If not what is this?
1 Like
Sorry the documentation in the (i) is nonsense, it's being re-written. It's basically just the function below for each feature vs the target. Has nothing to do with models.
Very nice!!!!! I learned something.
I have played with k-nearest neighbors but did not realize it could be used for this.
So I have never used this but it seems it could replace feature_importances. And as far as Iknow it could be better. From the documentation:
"It can be used for univariate features selection," which ties in nice with @Pitmasters link here (link it to his post): Max_features = "log2" vs the default - #2
So random forests and extra trees regressors can be improve in 2 ways as Pitmaster links to above:
-
Tuning of a relatively few hyperparameters—especially compared to XGBoost say.
-
Recursive feature elimination which could be done with this—although i am not sure if it is the optimal method to use for recursive feature eleimination. Which would be basically removing the feature with the least "mutual information" relative to the target one at a time until you find the best performing model..
Do those 2 things with an Extra TreesRegressor and you can be done in good time:
Which is a little quicker that keras III it seems, which is still running (sorry about that I did not know):

Anyway, I learned something. It seems really cool and I cannot wait to use it!!!!!
Jim
We need more actionable documentation. Not a word soup.
For this stat for example, when you copy an AI Factor with Save As you can specify to only copy the top N features by Target Information Regression. The idea being that perhaps less is more.
Another possible use case for this stat is to use it to set the weights of "Classic P123" ranking systems.
Let us know where we could be more direct and actionable in the reference which was put together hastily for the launch.
Thanks
1 Like
I don't think it replaces Feature Importance, which is model dependent. We will be exposing that soon.
2 Likes
Be careful with combining hyperparameter search with feature selection.
If you first perform feature selection using full sample and then the cross-validated hyperparameter search, then it is obvious look-ahead bias.
Its doable but tricky and increases computing time dramatically.
1 Like
Thank you. The second paper in your link makes this point also.
Along with the point that increasing max_feature leads to better results when noise variables are present.
In addition, as you know a random forest maybe be better at deciding which features to split on when noise variables are present compared to Extra Trees Regressor as random forest run slower because they spend time finding the optimal split rather than a random split.
So, I will at least try a random forest with max_features = 1.0 and not tune it as you suggest. Doing just RFE.
Starting with more features that I usually do as random forest seems to be able to handle some level of noise variables and still give good predictions..
Thank you very much. All good points!!!
Jim
I hope you don't mind my praising your choice of mutual_informatioin_regresson but feature_importances can have its problems. Specifically:
"One limitation of using feature importances directly from models like Random Forests is that highly correlated (or redundant) features might end up “splitting” their importance. This can lead to a situation where neither of the correlated features appears to be very important individually, even though they both carry significant information collectively."
And yes, mutual_information_regression can get around this:
"Mutual information, on the other hand, measures the relevance of each feature independently in terms of the information it provides about the target variable. This can sometimes provide a clearer picture, especially when features are correlated."
It will be nice to be able to use both or be able to choose. But thank you for providing mutual_information_regression!!! I will be experimenting with it for sure.
Jim
I know the beta testing is mostly to hammer away on the tool and stress test the functionality of the features, but any included "best practices" in the documentation would be welcome for those who are new to machine learning.
Yes. Would need nested cross-validation.
Extra Trees Regressor seems so robust across different hyperparameters I think I will opt out of optimizing the hyperaparmeters. Although I will probably use different defaults that described above (without changing them).
Doing just RFE now (without doing anything with the hyperaparmeters) in fact.
I hope I fully understand your post now. VERY HELPFUL!!
You are duplicating this: SelectKBest. SeletKBest at sklearn can use different metrics including mutual_information_regression. Available now as a menu dropdown at P123!!!!!
I cannot begin to tell you what a cool thing I think that is. To start, I think i will automatically remove any features with zero mutual information. Then at least try some different thresholds. I can a fine tune on individual features later. See discussion of and links to recursive feature elimination by Pitmaster here: Max_features = "log2" vs the default - #2 by pitmaster
But SelectKBest.is the same principle or more accurately it is one of the methods of recursive feature elimination discussed in Pitmaster's link.
Very nice!
Jim
This is a wonderful idea founded on solid research with a nice implementation. It iw a well-estblished idea elsewhere: e.g., SelectKBest.
