**Originally posted this in another thread when I shouldn’t have. Moving it to its own thread.
Live vs Simulated performance has been an item of interest for me recently. I am currently trying to decide if I want to continue paying for Compustat or if a FactSet license would be sufficient. A fairly difficult question to answer as it turns out.
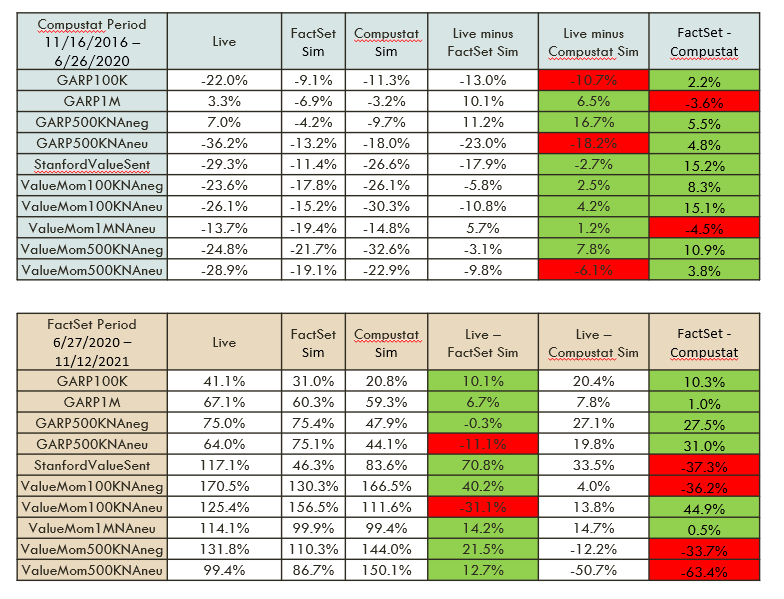
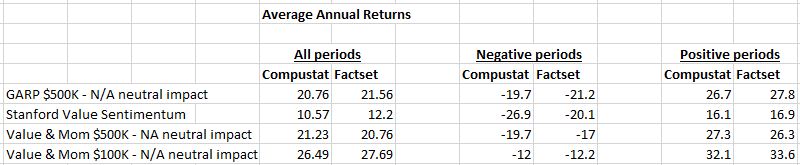
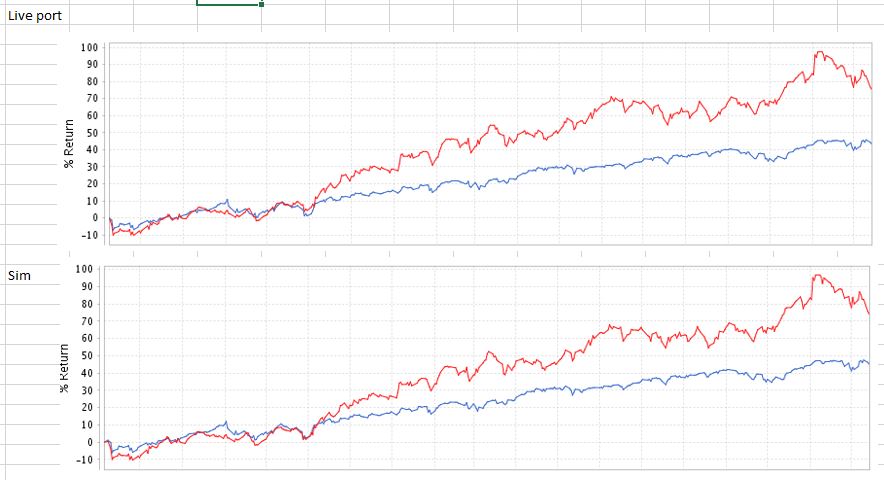
One piece of work that I did while trying to answer this question was to look at the performance of P123’s Live Portfolios versus simulated performance. We have Live performance for these strategies for the Compustat period (11/16/2016-6/26/2020) and for the FactSet period (6/26/2020 - present). I ran simulations on FactSet and Compustat for each of these periods and compared them against the Live Performance for those same periods. I have attached the results of that analysis. Note that for both periods I used Total Return over the period as the comparison metric. I used Variable Slippage and Next Close as the transaction price.
For purposes of this discussion the most important column during the Compustat period is the Live minus Compustat column, and similarly the Live minus FactSet column during the FactSet period. As you can see from the data the variance between backtested and live performance was quite significant for both time periods. However, the Live Performance tended to be better than the backtested performance unless the Ranking System used the NA Neutral setting. This was true for both periods.
Not sure exactly how to interpret this, but it does make me feel a bit better that perhaps our backtests aren’t causing us to be too overconfident.
One interesting item of note was how poorly the StanfordValueSentiment strategy performed in the FactSet backtest during FactSet time period. The Live portfolio returned 117.1% over this period while the backtest only has a return of 46.3%. Might be something that P123 staff wants to look into.
As a side note, I still haven’t decided which way to go on the Compustat vs FactSet question. Curious if anyone has any opinions on the matter.
Cheers,
Daniel