Dear all,
I'd like to take this opportunity to express my gratitude to everyone in the p123 crew for the exceptional service they provide, and to all the experienced and knowledgeable members who generously share their expertise. Your dedication is truly commendable, and I'm certain that I speak for many who may not comment frequently but are avid learners, striving to keep pace with the brilliant minds in this forum such as Yuval, Andreas, Kurtis, and many others. We are immensely grateful for all the invaluable insights and teachings.
Now, onto a query that may seem trivial, but I'm eager to glean insights from our experienced members.
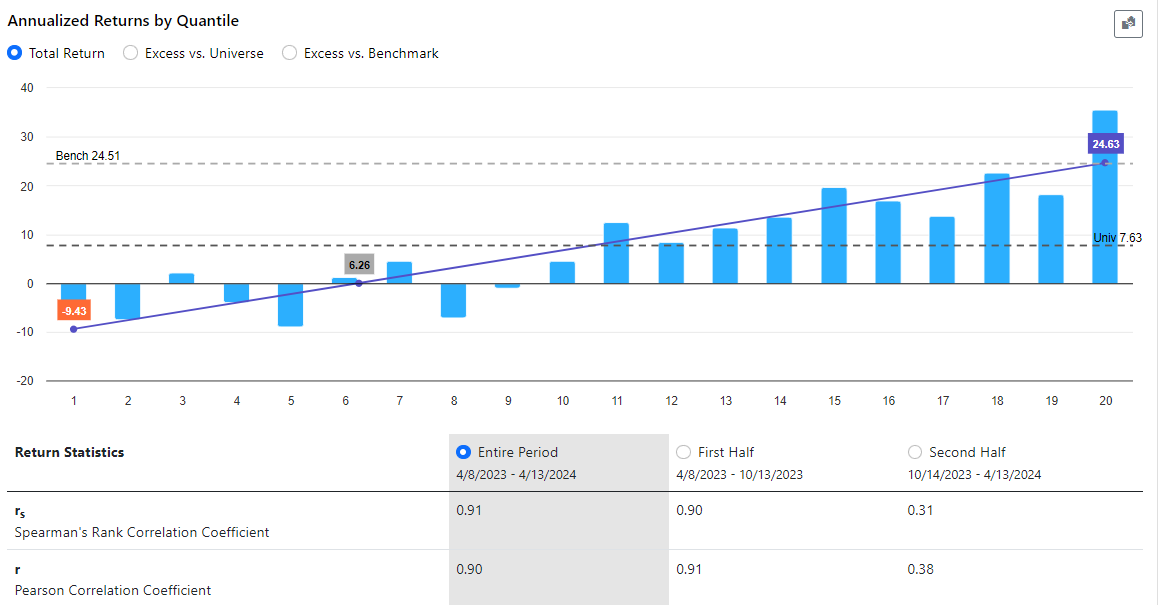
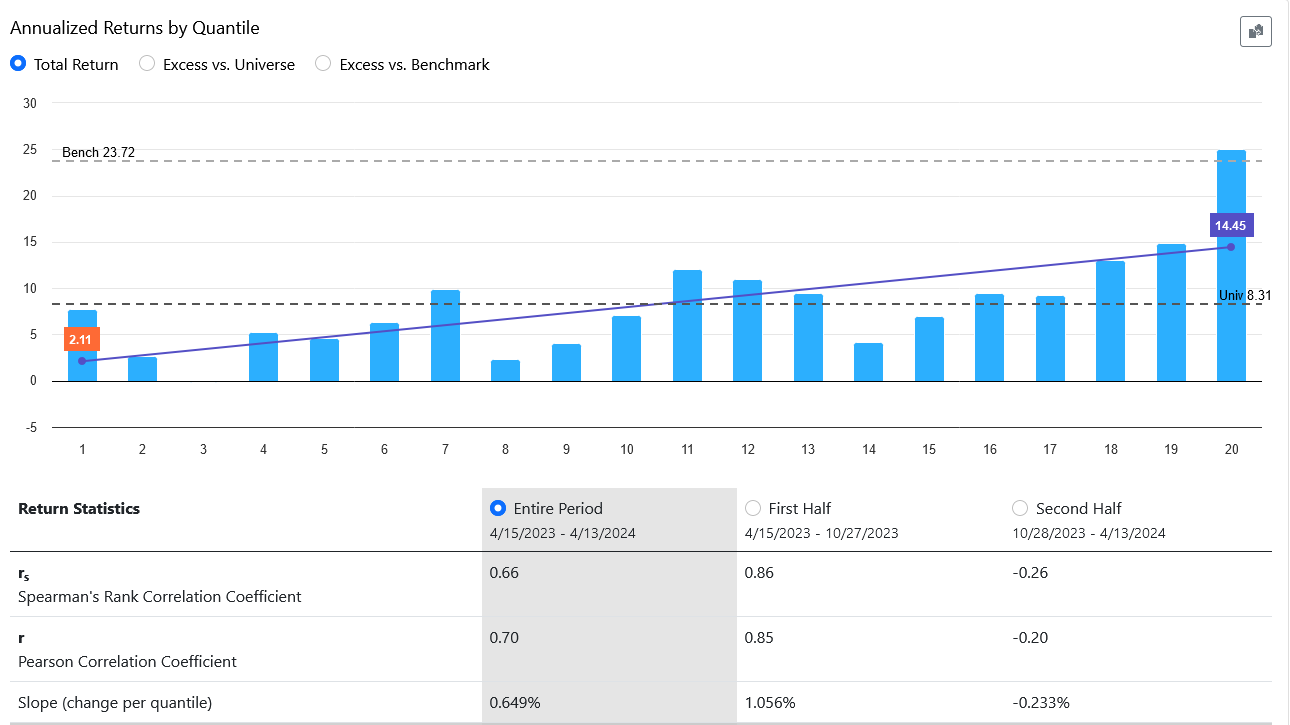
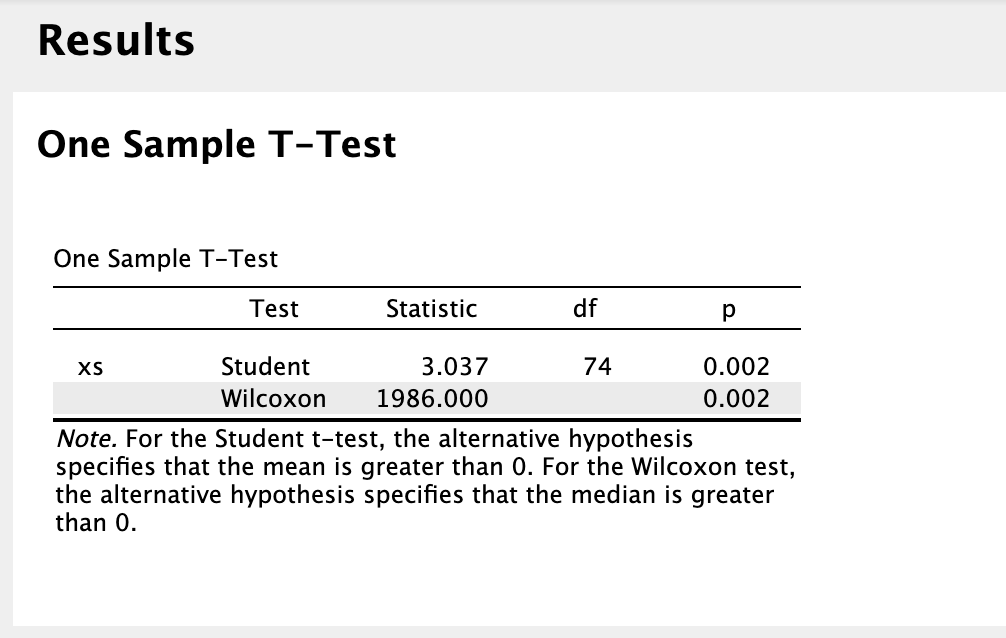
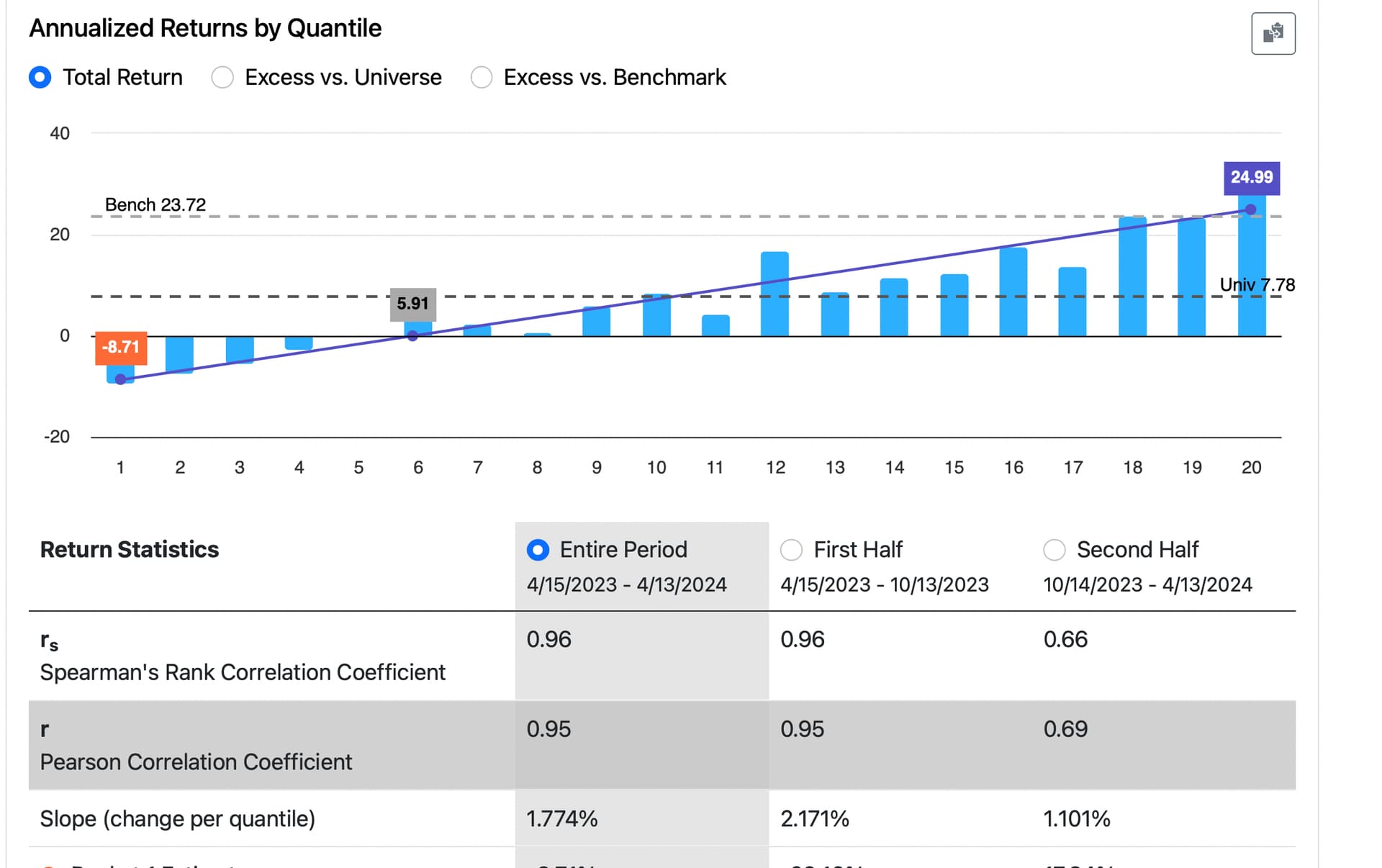
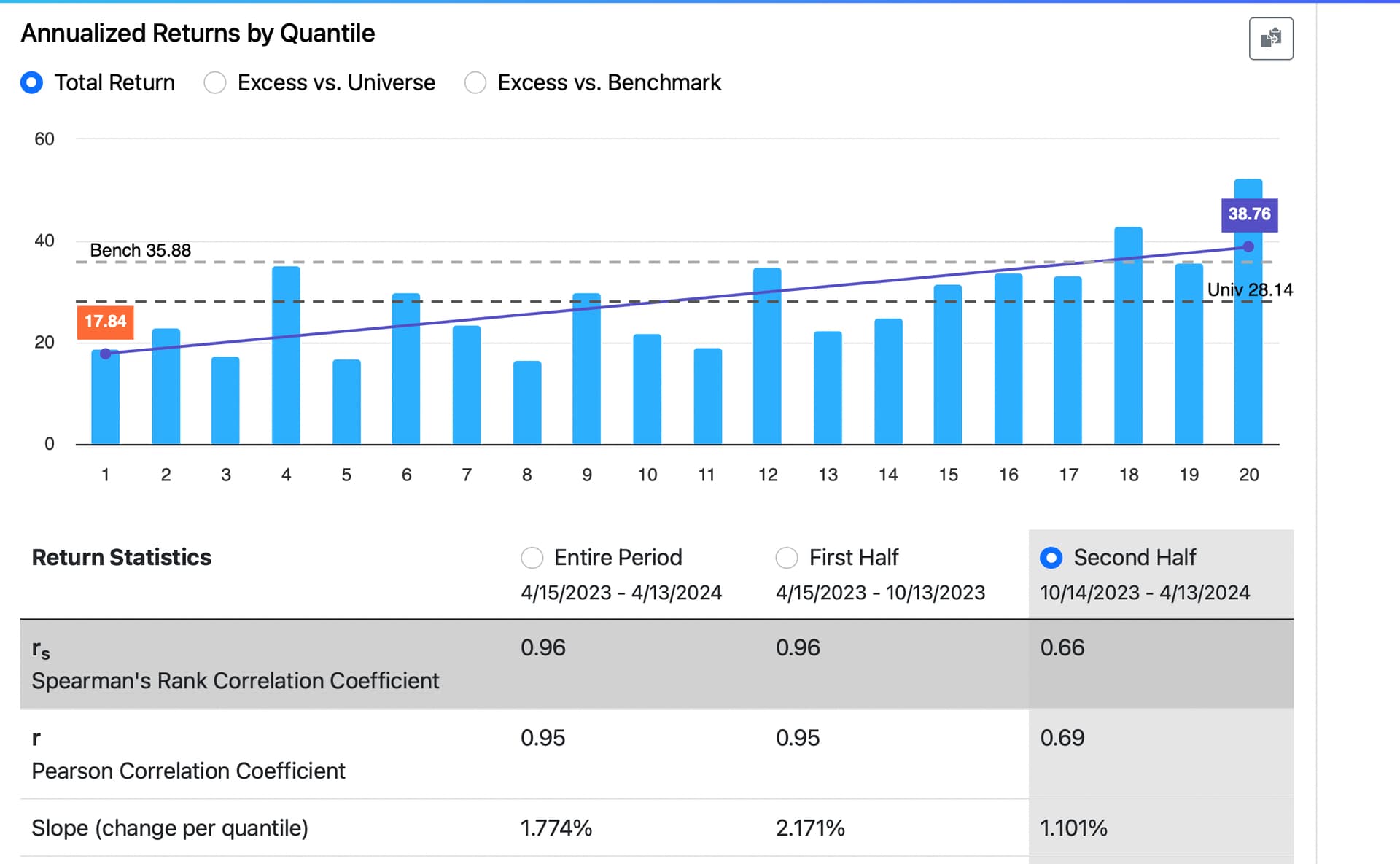
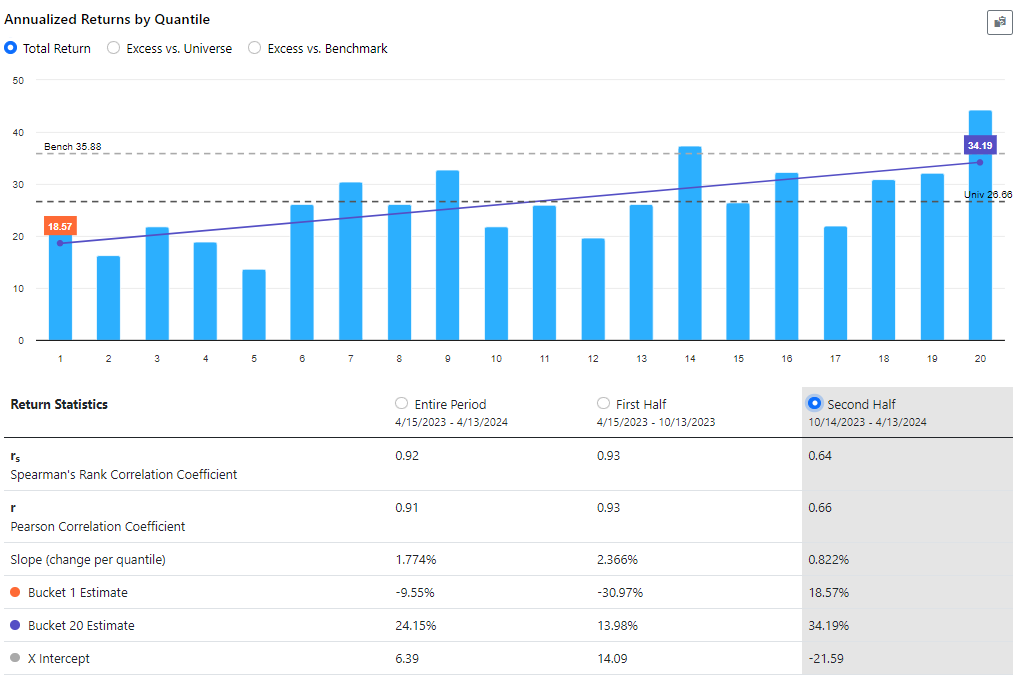
In January 2023, I developed a ranking system to the best of my abilities. After 16 months of