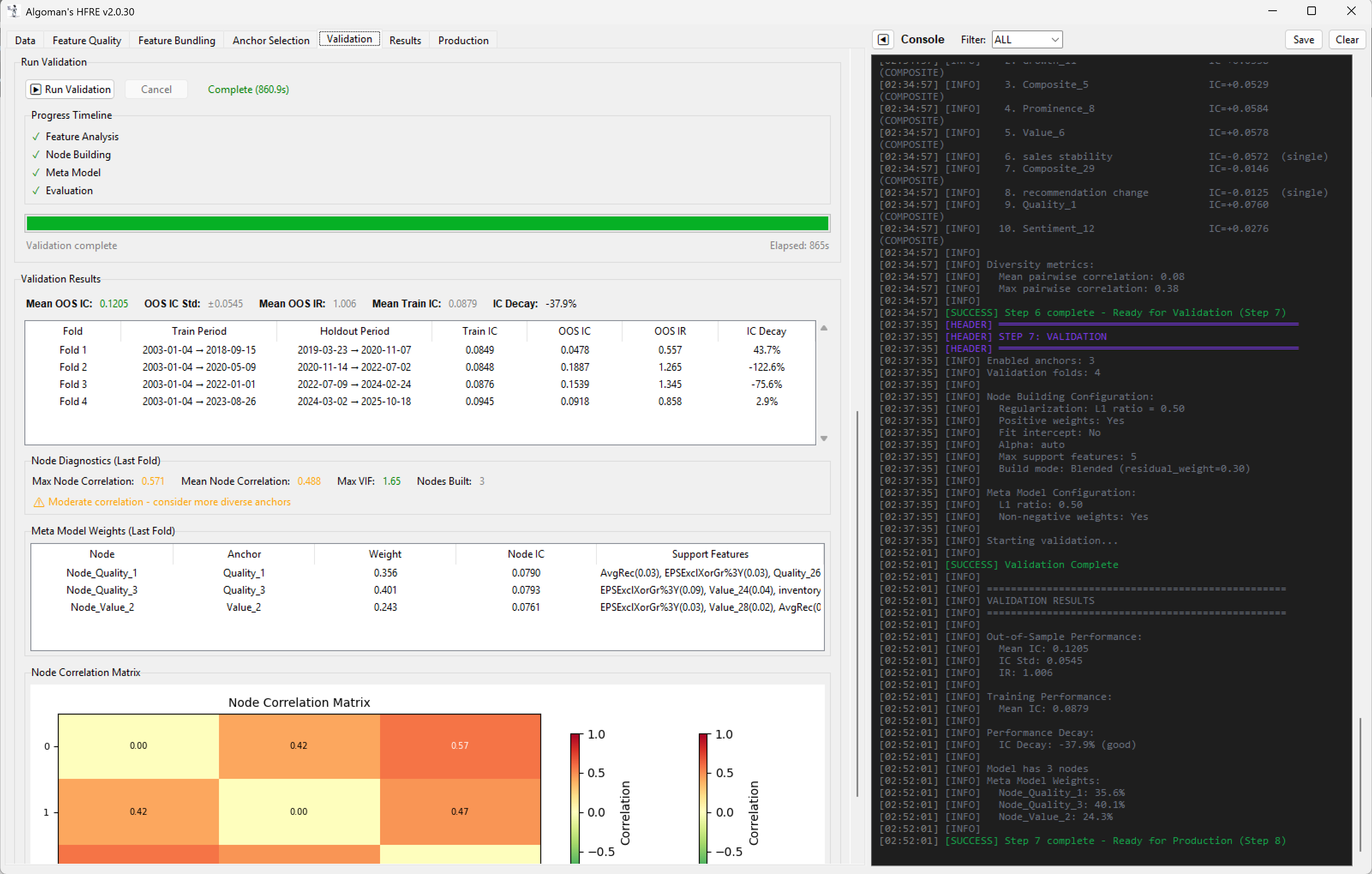
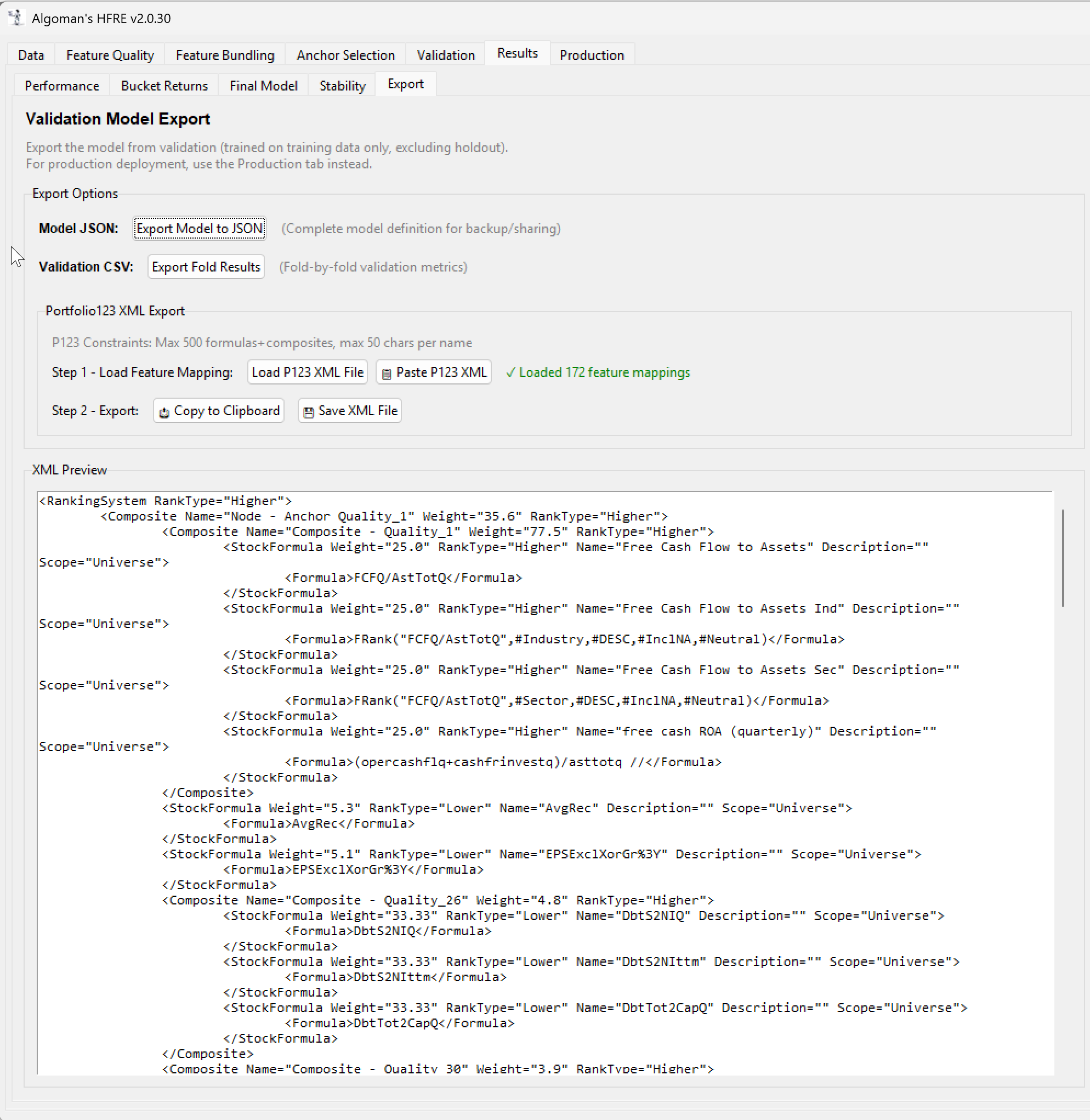
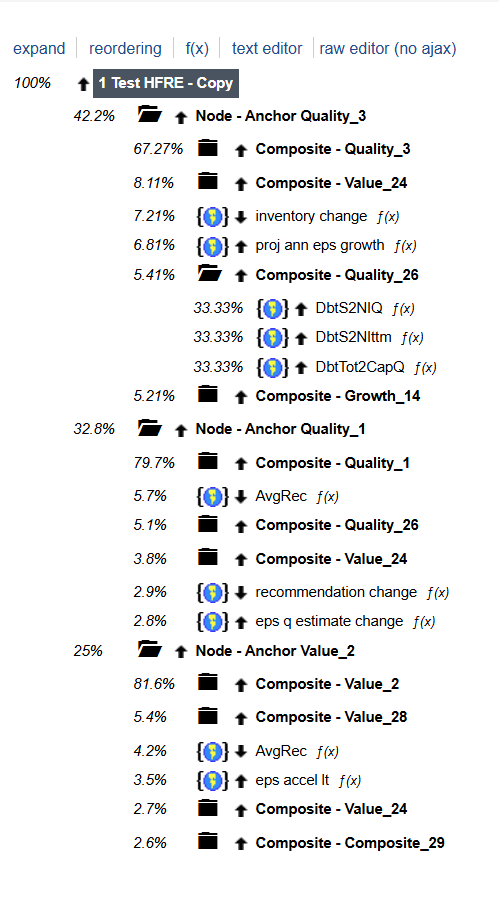
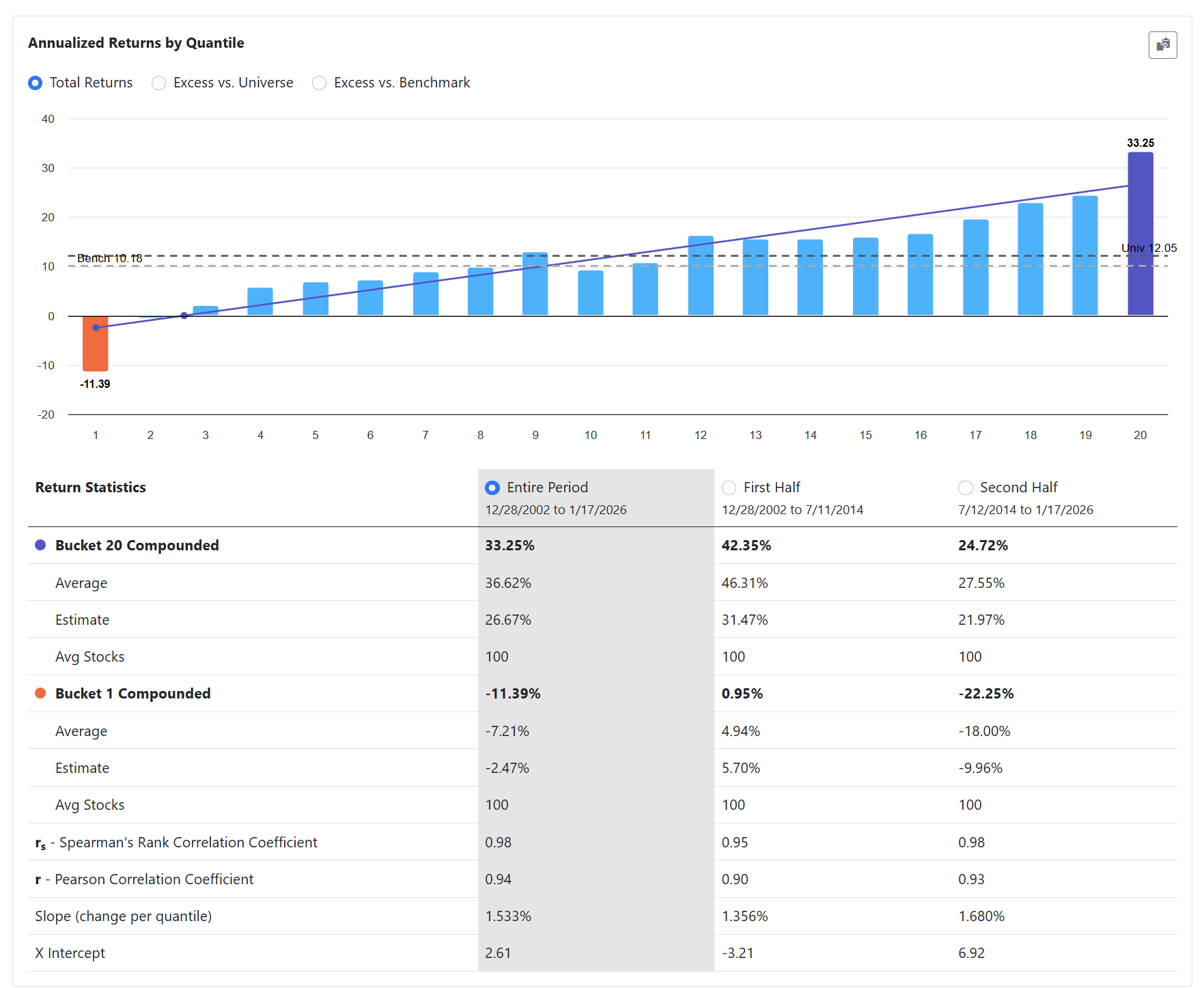
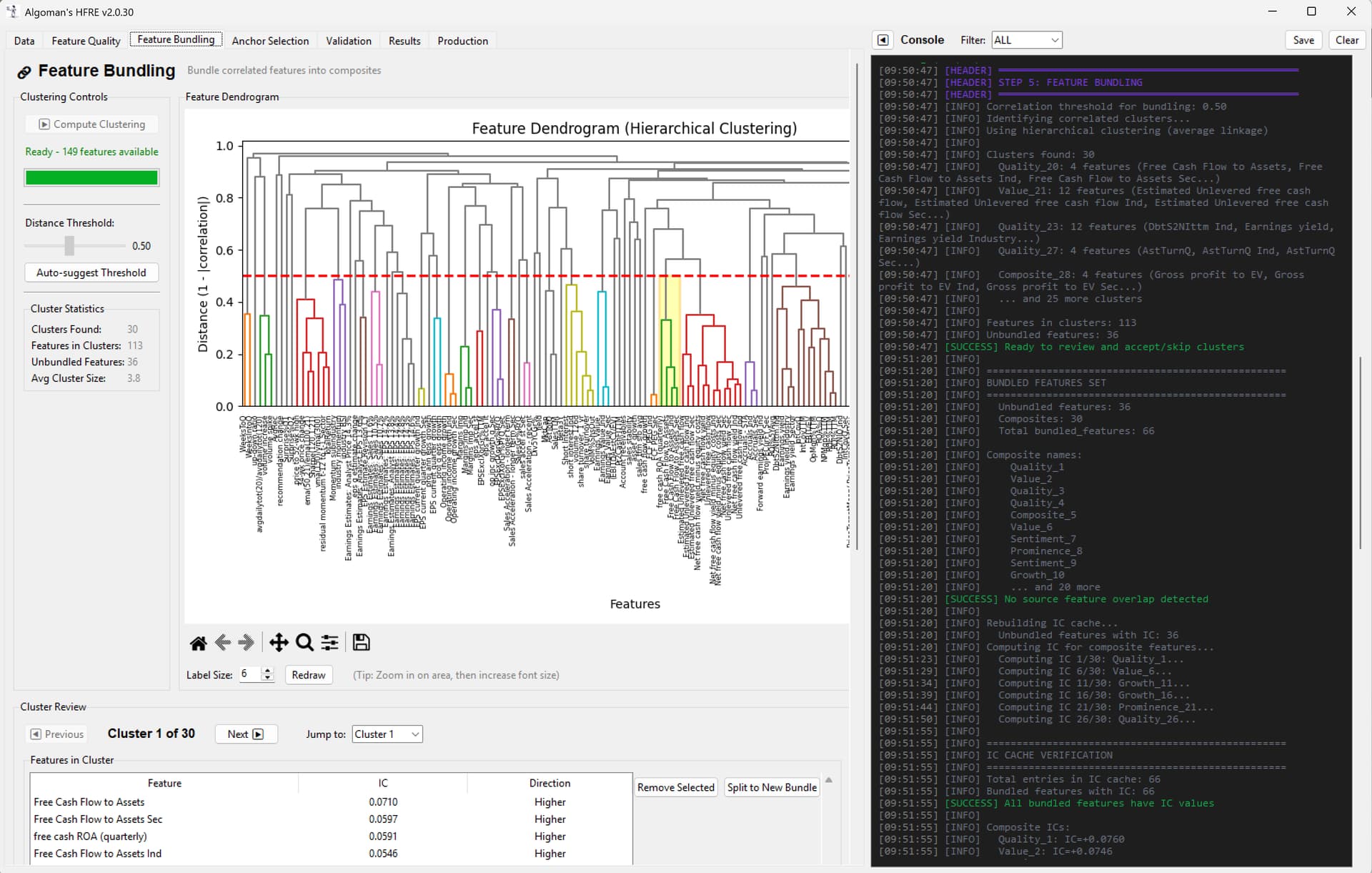
I’ve been thinking about a concept for a Linear ML ranking architecture, and I’m sure many of