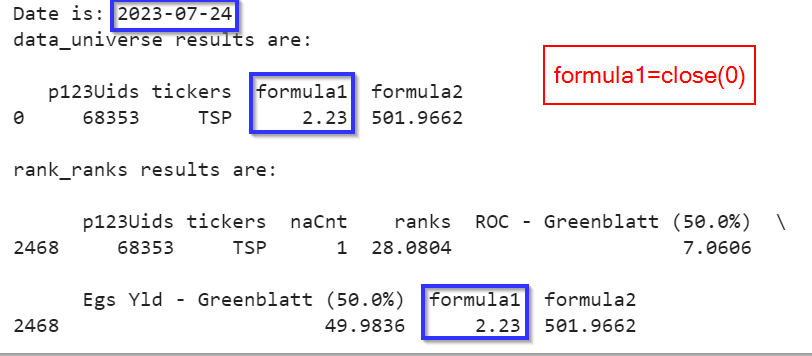
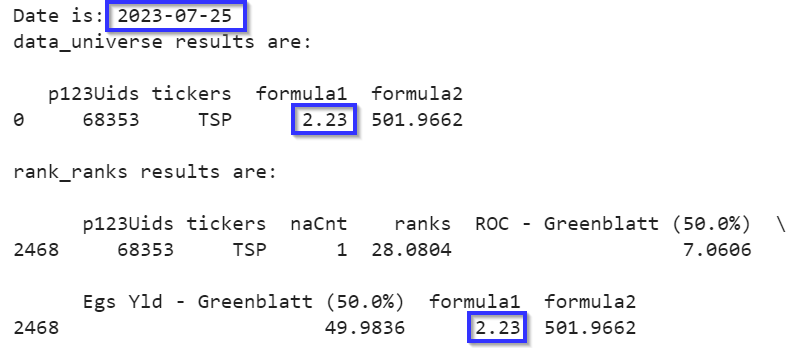
A machine learning model is developed with a csv file (or DataFrame within Python) that has feature columns and the target (often returns). Ticker and date as the index often.
P123’s DataMiner has a nice ability to get csv files for that. Nice job P123!
I cannot find a convenient DataMiner download for the day of the rebalance. Specifically all of the same factors used to train the model as columns and again ticker and date as index.
Or basically one download to rebalance with (once you got the model trained).
I am not a great programmer but so far all that I can identify that is even workable is to run each factor as a screen. Then sort each screen’s ticker column in alphabetical order to align the tickers and concatenate that for each factor.
This is one or the reasons I abandoned an XGBoost model several years ago. It is borderline, in my opinion, as to whether it is practical for me to run an XGBoost program now. But P123 would not have to change much to make it much, much easier. Maybe just explain to someone how to use DataMiner to get a simpler download. Or consider making one available if it does not already exist.
While slightly easier with the DataMiner screener there will be a large number of individual downloads, sorts and concatenations for many. And could be a cost, perhaps, with DataMiner just to rebalance an already trained model. I assume P123 set the data limits for DataMiner with the intention of avoiding large cost (it is a nice service that should be paid for by members using it so just a consideration).
So, I must be missing something as P123 is attracting and wanting to attract machine learners now. The way I described above to get the data needed (downloading multiple screens) could be streamlined and I would be surprised to find that P123 has not done this already. Any help from P123 appreciated. Personally, I cannot see any other good way to do machine learning at P123 without something like this so this could be useful information for others.
Thank you in advance,
Jim