out-of-sample testing, it appears that the ranking system is functioning quite effectively based on the slope, intercept, and correlation coefficient analyses.
However, there's one aspect causing some concern: the highest ranks (98, 99, 100) are exhibiting significantly lower performance compared to ranks 85 to 97, despite the latter performing exceptionally well during the backtest.
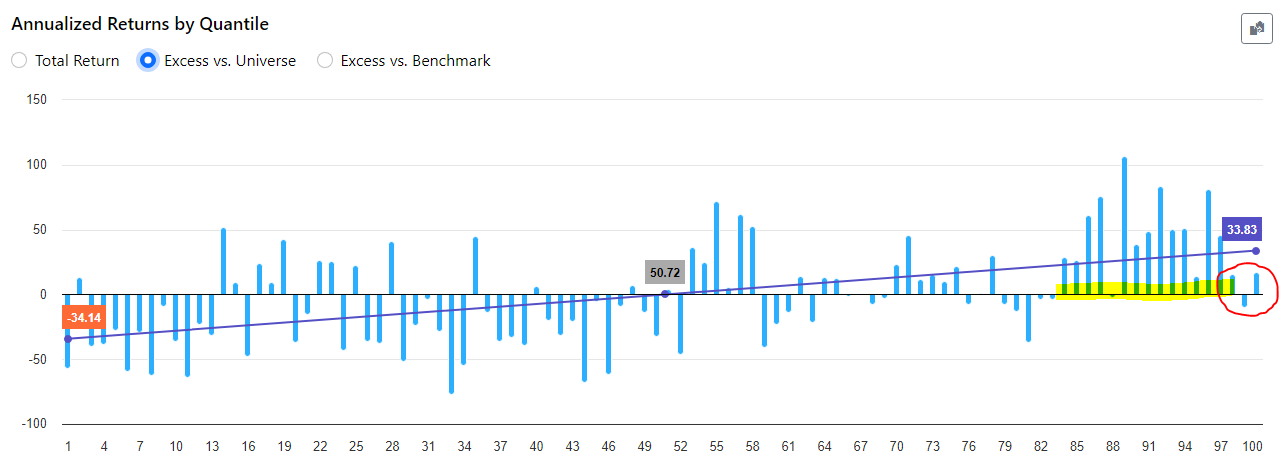
In practical terms, this mean that trading a concentrated portfolio focusing solely on the highest-ranked stocks have not been the optimal strategy. For instance, a portfolio with a broader selection of stocks have outperformed.