that many of you have experimented with similar ideas in different forms. I’d love to get your feedback on my concept idea.
In my experience, standard Linear ML ranking systems often underperform expectations. My traditional, manually-crafted ranking systems usually perform just as well—if not better—while offering significantly more control. I believe the weakness of current ML tools lies in two areas:
-
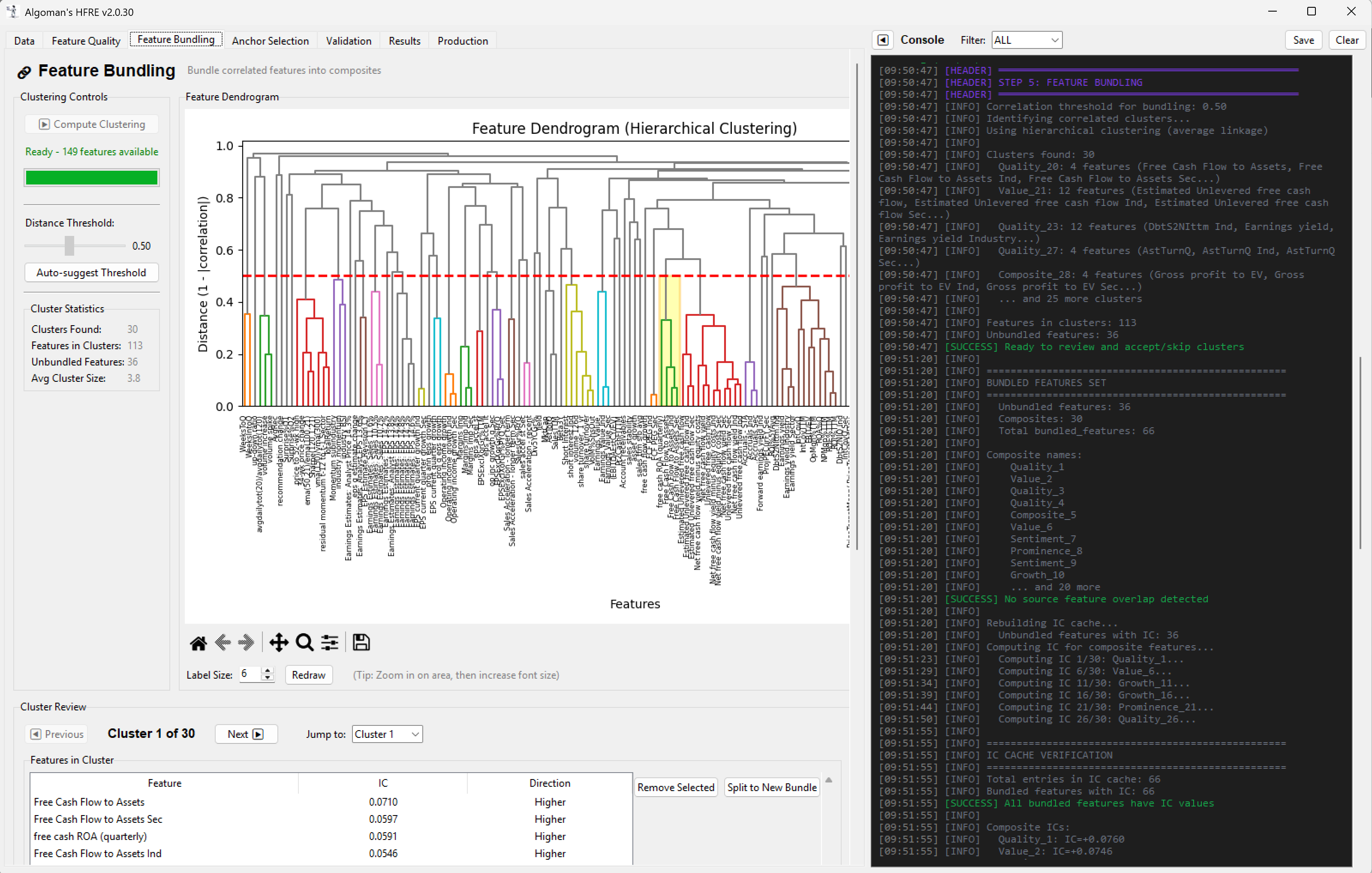
Lack of Structure: We lose the ability to build "blocks" using Composite Nodes, which are for many the backbone of a robust traditional system.
