These are the steps I used to create my first AI Factor model. I have learned a lot while working on this project, but I am still very much an amateur so comments are appreciated.
Universe
US micro/smallcaps, but allows larger marketcaps then my current live strategies. I used some rules in the universe rules that I dont use in my current live strategies.
Close(260) > .5 //had data a year ago. To reduce NAs in data for TTM factors.
Salesq >= .5 //at least $500k in sales. eliminates SPACs, exploration companies, biotech, etc. Idea was that these are just 'noise' for the models.
In my first attempt, the top predictions included mostly stocks that were in huge draw downs. Even if they would produce good returns, I have no interest in buying those type of stocks in a weakening economy. So I added rules to eliminate stocks that I would not buy. Examples:
EPS is either positive or predicted to be positive within the next 2 qtrs using LinReg().
Avg(FRank("Pr26W%Chg",#All), FRank("Pr52W%Chg",#All)) > 30 //Remove weak stocks.
Only 425 stocks pass if I run it today but in prior years it has been double that number.
AI Factor settings
Validation is KFold, 6 folds,
Dataset period 2003-01-05 to 2024-03-09, Every week. (too many NAs before 2003 for my features)
Benchmark: Russell 2000
Features
Started with 213 features.
Removed any with high NA counts. Cutoff was 10%. Thought was that NAs are noise to the algos, but I am not sure how true this is or if my cutoff could have been higher.
Removed most 'financial strength' features because most of them show better results in single factor tests when they are BAD ie high debt. leverage, etc. Probably because there were very low interest rates during most of the backtest period. Not sure that will be true again any time soon, so eliminated them. Most were weak factors anyway. Personal choice.
Used histograms on the factor list page to remove features that had very choppy histograms with non-normal distributions. Thought was that they were too noisy for the algorithms to sort out.
Used Factor List to download the data and the target. Used a Python script to output a list of feature pairs where the correlation between the features was > .8. Used single factor rank performance tests to remove one from each pair. I later changed the correl script to also output the Spearman correlation between each feature and the target - using that would have saved a lot of time. Reason=High correlation features add no additional insight and can affect the 'importance' calculations. Is this step important? If so, then we need a tool to do this.
Have 75 features remaining at this point.
Feature Importance
I removed the 10 features with the lowest importance on the Feature Stats page. Returns were lower in both validation tests and simulations, so went back to the prior list of 75 features. We have improvements coming related to this step.
Target
Target was 3MRel up to this point. Tested different targets including 4wRel, 2MRel and 6MRel. Test method is to create a new AI Factor with the new target and run validations for the promising models. 2MRel gave the best results, so using it. Seems logical also since 2 months would be a typical holding period for me.
Preprocessor settings
Had been using ZScore with Entire Dataset, Trim 5%, Clip, Limit 2.5. Tried different ZScore settings and MinMax. No improvements, so sticking with original settings. I didn't try Rank because prior testing gave weak results.
Hyperparameter experiments
Most of the documentation on the algorithms is over my head, so all I could do is rely on ChatGPT to get some ideas on which settings are most important. Then create a 15-20 variations of the XGB and Extra Trees models that had been working best for me so see if any Hyperparameter settings improved the results. No major breakthroughs here. Once we have a gridseach tool available I look forward to redoing this step with many more combinations.
Created predictors using 2003-01-05 to 2018-01-07.
Created a ranking system which has 50% weight in the XGB model and 50% in Extra Trees. XBG and ET did well in validations and simulations. Combining them produced slightly higher returns in the simulation. No scientific reason for using both of them since they seem pretty highly correlated - just could not decide which one to use.
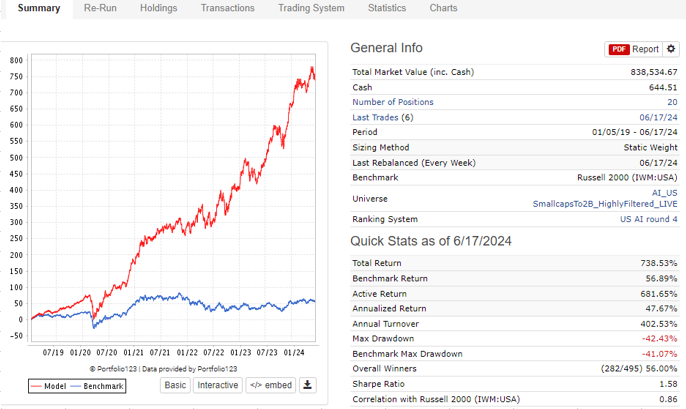
Simulation
Simulation period is 01/05/2019 - 06/17/2024. I think I could have used a 3 month gap from the end date of the predictor training, but I wanted to be conservative and not risk an data leakage.
Rebalance: Weekly
Commission: 0.005 USD Per Share
Slippage: Slippage
20 positions
'Force Positions into Universe' = Yes because my universe filters would create turnover.
Buy Rules: none
Sell rules: rank < 84 and nodays >= 15
Period: 01/05/2019 - 06/17/2024