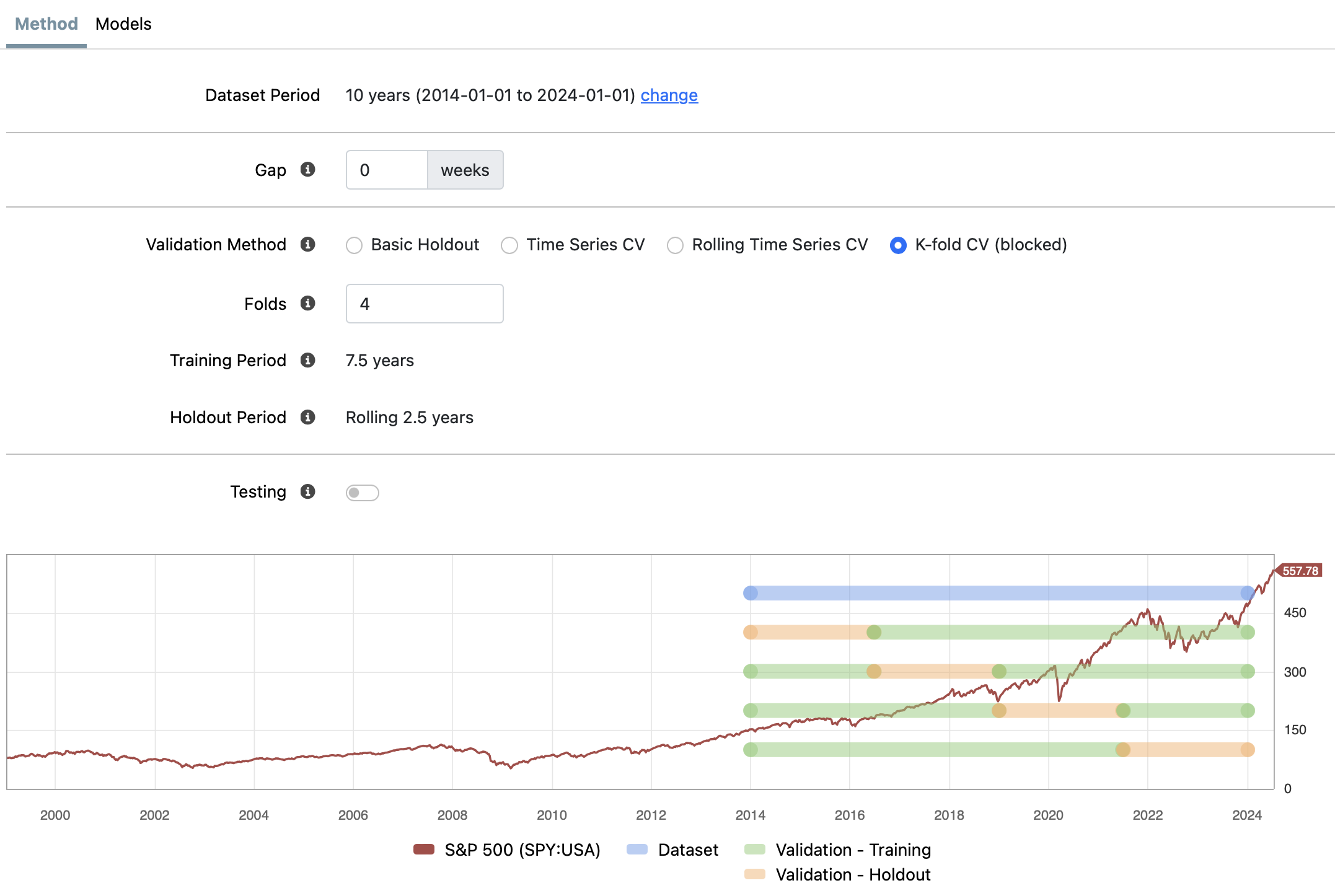
Hi all, I'm a newbie in ML and trying to understand various validation methods. I understand that regular K-fold cross-validation is not suitable for time series (due to auto-correlation) and hence the system is using a "blocked" variety of k-fold. I'm a bit puzzled by the following diagram when selecting K-fold CV (blocked). For illustration purposes I'm using no embargo period (no gap). If we want 4 folds for 10 year full data, the chart is suggesting the following from top to bottom:
Fold 1: validation period: 2014 to 2016-June, but what is the training period and why is the green bar after the validation period?
Fold 2: validation period: 2016.Jun to 2019, is the training period 2014 to 2016.Jun?
Fold 3: validation period: 2019 to 2021.Jun, is the training period 2014 to 2019?
Fold 4: validation period: 2021.Jun to 2024, is the training period 2014 to 2021.Jun?
Is this how K-fold CV blocked works? What training set is use for fold 1 or is fold 1 skipped? Why does the training period say 7.5 years for all folds even though some training data appears after the validation data? Hopefully one of you smarties can explain this better and reconcile with the visual chart. Thank you! - Sam
It is properly designed.
However, this method does not mimic how you would use the model in practice (training on past data and testing on future data). I do not use this method.
The image you attached will train 4 different models , one for each fold . The training period is in green period, predictions are performed in the orange period. The overall quantile portfolio performance is calculated concatenating the orange predictions.
You definitely need a gap. You will see better portfolio performance in the orange periods adjacent to the testing without a gap. The 1Y default is probably the minimum except in special cases like if you only short term features. Play around with 1Y gap and 2Y gap. If your 1Y gap is showing much better performance, you should use 2Y.
I would not throw this method out. The most important thing is not to validate using data you trained with. This method is not doing that. And it has a big advantage: it can use more data than the others methods, therefore it's validating in more "market cycles". It's not the dreaded look-ahead, curve fit by any stretch.
And most importantly, in my tests, the performance on the folds that train with future data is usually inline with the last fold, or the "proper time series" fold. Of course, if all your performance comes from the first folds, then you probably should not rely on it.
So, the method is using future training data to validate the past... Good point about the more data being available. Yes, a gap (embargo) would be a requirement for doing this properly. Trying to understand the type of factors or setup that won't get you in trouble using this training/validation method.
Let's say you would like to build a predictor on PEExclXorQ which varies based on market conditions, interest rates, etc. For this factor, what would be the appropriate setting for Preprocessor Scope, "Entire Dataset" or "By Date"? I'm thinking that the "Entire Dataset" will not be valid for this factor since future PEExclXorQ might be in a very different market regime than the past PEExclXorQ. So for this factor would "By Date" be more valid than "Entire Dataset"?
It would be great if there are any general principles we should apply when using this method (use future data to validate the past behavior) since it's not very straight-forward and could get us in trouble if we don't understand the implications and limitations. Thank you Marco and others in advance!