-
Factor Over-Concentration: Without constraints, an AI model often develops an extreme tilt toward a single factor, leading to high volatility or regime-dependency.
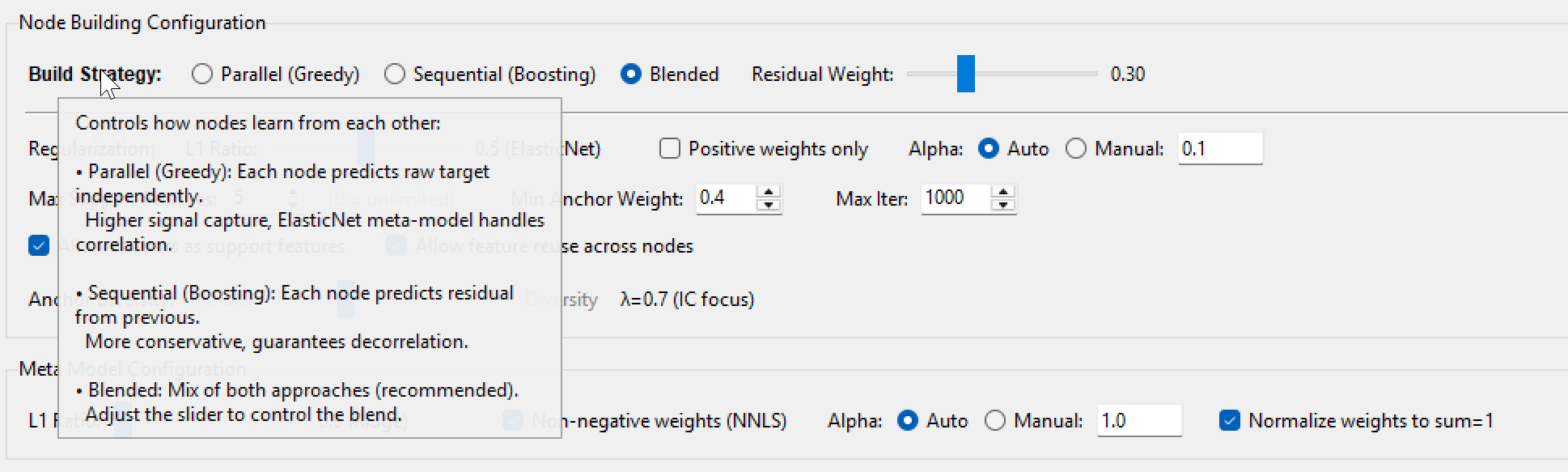
My plan is to build a two-step Linear ML system that bridges the gap between machine learning