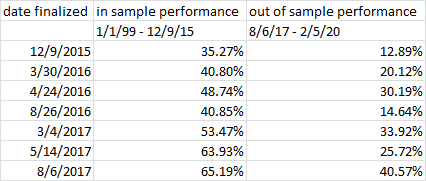
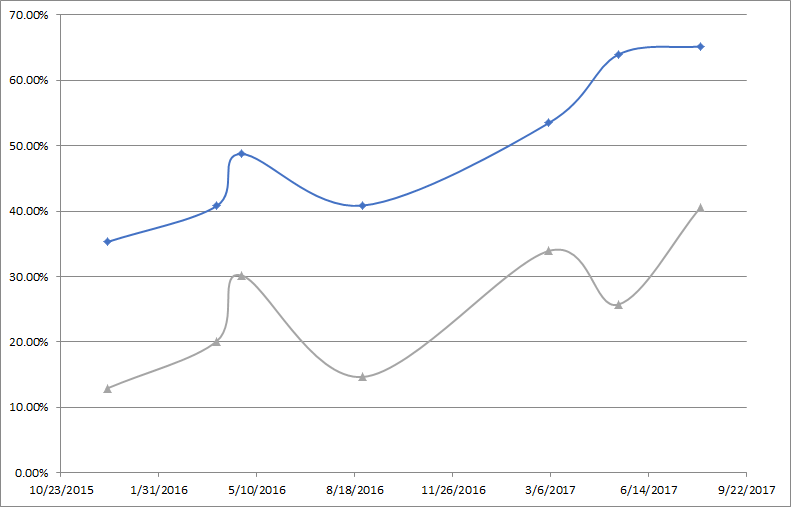
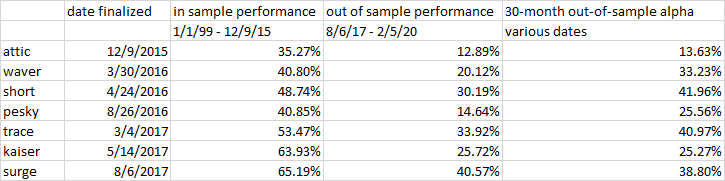
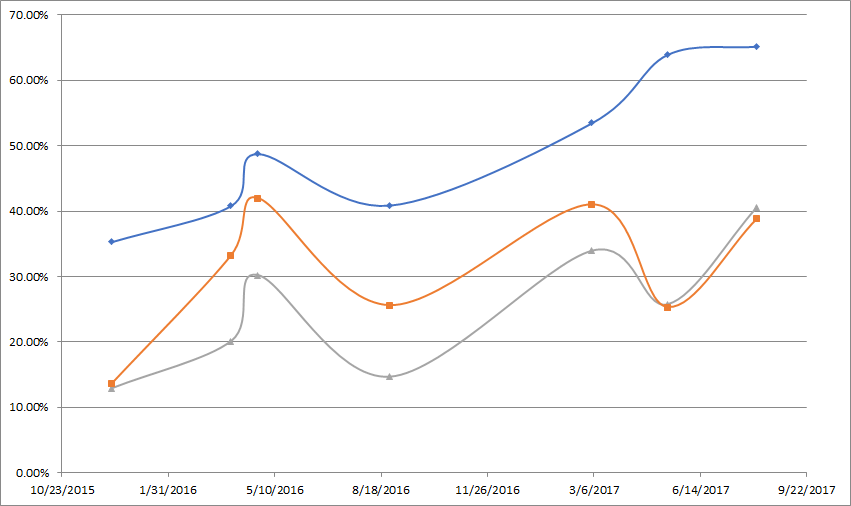
Yuval,
Thank you for sharing this.
As you expand on this and look at further data in the future, I would recommend that you consider the problems of spurious correlations in time-series data that is not detrended.
There is NOT a lot of great information available by just Googling this but here is a link that does address this somewhat:Detrending Time Series Data
"This kind of spurious correlation is especially likely to occur with time series data, where both X and Y trend upward over time because of long-run increases in population, income, prices, or other factors. When this happens, X and Y may appear to be closely related to each other when, in fact, both are growing independently of each other."
It would probably require taking a course or reading a textbook for anyone to fully understand this. It is part of a broader discussion of making time series data stationary. Pvdb was kind enough to show me my mistakes in this regard in a post a long time ago. Cyberjo was also helpful in making me understand the problems with data that is not detrended.
This is not something that is immediately obvious to everyone. And I am guessing we have all done this at some time in the past. I think I still fail to consider this potential problem at times, still.
And in fact, this is a problem that the authors make in “All That Glitters is not Gold” that James linked to in a separate thread, I think. This is one reason why the correlation of The Sharpe Ratio is positive in this article while the information ratio correlation is negative, I believe. The information ratio detrends the average returns in the numerator of the Sharpe Ratio calculation, and probably, the Sharpe Ratio regression (correlation) should have never been used in this paper. So some very smart people fail to consider this problem even in their publications, it apprears.
Summarized: for stock market data that has an upward trend we should be dealing with excess returns only for correlations. Preferably excess returns compared to the universe, but a highly correlated benchmark may suffice.
Anything else can be misleading or just plain wrong.
Not all members can afford to make that mistake with their money. Not everyone can afford to chase a spurious correlation for years until they find that a port just does not work for reasons they do not understand. Ultimately, I guess, it is a members choice as to whether they want to use excess returns (detrended data) for their correlations, or not. Or whether to make an effort to determine when this may cause a problem.
But IMHO, P123 should make an effort to take this into consideration in its product development.
Members are quick to criticize statistics in this forum. Some have even criticized the normality assumption (or central limit theorem) and the standard deviation used to calculate the correlation coefficient.
Fine. But then it logically follows that we should be even quicker to criticize bad statistics. There should not be a lot of debate about this. Especially from people who claim not like statistics in the first place.
Thank you.
-Jim