P123,
Dan was very helpful in giving me the code to find ranks over multiple dates using DatgaMiner in a different thread. I don’t know why but I could not have done it without his help. Full stop.
Because of Dan’s help, I now have an easy way to get the Pandas DataFrame I need to do fairly advanced machine learning. Again, thank you Dan and thank you P123. I will share a run of some data on a random forest below as an addendum—showing how helpful this was. And to encourage machine learning and the use of DataMiner at P123 (which I think may be a goal of Marco’s as part of his business model). If that is not useful for anyone please ignore it. You do not even have to read it. Sorry if that makes the post long. Maybe this is just a “use case” P123 likes to hear before addressing a member’s question. But also I think P123 wants to encourage machine learners even if it is to join P123 for the API and DataMiner. This is a promotion for P123 and not for any partially method.
So now I can train a model but I am wondering how to rebalance my system. Doing that is not hard (using a csv file and Python) but I need to download some data the day of the rebalance in order to do that.
The only way I can see to do that is by using the ScreenRun on DataMiner. And for those wanting to consider machine learning at P123 you will need to sort the tickers in alphabetical order and concatenate each screen factor for as many factors as you used to train your system. My simple question: how can I get ScreenRun in DataMiner to work so I can rebalance my system when it is fully trained?
Thank you in advance for any help with this.
My attempt that does not work no matter what I have tried so far after “Screen:.” I find no sample code on P123’s site that I can use to make it work (again, my bad for missing that but I could use some help). I guess I can try GitHub (I failed to do that so far). I simply am not smart enough to do it without some help. I assume it is an easy answer, I am just not very intelligent and could use some help:
Main:
Operation: ScreenRun
On Error: Stop # ( [Stop] | Continue )
Precision: 4 # ( [ 2 ] | 3 | 4 )
Default Settings:
Sceen:
Addendum as, I hope, something that will encourage people to sign up and use P123:
Out of bag score for a random forest using a download from DataMiner as my data: oob_score is: 0.11995483760240422. FWIW, I think this is good and suggests a random forest could work with P123 data. You could try other models. I certainly will try other models. For comparison, the system I fund has a Spearman’s Rank Correlation of 0.056 (lower than the oob score for the random forest model). Even the Spearman’s Rank Correlation is highly significant.
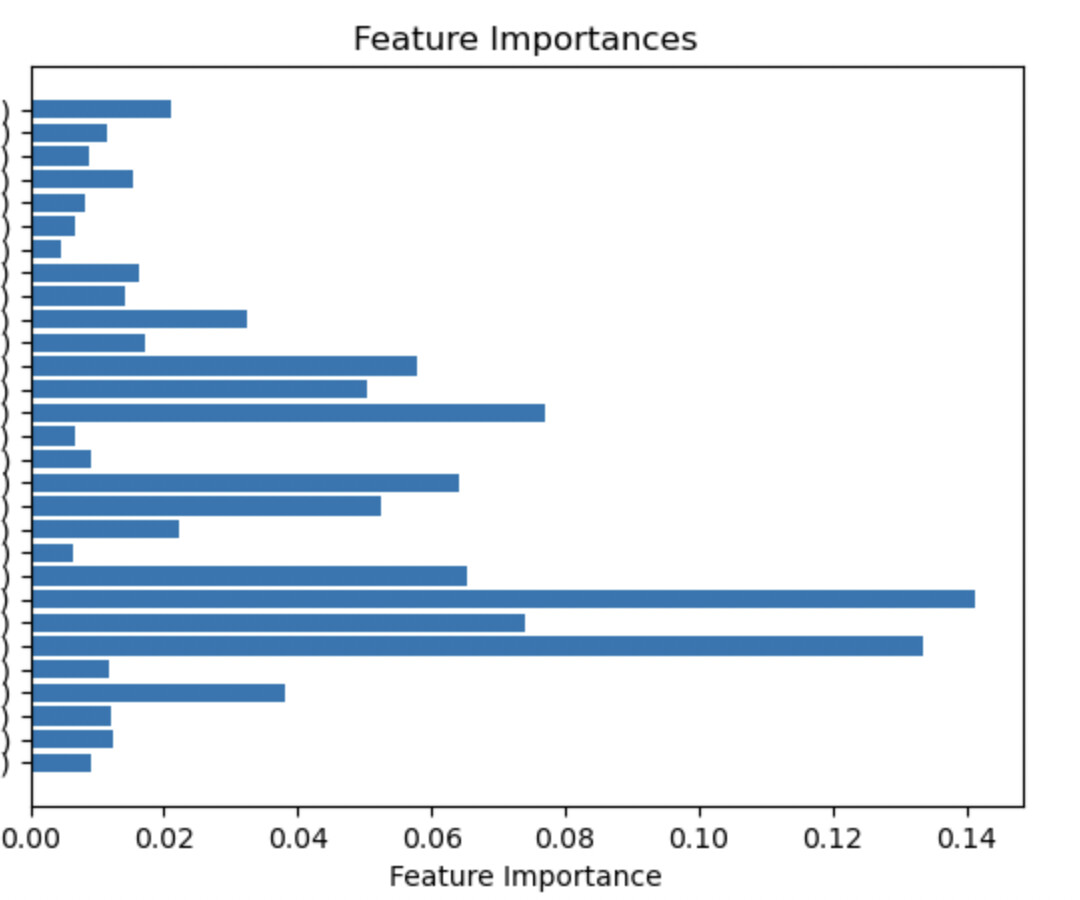
Feature Importances (I have cut of the names of the features as you will want to use your own):
Thank you in advance for any help with this.
Best,
Jim