and traditional "expert-system" design. Instead of one giant model, I am building a hierarchy of "Micro-Strategy Nodes."
The simplified workflow will be something like the following:
-
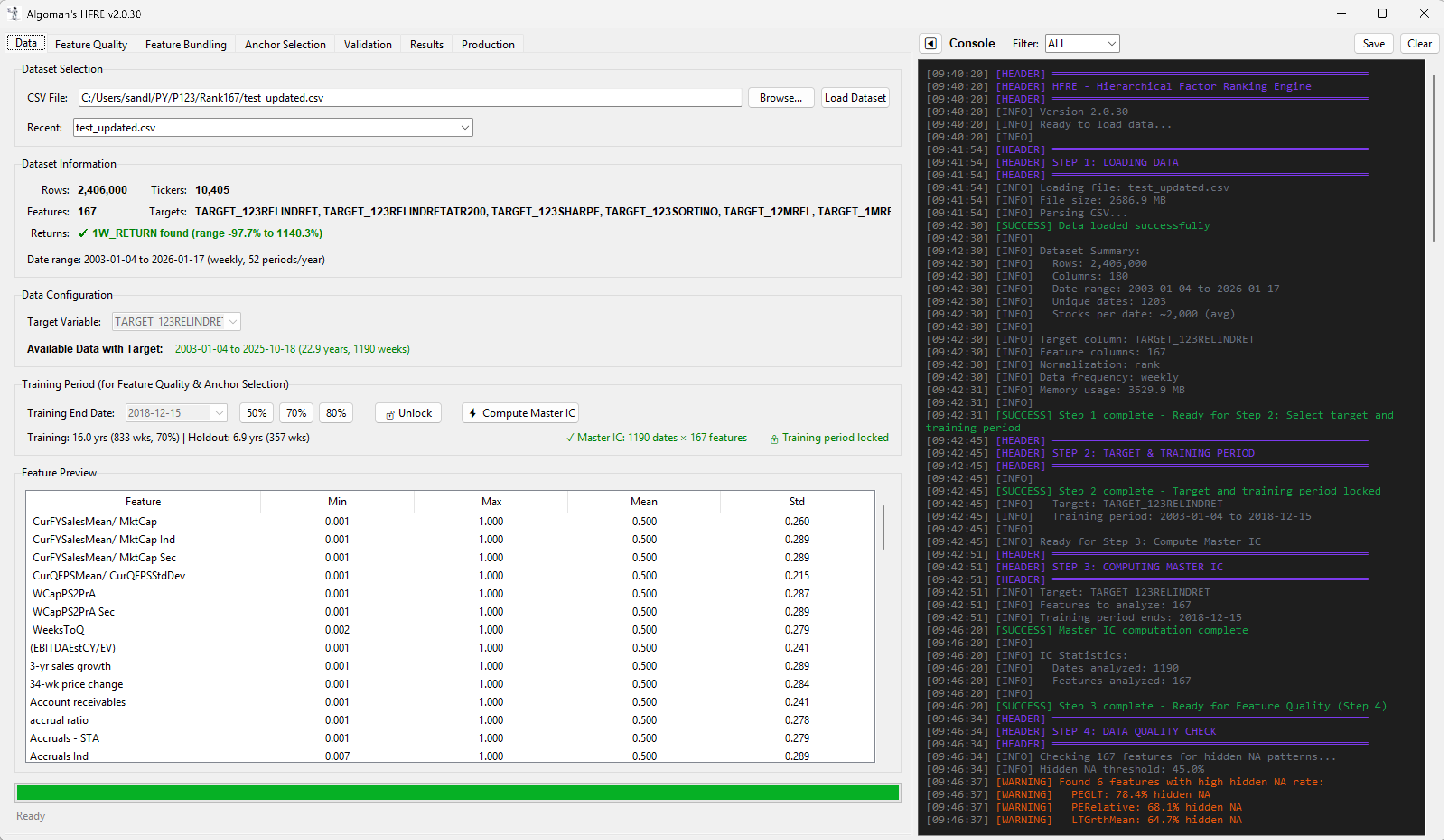
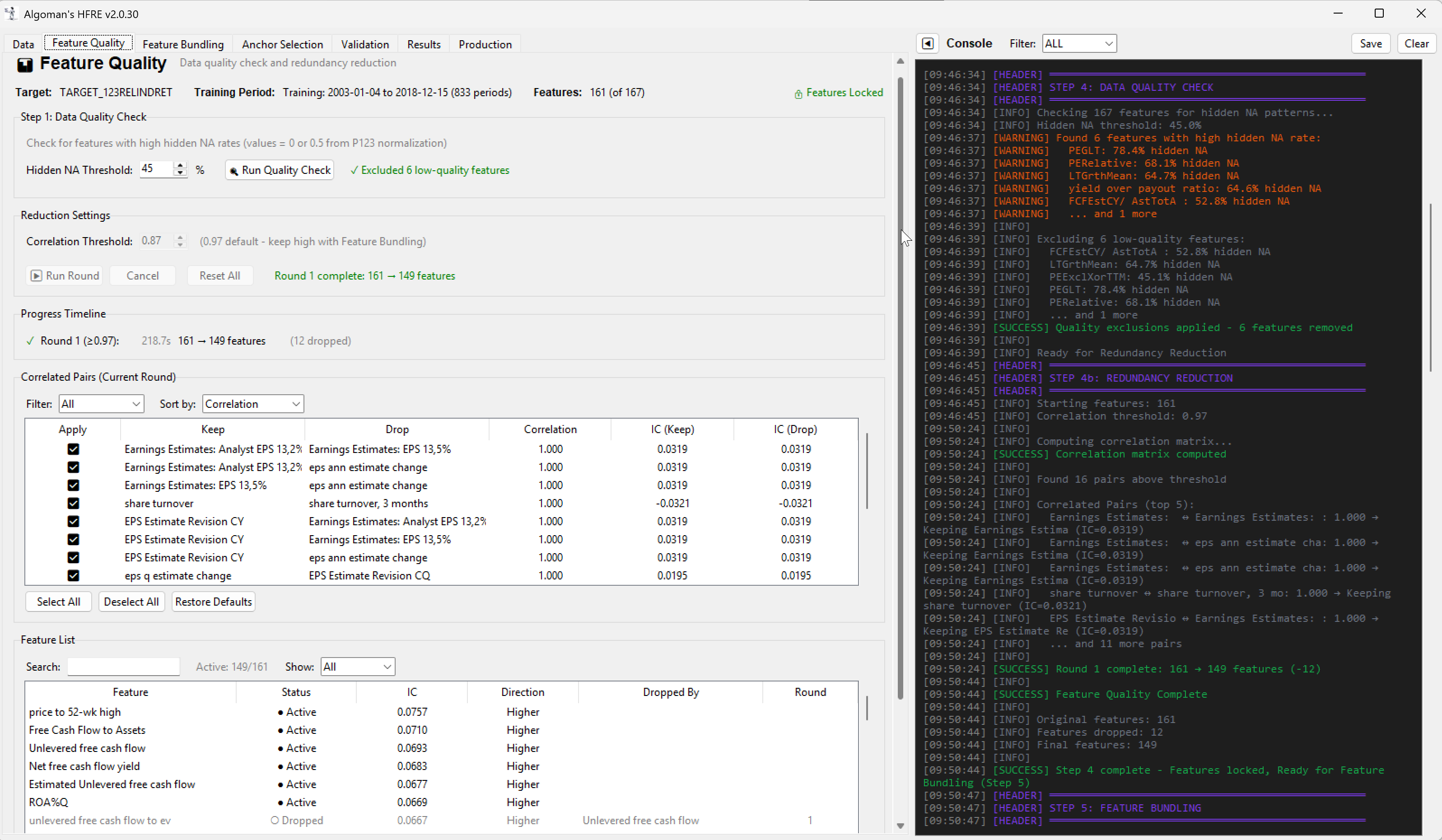
Download pre-ranked factors and target data from Portfolio123.