My question now is: do you view this as a temporary setback, anticipating that over time the situation will normalize with the highest-ranked stocks once again outperforming, as they did historically? Or do you have concerns about this trend? Furthermore, what steps would you take to potentially enhance the ranking system if necessary?
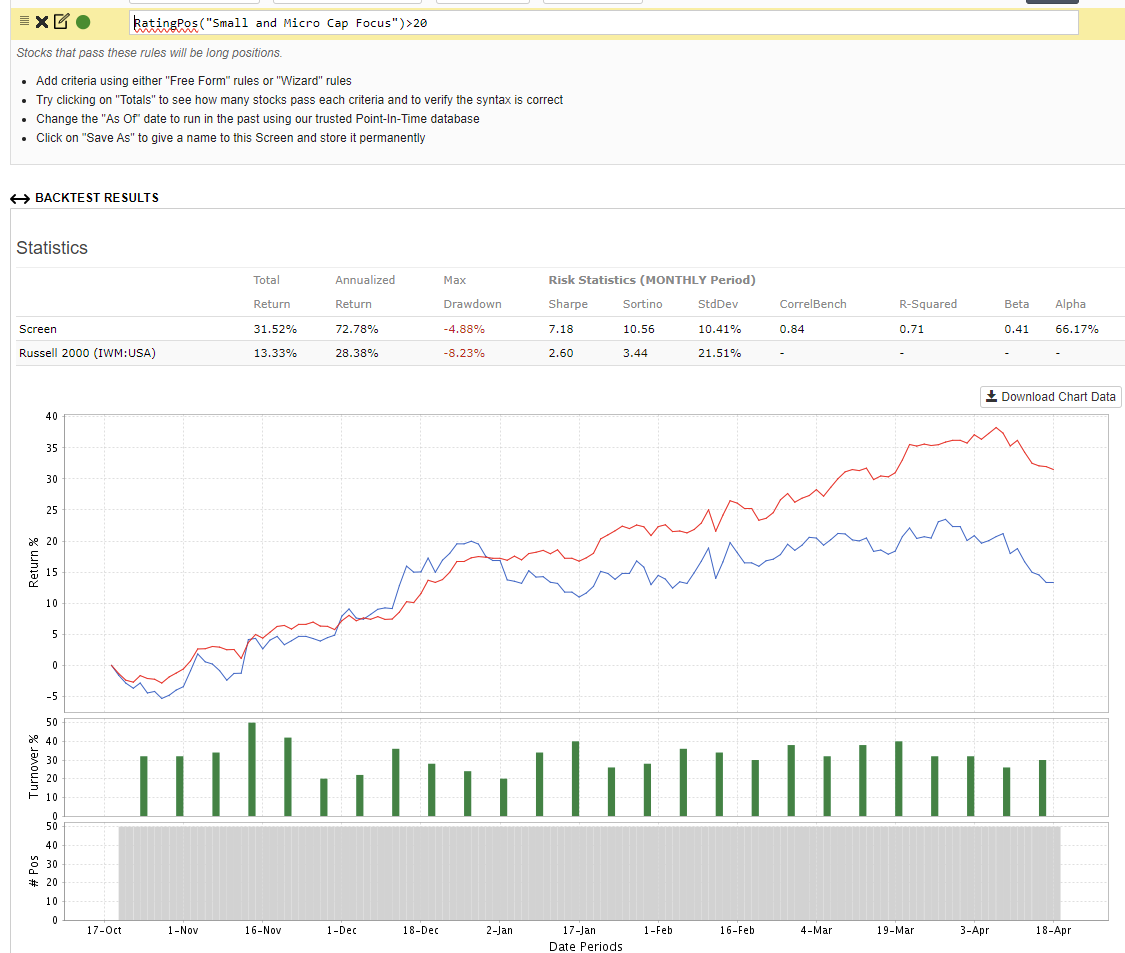
I've noticed that the portfolio123 model "Small and Micro Cap Focus" demonstrates a robust ability to achieve significant outperformance with the highest-ranked stocks, both in backtesting and out-of-sample testing. What factors do you believe contribute to this success?
I'm genuinely thrilled to engage and learn from all of you. Please don't hesitate to share your insights.
Benjamin