ChatGPT now has ChatGPT1o-mini. Which spends more time thinking. But it is dedicated to SLaTe (Scientific Language Models for Text and Code).
It will find solutions that would take me weeks to do on my own and would not be possible with Claude 3. Clause 3, however, will follow my directions better. I often end up using both—one improving on the other.
While generally my ideas, the 2 LLMs combined coded this novel ML method in a couple of weeks. I caught a couple of things I did not want it to do. For example, I changed shuffles = True to shuffle = False for a k-fold validation once. Stressful but I was able to do it:
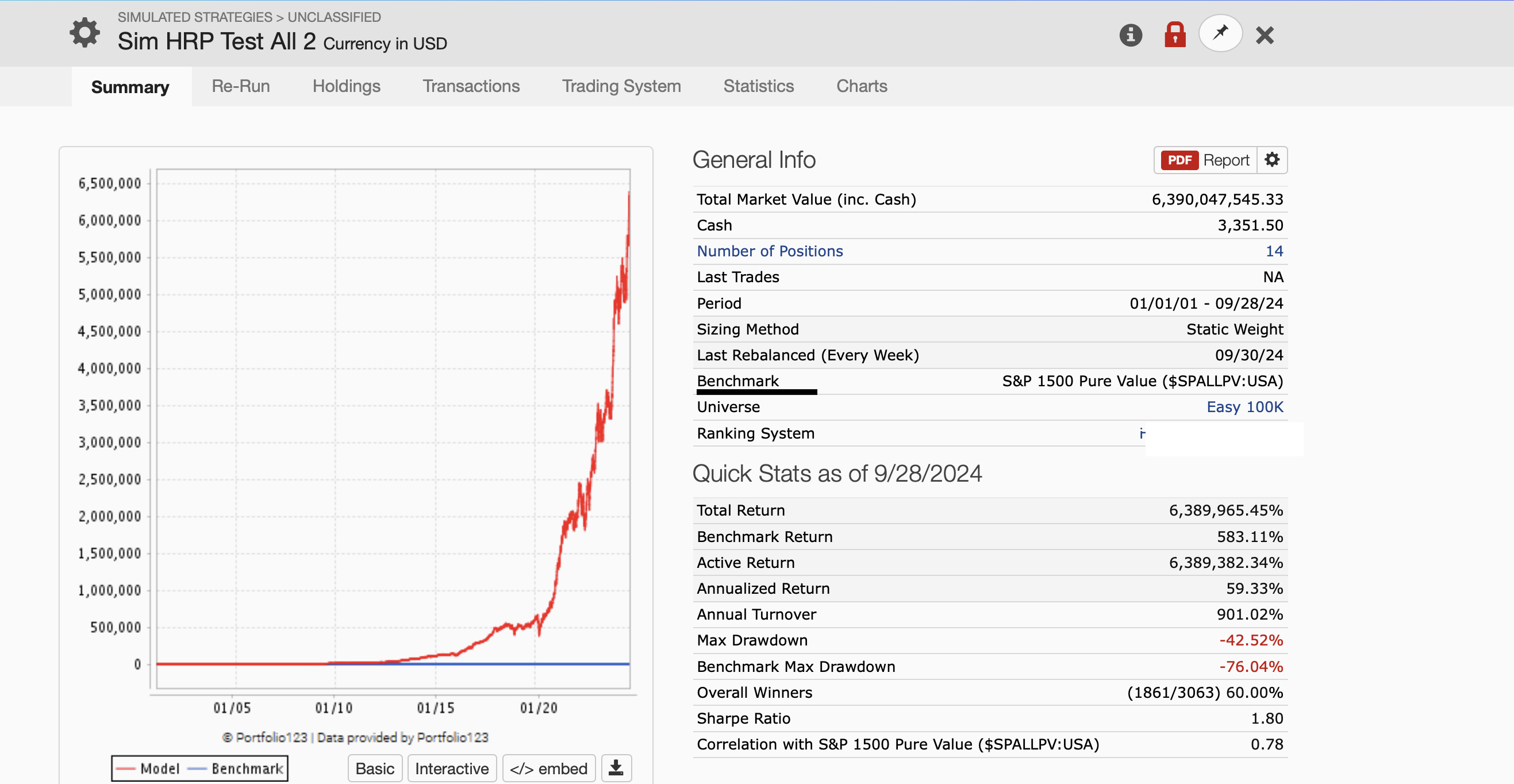
It's clearly not. It also appears to be a ranking-system-based strategy rather than an ML strategy. Perhaps Jim uploaded the wrong image by mistake, or perhaps we're misunderstanding his point.
I do indeed use P123 classic's ranking system as Yuval has noticed, but the ranking system weights were entirely determined as I described above. With machine learning and coding done by ChatGPT and Claude 3.
This is k-fold cross-validation results (to determine the weights). So it is validation results. There can be some information leakage with Sklearn's k-fold. I am aware of this and I am the one to point this out here. But nested cross-validation, walk-forward validation, and a holdout test set can tell me how big of a problem this is.
This re-test of the entire data set using k-fold cross-valdiation (shown above) was done in anticipation of funding on the first of the month. A couple of weeks to fully develop a new and novel model with ChatGPT and Claude 3 is an accurate statement I believe.
The holdout test results (2020 to now) showed an annualized return of 63%. I am not going to redo than now.