-
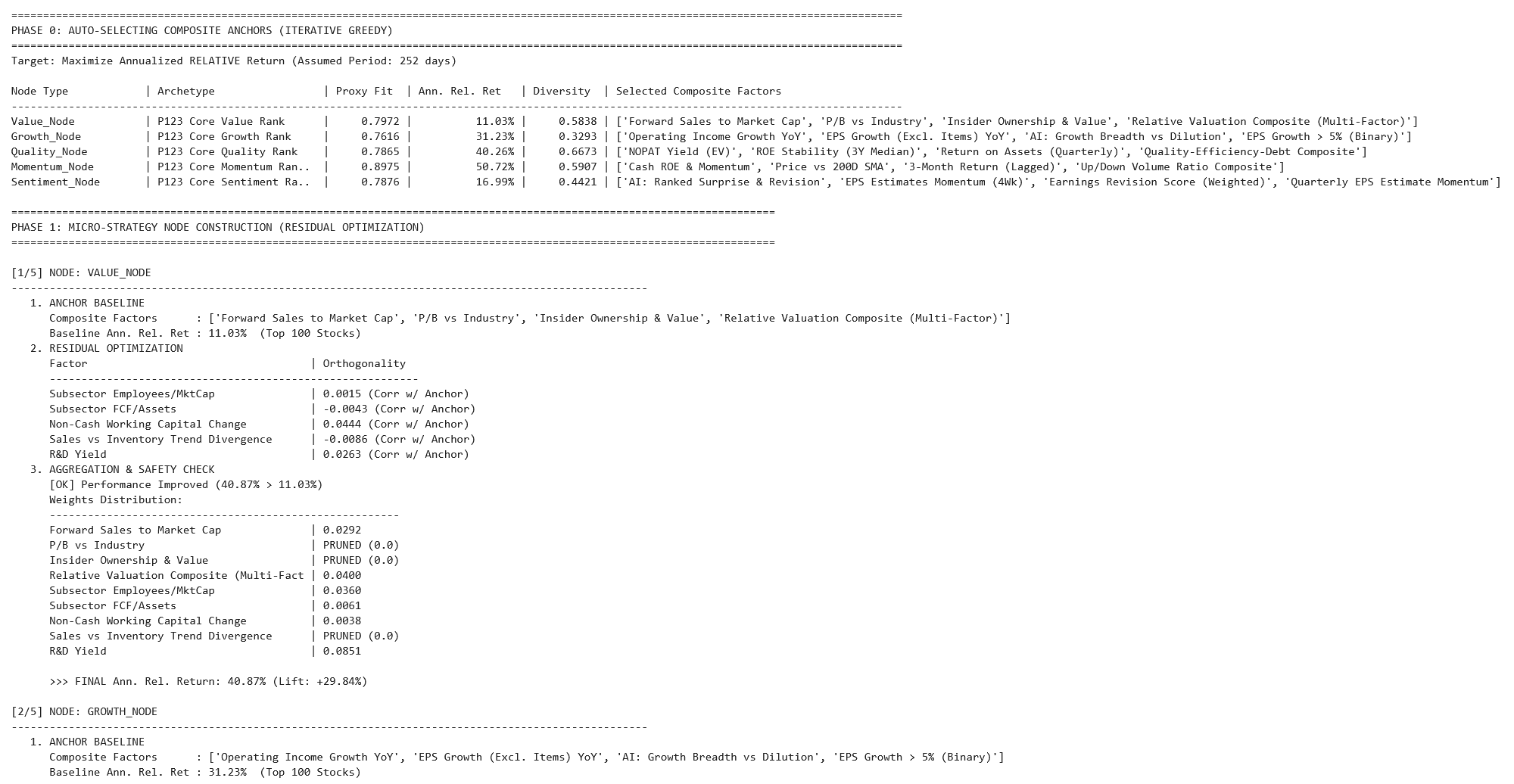
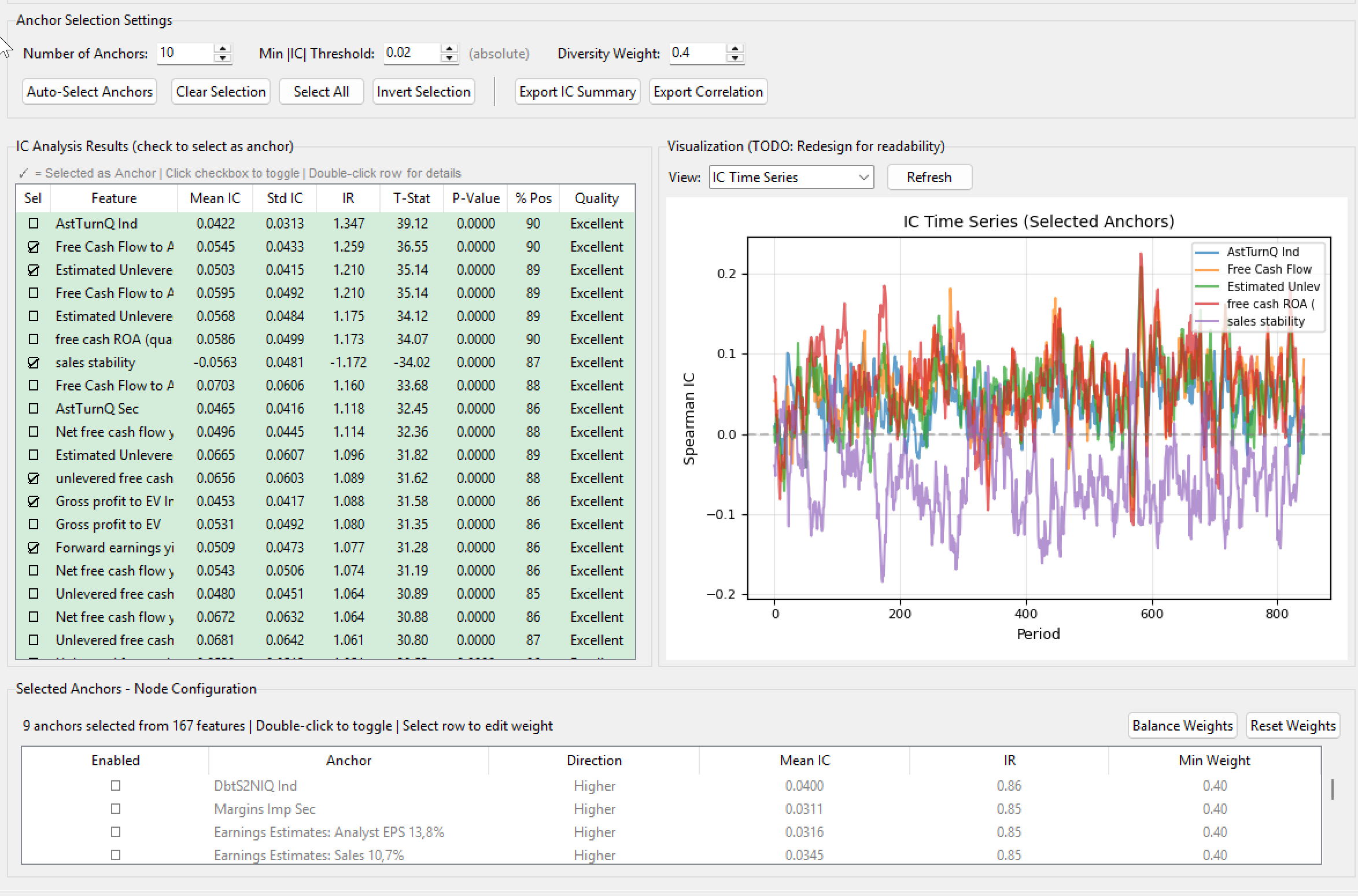
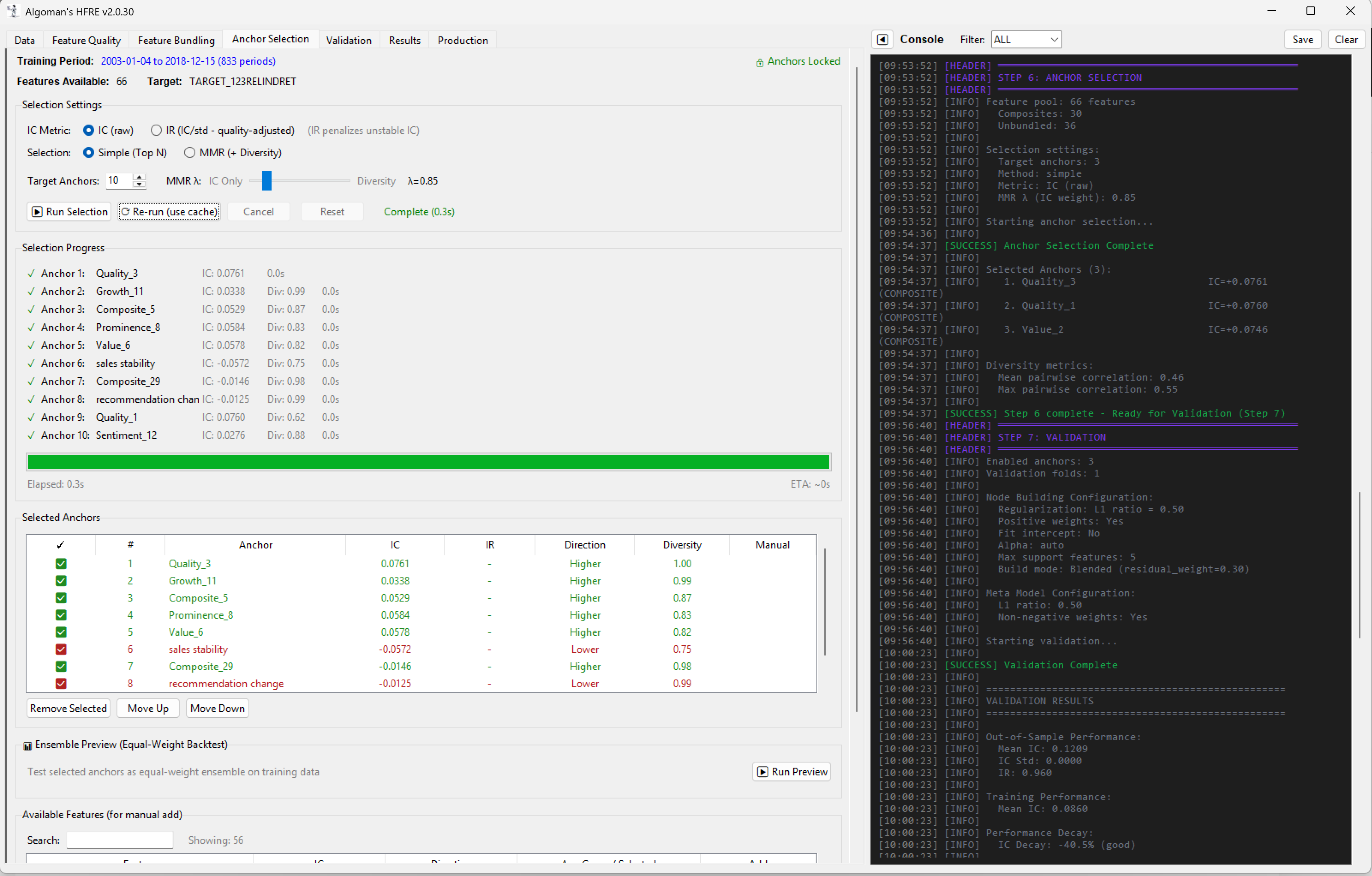
Define a set of "Node Anchors." These are your core "Generals"—the statistically strong factors like specific Momentum, Value, or Growth metrics.
