rallan - thank you for this knowledgeable post.
I have some experience with neural nets (NNs) but probably not as much as you. I have a couple of comments…
- While choosing too few or too many nodes will lead to poor results, choosing the “ideal” number will not give OOS results that are as good as backtest.
- OOS results will degrade with time. A “rule of thumb” is one year OOS for every 4 years of in-sample data optimization. Beyond that, one is pushing one’s luck. So if a model was specifically optimized over the last 5 years then one could expect it would continue to “work” for about 1.25 years assuming no regime change (such as fast dropping oil prices).
- Nodes are internal to the NN. The “ideal” number of nodes is directly related to the number of inputs. We don’t have an equivalent to “nodes” in our ports.
- Ranking factors are “inputs” not “nodes” and the quantity of factors should not be judged by the same criteria as for nodes.
- NNs are only as good as the inputs. i.e. garbage in, garbage out. This is why I gave up on NNs. If you can identify good inputs then why do you need the NN?

I think that one of the problems you and others have is that you believe that there should be a strong relationship between in-sample and out-of-sample results. Some model providers may design with this assumption in mind. But to make this general conclusion is wrong. If you truly like Marc Gerstein’s results then listen to what he has to say about backtest ![]() It is not outside the scope of this thread.
It is not outside the scope of this thread.
As for how you choose R2G ports, it looks to me as if you are choosing models that are performing the best. This can very easily lead to buy high/sell low. Just as an example, many of the smallcap models that performed exceptionally well the first six months after R2G started, subsequently flopped.
Steve
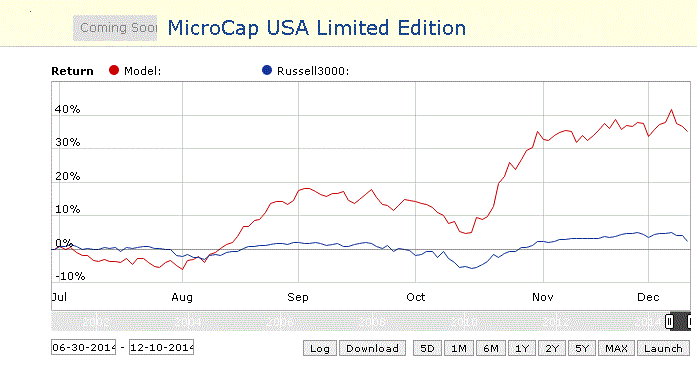
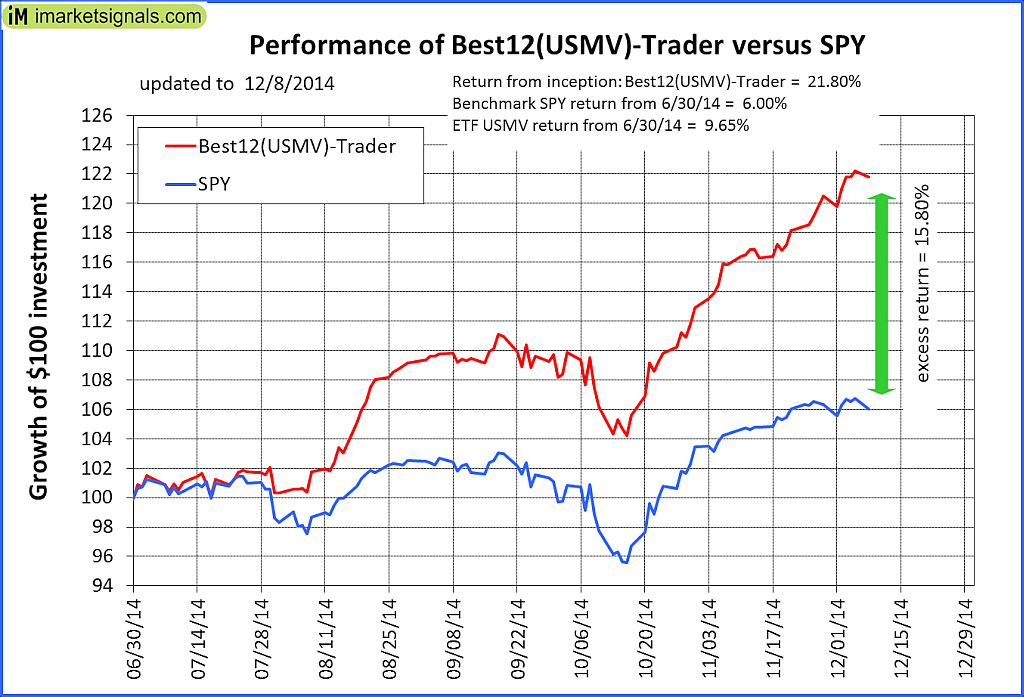{kind=link}