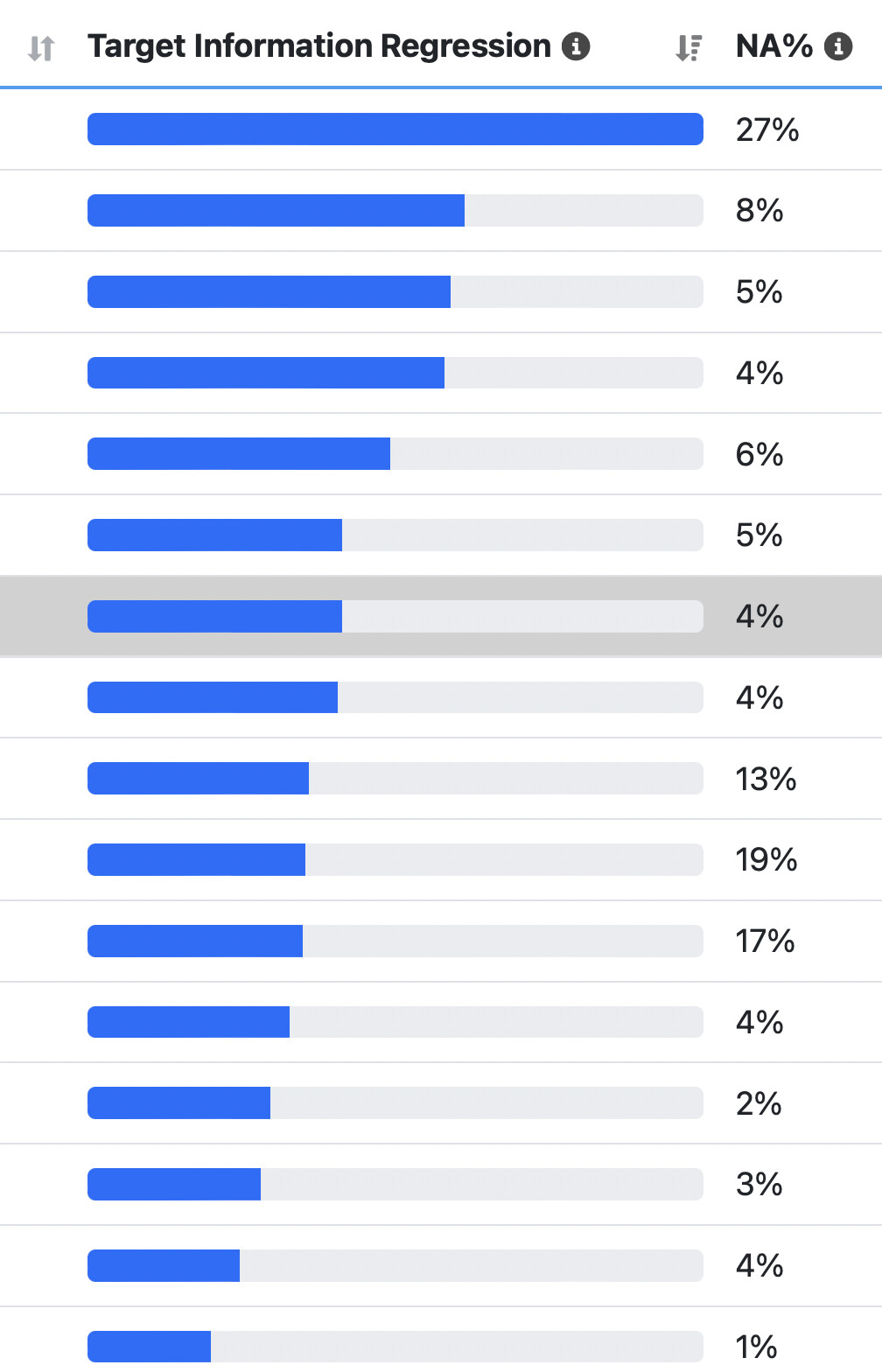
But I find some variables that are clearly, consistently helpful (like earnings estimate revisions) with top buckets that are very significantly elevated on a rank performance test. The factors are significant in a practical and statistical sense yet are zero with this metric.
Why?
-
I am fooled and features I thought were important are useless in reality.
-
The NAs create enough noise that the importance of the top buckets is masked for the mutual_information_regression metric.
I am sure it is the latter. The NAs affecting the rank performance test has been a continuous problem that has been difficult to solve. But with tree based models you have a trivial solution.
The link to the solution is here: Suggestions for improvements - #5
I note @pitmaster gave the idea a thumbs up. Without involving me you might contact Pitmaster and get his frank ideas. I am sure he would share his ideas on the topic with you. Think about it in greater depth.
To sumarize, making NAs into a negative rank completely separates them from the rest of the data, For tree models, this preserves meaningful information about NAs. A tree model can easily split out that data about NAs or include it when "deciding" whether to do a split.
If Pitmaster really the after thinking about it for a while, it could solve a lot of continuous problems that will keep popping up. Or maybe he will find a problem I have not thought of with my idea. I would be happy to join any discussion with your AI expert, Pitmaster, bobmc and others if you pursue this idea further.
For example one example of a particular feature that would benefit, implementing SelectKBest. is absolutely brilliant!!! Of course, it would be nice if it worked to separate out meaningless features with no information (as it was designed to do). I think the NAs are the problem.
Of course, i might be missing something about mutual_information_regression and if so I would love to better understand.
Jim