-
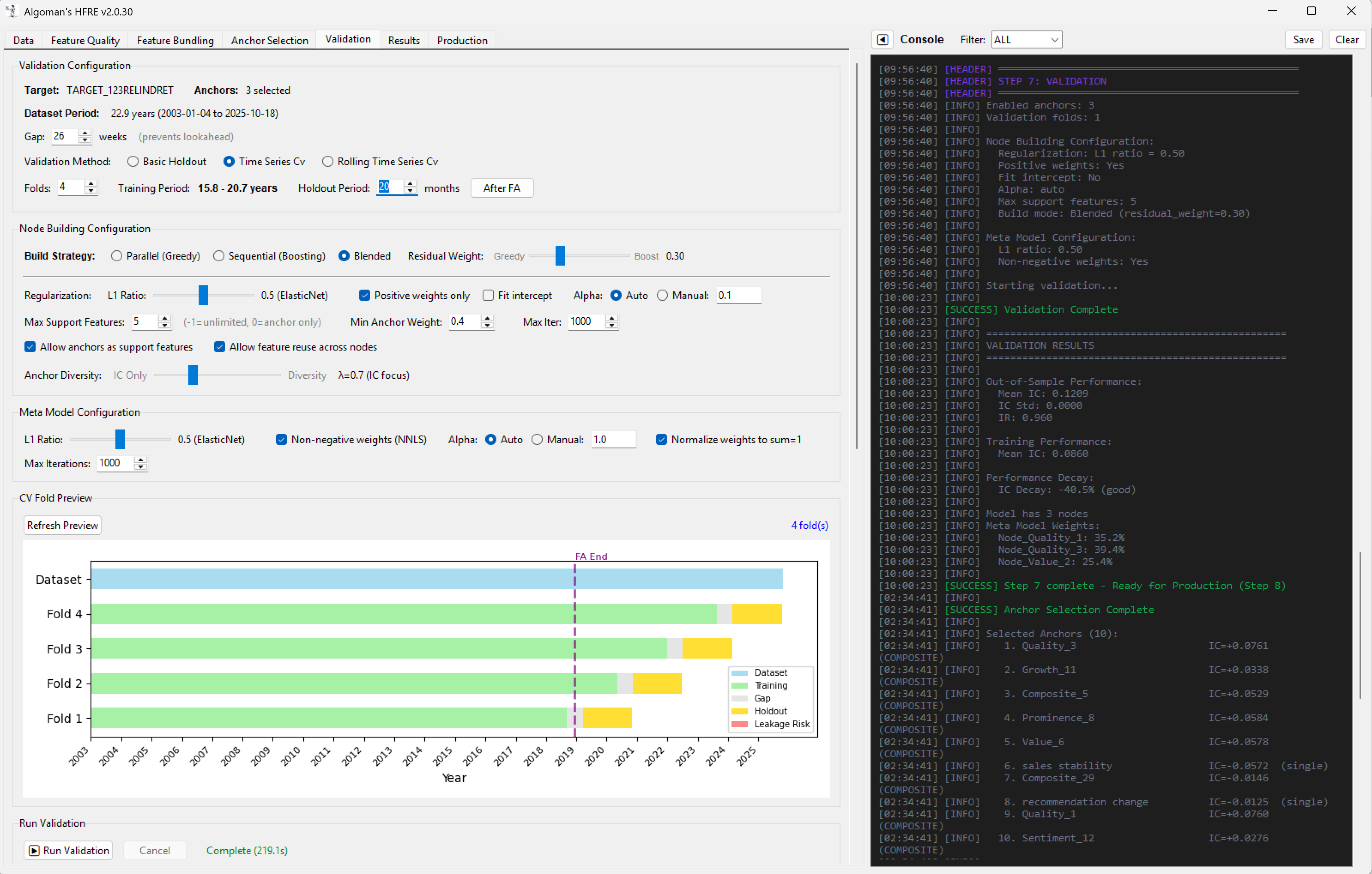
Run a small, constrained Linear ML model for each node. The "Anchor" is prioritized with a pre-set weight, while the model selects a limited number of supporting factors to maximize the node's return (or whatever your target is set to).
- Example: A "Sales Growth" anchor node might be paired with "P/S Ratio" and "Operating Margin" to ensure the growth is both high-quality and reasonably priced.