I have shared some of the things I have available to share now. No holdout test set results as I have rerun or overwritten some of that..
This is opening prices with Variable Slippage using an easy to trade universe that has some additional liquidity constraints (mild ones). The reason for naming it Easy to trade 100k is the liquidity constraints I added to the easy to trade universe.
So in this case you're using a ranking system that was optimized via ML tools in order to buy and sell stocks rather than using the ML tools themselves. Is that the case in all your models, or do you employ some models that do not use ranking systems and only use ML tools? I'm just curious. Thanks for sharing.
I have been asked to clarify my post. This is correct with a small deletion from the suggested clarification. Emphasis mine:
You posted a screenshot of a simulation that uses a ranking system rather than machine learning (and then blanked out the ranking system). Could you please revise your post to say that this simulation does not use any ML algorithms to pick stocks to buy and sell? It uses a ranking system that includes factors that a P123 ML model couldn't actually implement .
The reason the P123 classic ranking system was whited out is because it included the names of some specific ML algorithms that I did not want share. It is a P123 classic ranking system.
I did not use P123's AIFactors at any point if that is an important point to be clarified. Any ML or Python programing was done on a MacBook Pro with Jupyter Notebooks.
Thanks so much for the clarifications! Do you believe that a ranking system, if optimized by a machine learning method, is a superior method for choosing stocks to buy and sell than a machine-learning algorithm that does not specifically use a ranking system?
I have a better answer now. Here are the walk-forward backtest results of the last 10 years. So I can say, "Yes, this is completely out of sample." And without any caveats about possible information leakage with k-fold validation:
Keeping with the main point of this thread, I just told Claude 3 that instead of a hold-out test set I wanted to do this as a walk-forward backtest.
Discussion:
This is like a screen at the close with weekly rebalance and no transaction costs.
There is some drop-off in the models performance over the last 10 years. People can make their own judgement as to whether it is still okay with out-of-sample results.
But I stipulate ahead of time that I would benefit from hiring a full-time feature engineer for my little family office. And that others might do better for a variety of reasons.
I think it's mostly about different returns on the value factor at different times rather than any decay. I originally thought you might be testing in a similar way to ai_validation.
Maybe I was originally, for k-fold validation. I am open to the idea that my way was different. And as I mentioned P123 does use an embargo. I was using Sklearn's k-fold that does not have an embargo period or gap as P123 calls it.
In any case, a walk-forward backtest is better at being out-of-sample I think. I have more confidence in it anyway.
Hmmm. An LLM would not need a health plan
So yes. LLMs and maybe opening a textbook on finance this year (it has been too long) are good practical suggestions!!!
Jim, I'm a bit confused by this sentence. Do you mean that in python you are implementing factors that aren't computable with-in p123? If so, you must be then importing them as stock factors that are then used by the p123 ranking system.
Or do you mean that you're using some novel cross-validation/walk-forward/linear ML algorithms that aren't currently supported by p123's ML features? I feel like you mean the latter.
The factors I use are almost without exception ones that you have used at some point. E.g. EBITDA/EV. I haven’t been focused on feature engineering although I should direct more attention to it now. Now that developing ML systems has become easier for me. I don’t have to actually code now for example (as the title of this thread suggests).
The ML models I use are novel and "aren't currently supported by p123's ML " Both are unique.
No. The above is not completely out-of-sample in the way you suggest.
You make an important point, I believe.
For my presently funded ML system (not the one I am testing above and will probably fund tomorrow), I did what you are suggesting, however.
Specifically, I took a large set of common factors (including ones I had no confidence in) and did a walk-forward backtest of my entire algorithm including a method (or methods) of feature selection for each training period based only on the information that was available at the end of the training period.
So I can say my funded system was tested completely out-of-sample in the way you are suggesting. One of the reasons it has continued to perform on it was funded, would guess.
But to your question about the above system I was a little bit lazy and I did not want to pay to download features that I knew I was not going to use.
Good point and thanks for bringing it to the forum. I think it is important.
Jim, in the past I've tried a similar approach of downloading p123 rank data and writing python code using sklearn (albeit manually without using an LLM) to fit linear models to later import into p123's ranking system framework. There were two limitations of the ranking system that I had to accommodate: positive weights and static weights (i.e. fixed weights over time).
To handle the issue of p123's ranking system only supporting positive weights, I saw two possible solutions: a) only use ML algorithms that support non-negative constraints on coefficients or b) handle negative coefficients in the p123 ranking system by flipping the node from RankType="Higher" to RankType="Lower" or vice versa. So far, I've only explored option a.
As for the static ranking system weights, I only ever tried averaging model parameters estimated from my folds to come up with a static set of weights for the ranking system. This meant that simulations over the training/testing periods would be overfit to a degree -- but potentially not worse off than ranking system weights that were optimized manually over the same period. But similar to what you mentioned, results on any holdout period afterwards should be completely out-of-sample.
One alternative approach I considered, but haven't yet tried, was to build a RankingSystem using a series of Conditional nodes with 'Year' in the formula to switch between ranking system subtrees with different weights. Seemed inefficient but practical, in theory, to achieve time-varying weights.
I sometimes write a response and ask Claude 3 to correct any errors. Usually I am good. Claude 3 hated my first draft. Found it inaccurate and confusing both.
It is a difficult topic. Let me work on my response.