I do not think there can be any reasonable conclusions comparing FactSet data to CompuStat data from this small study. If anyone wants to say the study was so small that nothing can be concluded I would not disagree.
But if one is to consider the study, I thought we might get a random sample.
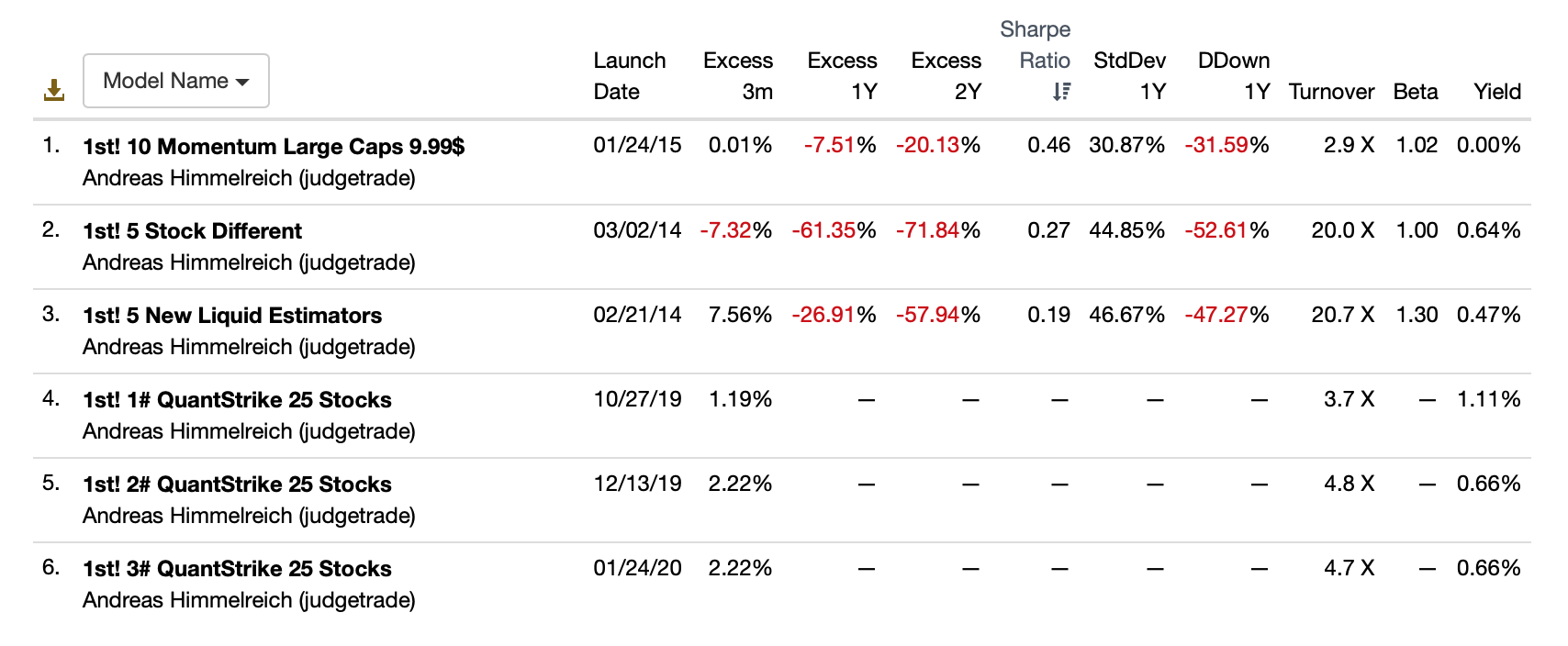
But out of 196 models with data over the last 3 months we got 10 models for the FactSet sample. Selected on this basis:
Yuval had reasons for picking these models. Many of them good reasons. It is true that these criteria could be reasonably expected to put FactSet in the best light possible. So, for whatever reasons this non-random sample of Designer Models was used for the FactSet data.
But here was the selection criteria for ports using CompuStat data:
It does not seem that the CompuStat samples are necessarily 25 stock models as is the case for the FactSet samples. This is just one way the sample are different and non-random. There is no rational reason, whatsoever, to think the samples are similar. There is some selection bias.
I am not sure if there is a difference in the quality of the FactSet and CompuStat data at this point. And if there is a difference it is possible that CompuStat data is better–if I understand Marco correctly.
I think we are forced to conclude at this point that if our models are not 25 stock models (or not similar to the selected FactSet Designer Models in general) then the results for our models could be like what was found for the CompuStat sample.
You make your own judgement on the how the CompuStat sample did.
Let me quote some of Nisser’s post The full post is above (everyone should read it in full) and I am not trying to give any false impressions by taking anything out of context. I appreciate any correction or expansions from Nisser and I will put in the whole quote or delete it if he requests this. But I think it is excellent:
So before this tread was started I would have though that this problem with non-PIT data and possibly flawed backtests could not be a factor in the underperformance of the Designer Models.
Nisser did not convince me as much as Yuval’s data changed my opinion. Certainly flawed backtests cannot be ruled out as a contributing factor to Designer Model underperformance—as Nisser suggests.
The CompuStat data performed miserably in my judgement. And this study gives me no reason to think the FactSet data is better.
Best,
Jim