-
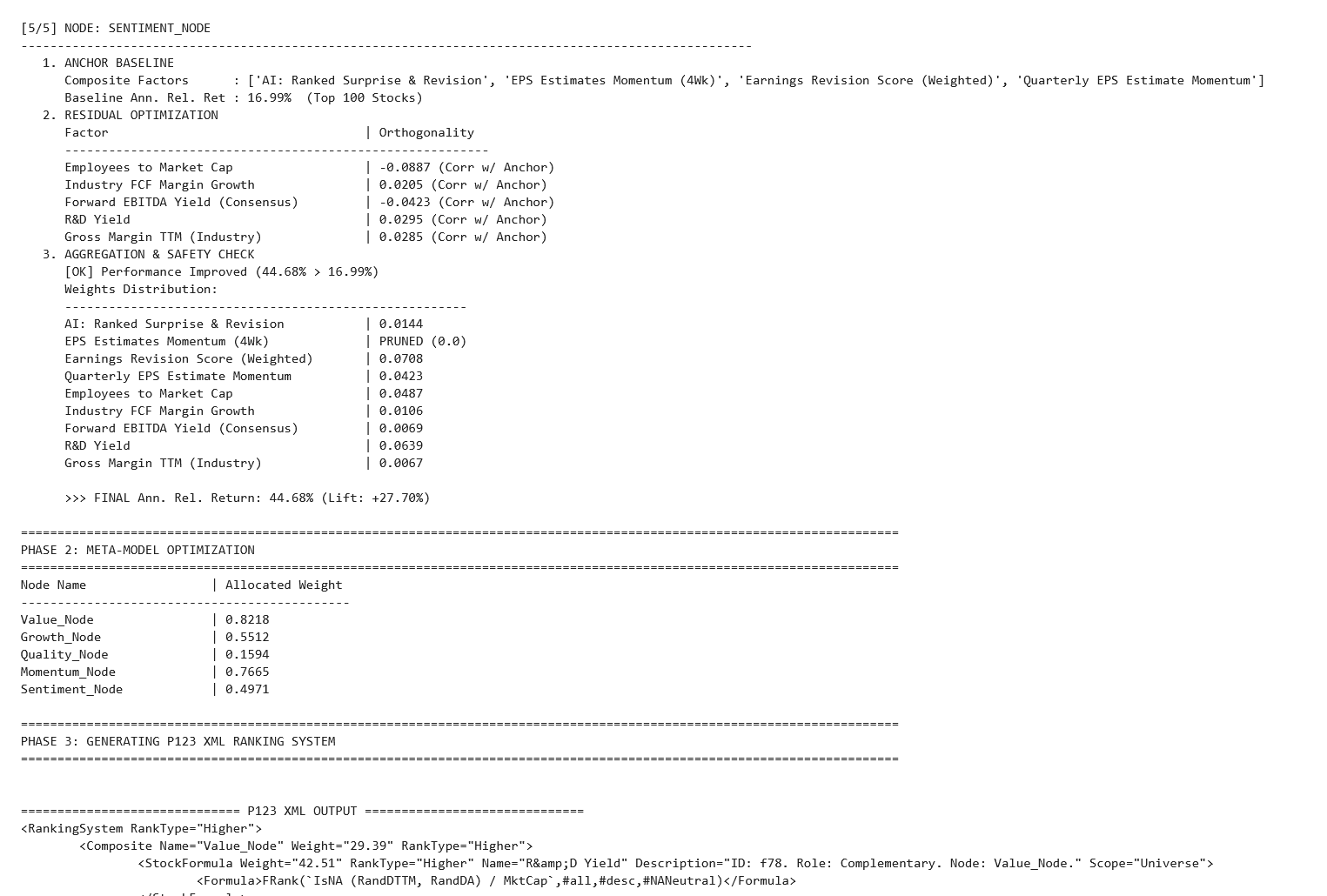
Finally, run a meta-Linear ML (like ElasticNet) on the output of all nodes to determine the final system weights.
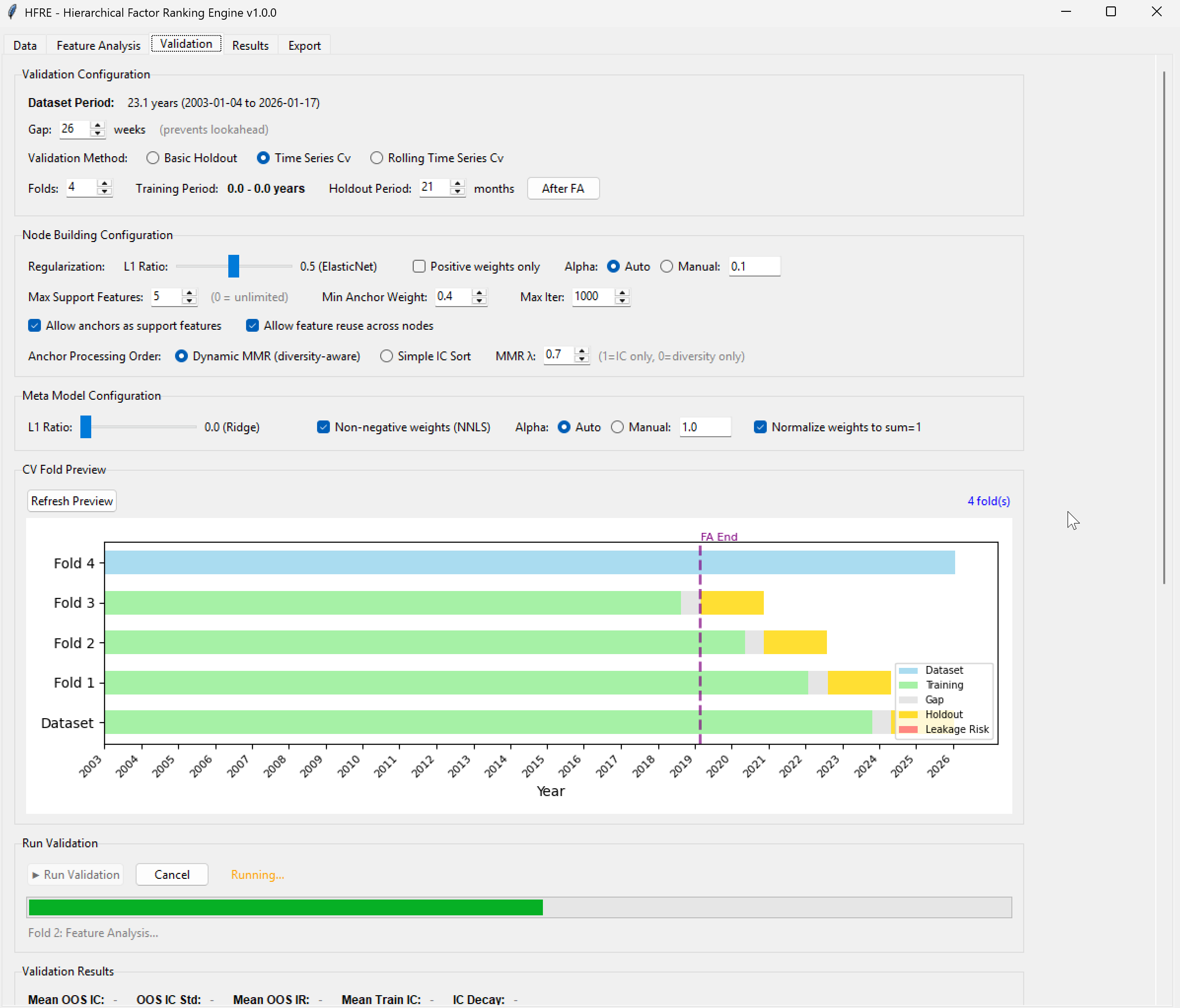
The beauty of this hierarchical approach is that the resulting model is fully transparent. Because both layers are linear, the entire tree can be "transpiled" directly into a traditional Portfolio123 Ranking System via XML. This allows for final backtesting, stress-testing, and manual "sanity-check" tweaks within the P123 environment we all know and trust.
Has anyone had similar ideas? I would love to get some inspiration from other methods to add dimensions and control of linear ML ranking systems before I dig my self to deep in to this concept.